


机器学习算法-PCA降维
一、引言
在实际的数据分析问题中我们遇到的问题通常有较高维数的特征,在进行实际的数据分析的时候,我们并不会将所有的特征都用于算法的训练,而是挑选出我们认为可能对目标有影响的特征。比如在泰坦尼克号乘员生存预测的问题中我们会将姓名作为无用信息进行处理,这是我们可以从直观上比较好理解的。但是有些特征之间可能存在强相关关系,比如研究一个地区的发展状况,我们可能会选择该地区的GDP和人均消费水平这两个特征作为一个衡量指标。显然这两者之间是存在较强的相关关系,他们描述的都是该地区的经济状况,我们是否能够将他们转成一个特征呢?这样就能达到降低特征维度的特征,同时也能够避免因特征过多而产生的过拟合问题。
二、PCA降维技术
用于给数据降低维度的方法大致有三种,主成分分析法、因子分析法、独立成分分析法。由于主成分分析法在三者之中使用的比较多,这里我们只对主成分分析进行深入探讨。
2.1 PCA算法思想
在主成分分析中,通过坐标变化将原来的坐标系转化到新的坐标系。新坐标的坐标轴的选择是与原始数据有关的,第一个坐标轴选择的是原始数据中方差最大的方向,第二个坐标轴的选择和第一个坐标正交且具有最大方差,这样一直重复,直到坐标维数与数据的特征维数相同。可以发现,大部分的方差都包含在前面的几个新的坐标轴中。因此可以忽略余下的坐标轴,这样就对数据进行了一个降维。
2.2 PCA算法的计算方法
首先我们来介绍一些PCA的计算方法,在这之后我们将从数学上来对PCA算法进行分析。
PCA的计算过程如下:
Ste1:去除每维特征的均值,目的是将数据的中心移动到原点上。
Ste2:计算协方差矩阵。
Ste3:计算协方差矩阵的特征值和特征向量。
Ste4:将特征值从大到小序,找出其中最上面的N个特征向量。
Step5:将原始数据转换到上述N个特征向量构建的新的空间中去。
通过以上5个步骤,我们就能将原始数据降低到我们想要达到的维度。主成分分析的主要思想是基于方差最大、维度最小理论,因此我们可以通过计算累计贡献率来来确定N的值的大小。定义贡献率如下:
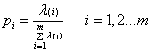
其中λ(i)表示的为第i个维度对应的特征值。我们可以设置适当的阈值,一般为0.8,如果前N个特征值的贡献率之和达到该阈值,我们就可以认为N维代表了原始数据的主要信息。
2.3 PCA技术的数学原理
在上一节中我们已经讨论了PCA的计算方法,下面我们将讨论为什么要这计算。在信号处理中认为信号具有较大的方差,而噪声具有较小的方差。信噪比表示的是信号方差与噪声方差之比。信噪比越高则表数据越好。通过坐标变换,我们可以计算在新坐标下每一个维度的方差,如果变换后某一个坐标轴上的方差很小我们就可以认为该维特征是噪声及干扰特征。因此坐标变换最好的方式就是
将变换之后N维特征的每一维方差都很大。
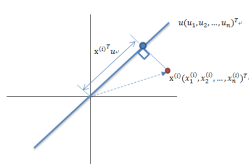
图1
如图1所示蓝色加粗线条表示坐标变化之后的某个维度,表示经过去除平均值之后的数据的第i个样本,u是该维度的方向向量,表示的是在该维度上到原点的距离。现在我们要做的就是找出u使得数据在该维度上投影的方差之和最大。由于经过去除平均值处理之后的平均值为0,容易证明它们在任何方向上的投影的平均值也为0.因此在u方向的方差之后为:
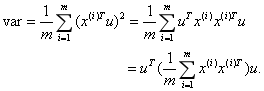
上式中的中间部分正好表示的就是样本特征的协方差矩阵如果用λ表示var,用 表示
表示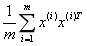 ,那么上式就能够表示成为
,那么上式就能够表示成为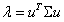 。根据特征值的的定义,λ就是
。根据特征值的的定义,λ就是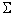 的一特征值,u就是特征向量。最佳的投影直线是特征值λ最大时对应的特征向量,依次类推。也就是说特征值的大小等价于归一化之后数据的的方差大小。因此我们只需要对协方差矩阵进行特征值分解,得到前N个特征值对应的特征向量,并且这N维新的特征是正交的。因此可以通过以下计算方式将n维原数据转化为新的N维数据:
的一特征值,u就是特征向量。最佳的投影直线是特征值λ最大时对应的特征向量,依次类推。也就是说特征值的大小等价于归一化之后数据的的方差大小。因此我们只需要对协方差矩阵进行特征值分解,得到前N个特征值对应的特征向量,并且这N维新的特征是正交的。因此可以通过以下计算方式将n维原数据转化为新的N维数据:
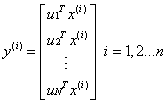
通过选取最大的前N维使得他们累计贡献率达到一定值,我们就能抛弃掉方差较小的特征,实现降维的目的。
2.4 PCA技术的python实现
定义函数PCA如下:
def pca(dataMat, minRation): meanVals = mean(dataMat, axis=0) meanRemoved = dataMat - meanVals #去除平均值 covMat = cov(meanRemoved,rowvar=0)#计算协方差矩阵 eigVals,eigVects = linalg.eig(mat(covMat))#计算特征值特征向量 eigValInd=argsort(-eigVals)#从小大到排序 ratio=0 topNfeat=1 for i in range(len(eigVals)): index=eigValInd[i] ratio=ratio+eigVals[index]#计算累计贡献率 topNfeat=i+1 if ratio>minRation:break eigValInd=eigValInd[1:topNfeat+1] redEigVects=eigVects[:,eigValInd] lowDDataMat = meanRemoved * redEigVects#将数据转化到新的维度空间 return topNfeat lowDDataMat
该函数输入为一个原始矩阵,和累计贡献率的阈值。首先去除平均值,然后利用numy库提供的cov()函数计算去除平均值之后的数据的协方差矩阵。再通过linalg.eig()函数计算该协方差矩阵的特征值和特征向量。通过argsort函数对(-eigVals)进行排序,相当于对eigVals进行逆序排序,返回排序后的索引值。其中的循环是用来计算新空间下的维数,lowData是变换到新空间下的数据。最终该函数输出为变换后的数据,以及该空间的维数topNfeat。
三、PCA技术的应用
3.1 问题描述
延续之前的回声探测的问题,即从60个不同的方向对岩石进行测试,根据回声的结果来探测的物体是岩壁还是矿井。该数据集共有208个数据,每个数据的维度为60.
3.2 PCA降维处理
我们已经在adabost使用过这个例子,这次我们对进行PCA降维之后的数据再次用adabost算法,计算测试的准确率。测试的准确率及运行时间如下表。
|
累计贡献率阈值p |
处理后的维数N |
测试的平均准确率r |
程序平均时间t |
|
0.80 |
7 |
0.27 |
1.44 |
|
0.85 |
9 |
0.26 |
1.84 |
|
0.90 |
12 |
0.28 |
2.40 |
|
0.95 |
17 |
0.30 |
3.01 |
|
0.98 |
24 |
0.21 |
5.1 |
|
1.00 |
60 |
0.28 |
5.70 |
结果发现如果把累计贡献率设置为0.9则新的空间下的维度为19维,大大降低了数据的维度。而在相同的数据集上,降维之后算法的准确率几乎没有变化。这表明降维对于数据的处理是一种有效的手段。
四、总结
本文从方差理论的角度对CA降维技术的原理进行了分析,然后通过与之前Adaboost算法结合比较在降维前后算法准确率的变化。在本例中,数据集经降维处理之后在数据集上的准确率变化不大,但是时间却大大缩短了。当然,在其的数据上我也做过一些实验,发现有些数据算法效率能够显著提升,而有些则不能。因此降维技术并不是万能的,而是需要根据实际数据集进行分析是否适合使用。

