


机器学习算法应用·KNN算法
一、问题描述
验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能。但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻。目前对验证码的识别已经有了许多方法,例如CNN,可以直接输入图片进行识别。验证码分为许多种类,本文以传统的字符验证码作为研究对象,进行图片分割成单一图片作为训练集,构架以测KNN,决策树或者朴素贝叶斯这三个算法为核心的验证码识别算法,进一步体会三个算法的特点。
二、数据准备
2.1数据说明
对于比较简单的字符验证码,为了提高运行效率。我们希望能够进行适当的降维处理,也就是寻找这些字符验证码中的最佳特征。在验证码中的数字或者字母形状、颜色都会有千变万化。根据我们人类对图像的识别过程,对于一般的字符无论它的形状、颜色怎么变化,我们都能够很快识别出来。因此推测这些不同字符之间一定存在一些不变的特征,在最好的情况下,我希望能够找出每个字符的不变特征,也许不止一个。假如不能做到这一点的话,我也希望能够最大程度的降低验证识别的维度。
数据集来源于某验证码识别比赛,共有5000个训练集,5000个测试集。在初步研究过程中,我的目标是验证每个单独的字符。然后再在接下来的过程中进一步探索,直接进行端对端的验证。
2.2 单字符样本准备
从字符的特点来看,验证码的字符非常标准,并且数字字符的垂直分布固定。可以预见,用少部分数据做样本测试和大量样本测试算法效果应该不会相差多少。为节省时间,我们样本中的100张图片作为我们算法的数据集。
2.2.1 字符分割
对样本中的100张图片进行分割,分出所有的类别,并单独存储在一个文件夹里面。

图 1.1 验证码样例
下面是详细的分割过程:
Step1:输入图片,利用python的PIL库中的convert函数将图片转化为灰度图
Step2:设置合适的阈值,对图像进行二值化。
Step3:图像去噪,噪点包括字符周围的散点和线条。得出来只包含字符的图片。
Step4:图像分割,把图片按照字符分割。字符高度一致化,为特征选取做准备。


图1.2二值化图像 图1.3去噪后的图像
2.2.2数据集整理
首先我们将生成的子图进行人工分类,将上述分割后的字符图片分别保存在相应标签的文件夹中,如图2.由于’*’不能作为文件名,因此我们以M字母来代替。

图 2
数据进行分类之后,我们需要从中选出一部分作为训练集另一部分作为测试集。将生成的字符图片存放到dataTrain和dataTest中形成训练集和测试集,对数据集进行标注之后。得到的训练集和测试集中样本如图3所示:

图 3
通过上述的三个步骤,已经将原始的数据集生成为了训练集和测试集。数据准备已经完成。训练集和测试集都有260张字符图像。接下来就是进行算法的测试了。
三、KNN识别算法
通过上一个过程,已经准备好了需要训练集和测试集。那么本节需要完成的任务就是建立以KNN算法为核心的字符图像识别算法。在建立过程中遇到的主要困难是怎样选择合适的特征作为图片的识别特征以及怎样处理这样的特征。
3.1 欧氏距离度量的KNN算法
首先,由于在数据准备过程中,将所有的图片的高度进行了一致化。因此很自然的把字符图片每一行的黑点个数,作为该图片的特征。这样每张图片就对应于一个列表。在对选出的特征不做任何处理的情况,先看看KNN分类算法的分类情况。KNN算法步骤如下:
Step1:输入训练集和测试集以及他们的标签
Step2:对于测试集中的每张图片,计算它到训练集中所有数据的距离,保存到列表
distance_Arr中。(采用的是欧式距离)
Step3:选出distance_Arr中的从小到大的前k个值并找到它们的索引,通过索引找出
相应的标签。把这k个标签中出现次数最多的标签作为该测试图片的标签。
Step4:分类出测试集所有图片的标签,与测试集标签进行对比。计算识别率。
通过上述算法过程得到的结果如下:

图 4 运行结果
然后改变k的值,做出准确率随着K值得变化情况如下:
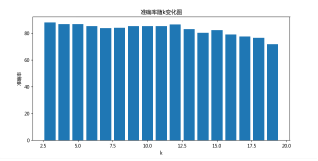
图 5 准确率随k变化情况示意图
从图中可以看出随着k的变化,算法准确率并没有多大改变。因此不能通过改变K的值来提高算法的准确率,若要提高准确率只能从特征本身特点着手。
3.2 改进度量的KNN算法
在欧式距离度量下,两个特征向量的差异表现为每个数据点上的距离的叠加,从距离度量的角度来对问题进行分析。虑到经过一系列的操作之后,图片识别问题转化为了比较两个特征向量之间的相似性问题。在上述实现过程中采用的是欧式距离,即两个向量之间的距离来作为衡量两个向量的相似性的指标。但是欧式距离不能够反映两个特征向量在局部的相似性,会损失一些信息。因此可以联想到,使用相关距离带代替欧式距离。首先利用皮尔逊相关距离来代替计算。皮尔逊相关定义如下:
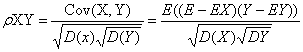
从定义中可以看出,皮尔逊相关系数表示的的两个特征向量之间的协方差与它们标准差的积的商。相关系数越接近1,表明两个特征向量的近似度越大。当皮尔逊相关系数为1是,两个向量正相关;相关系数为-1时,成负相关;而当相关系数接近0时,表明两个特征向量之间相关性较弱。为了与而欧式距离保持一致,定义皮尔逊相关距离如下:
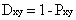
下面测试把度量改成皮尔逊相关距离之后,测试的效果。运行结果如图6所示。
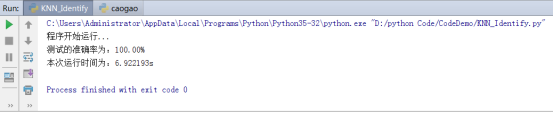
图 6.利用皮尔逊相关距离代替距离得出的结果
结果是令人感到激动和满意的,准确率较为之间已经有明显的提高,这也说明将度量改成相关距离是有效的。之后又利用余弦相关性,以及卡方值度量距离,效果均在99%以上。表明本数据集利用相关距离来度量是非常合适的,相比于欧式距离更有优势。
3.3 完整验证码的识别
做任何事情我们都不能一蹴而就,而是需要循序渐进,最终才能达到目的。同样,在验证码识别过程,我们希望能够一次性对整张图片进行处理,直接输出图片上的字符。其实所有的工作前面都已经完成了,我们需要做的就是将前面的操作进行打包批量处理。这样就能从单字符识别到整张图像识别的过渡。经过一番努力,对100张图像进行识别准确率为100%。为了测试算法的泛化性,对5000张图像进行了识别,准确率为99.2%,所用时间为1.5h。
四、结果分析与总结
实际上这是我第一次接触KNN算法,也是第一次接触真正意义上的图像识别。因此在进行整个报告的时候,花费了非常长的时间。虽然从时间意义上来讲,算法的效率并不高,但是结果出来的瞬间,还是非常激动的,这也给了我继续学习下去的信心。
在最初的时候,对于KNN的理解并不深入,而是局限在书本上给的例子上。后来经过一步步的的分析以及查阅了大量的相关资料之后,对KNN算法有了更深的理解。只有对于算法有了真正的理解之后,才能进行改造,最终成为自己的算法。本次报告遇到的最大困难在于图像的预处理、特征提取以及距离度量的选择。针对不同的问题可能适应的方法不同,在本文中使用相关系数代替欧式距离就取得了非常不错的结果。这也提醒我们在进行算法研究的时候必须对数据集的特征进行分析,从而得到适应该数据的算法。
五、程序代码
'''本模块用来将验证码分割成字符,并且储存在不同文件夹之中.使得每个数据集都能对应于一个文件夹''' #ImageSegment.py import itertools from PIL import Image import os import time ######### 图像二值化 ######################## def Get_BiImg(img): imgry=img.convert('L') table=get_table() biImg=imgry.point(table, '1') return biImg def get_table(threshold=170): table=[] for i in range(256): if i <threshold: table.append(0) else: table.append(1) return table ########### 图像去噪 #################### def Get_ClearImg(img): ##### 去除散点 for j in range(img.height): for i in range(img.width): #消除周围黑点小于3的噪点(散点) x=[i-1,i,i+1] y=[j-1,j,j+1] DCTS=itertools.product(x,y)#笛卡尔积 count=0 for p in DCTS: try:#边界点的想x,y会出现问题,代价是边界点默认为噪点 if img.getpixel(p)==0: count+=1 except: continue if count<=4:#包括自己四个点 img.putpixel((i,j),1) ###### 去除线条 for j in range(3,img.height,1): for i in range(img.width): #消除线条的噪点(认为在以该点为中心的点的y轴上至少要有四个点) x=[i] y=[j-3,j-2,j-1,j,j+1,j+2,j+3]#笛卡尔积 count=0 DCTS=itertools.product(x,y) for p in DCTS: try: if img.getpixel(p)==0: count+=1 except: continue if count<4: img.putpixel((i,j),1) clearImg=img return clearImg ######### 图像切割 ############################ def get_CopyImg(savePath,clearImg,I):#I表示输入的第I张图片 #得到每一列的黑点个数 colArr=[]#存储每一列黑点个数 rowArr=[]#存储每一行黑点个数 for i in range(clearImg.width): count=0 for j in range(20,67,1):#图片的高度为从20开始到66,共47个元素 if clearImg.getpixel((i,j))==0: count+=1 colArr.append(count) #找出字符的起始位置和结束位置 charStart=[]#存储字符起始 charEnd=[]#存储字符末尾 for k in range(len(colArr)-2): if colArr[k]==0 and colArr[k-1]!=0 and (colArr[k+1]!=0 or colArr[k+2]!=0): colArr[k]=1 if colArr[k-1]==0 and colArr[k]!=0: charStart.append(k) if colArr[k-1]!=0 and colArr[k]==0: charEnd.append(k) ####分割字符 child_ImgList=[] #folder_name='{:0>4.5s}'.format(str(I)) #os.mkdir(os.path.join(savePath,folder_name)) ##新建文件夹为每张图片保存一个文件夹的路径 for l in range(len(charStart)): #img_name='{:0>4.5s}'.format(str(l)) #child_dir=os.path.join(child_dir,img_name) child_img=clearImg.crop((charStart[l],20,charEnd[l],66)) #child_img.save(r'E:\CodeDemo\test\{0:0>4.5s}-{1:0>4.5s}.png'.format(str(I),str(l))) child_img.save(r'E:\CodeDemo\cropData\{0:0>4.5s}\{1:0>4.5s}.png'.format(str(I),str(l))) #child_img.save(child_img) child_ImgList.append(child_img)#注:png格式的照片能够更好的保真,不会产生灰色模块 return child_ImgList #批量处理图片 def BatchProcess(filePath,savePath):#输入文件夹的路径,及存储位置 pathDir=os.listdir(filePath)#pathDir存储该文件夹的所有文件名 FileNames=[]#FileName存储文件夹下的文件的完整路径 for allDir in pathDir:#allDir表示的是每个文件加后缀的文件名 child=os.path.join('%s\%s'%(filePath,allDir)) FileNames.append(child) fileCount=100 for filename in FileNames: img=Image.open(filename) biImg=Get_BiImg(img) clearImg=Get_ClearImg(biImg) get_CopyImg(savePath,clearImg,fileCount) #clearImg.save(r'C:\Users\Administrator\Desktop\DataClear\Pro_data2\{0:0>4.5s}.jpg'.format(str(fileCount))) fileCount+=1 def main(): #批量处理图片 print('开始分割图片...') t1=time.time() filePath=r'E:\CodeDemo\data2' savePath=r'E:\CodeDemo\cropData' BatchProcess(filePath,savePath) t2=time.time() #单一图片处理 #img=Image.open(r'C:\Users\Administrator\Desktop\DataClear\Pro_data1\0000.jpg') #biImg=Get_BiImg(img) #clearImg=Get_ClearImg(biImg) #get_CopyImg(clearImg) print('文件处理完毕') print('所用时间为:%fs'%(t2-t1)) if __name__=='__main__': main()
####本模块主要使用KNN算法对已经分割好的图片进行识,并测试算法的准确率,为下一个模块准备KNN分类器。 #KNN_Identify.py ''' 本模块使用的特征为字符图像垂直方向的投影之后得到的向量。 第一步:利用训练集来训练KNN算法 1:准备数据。将图片分成训练集和测试集. 2:提取特征。计算图片所有行的黑点个数,存储为rowArr;计算每一列的黑点个数,存储为colArr (由于每张图片的高度都是一样的,因此在采用rowArr作为每张图片的特征向量) 3:进行KNN算法实现,将文件训练集中的图片一一输入测试准确率 ''' import matplotlib.pyplot as plt import itertools import operator from PIL import Image from numpy import* import os import time from ImageSegment import* import matplotlib.pyplot as plt #############__图片处理__############# #给已经分类好的图片重新加上标签:输入文件夹位置,将该文件夹中所有图片加标签如:0000_1.png def labelImg(filePath): pathDir=os.listdir(filePath)#路径中的所有文件 for allDir in pathDir:##用于处理路径中的所有文件 childPath=os.path.join('%s\%s'%(filePath,allDir))#获取文件中的子路径 childDir=os.listdir(childPath)#获取子路径的文件名 count=0#表示图片的个数 for filename in childDir: path=os.path.join('%s\%s'%(childPath,filename)) img=Image.open(path) savepath=r'E:\CodeDemo\data\{0:0>4.5s}_{1:s}.png'.format(str(k),allDir) img.save(savepath)#文件另存为洗的路径之中 count+=1 #将单一图片的转化为它的rowArr特征向量和标签:输入图片的带路径名称,输出向量和标签 def get_feat_label(img_whole_name): img=Image.open(img_whole_name)#读取图片 img=Get_BiImg(img)#转化为2值图片 rowArr=[]#存储特征向量 height=img.height#高度 width=img.width#宽度 for j in range(height):#获取图片的特征 count=0#计算黑点个数 for i in range(width): if img.getpixel((i,j))==0: count+=1#如果为黑点则计数加1 rowArr.append(count) str1=img_whole_name.split('.')#分割路径 label=str1[0][-1]#获取标签 return(rowArr,label) #获取该文件夹中的所有图片组成的特征矩阵和标签向量:输入数据集路径,输出特征矩阵和标签 def get_feats(filePath): featArr=[];labels=[]#存储特征信息和标签 childDir=os.listdir(filePath)#用于存储所有图片的文件名 for allDir in childDir: img_whole_name=os.path.join('%s\%s'%(filePath,allDir))#图片包含路径的完整名称 rowArr,label=get_feat_label(img_whole_name) featArr.append(rowArr)#featArr添加一个数据 labels.append(label)#labels添加一个数据 return featArr,labels #将分类好的图片重新标记,存储到一个特定的文件夹中便于后续处理 def transterData(filePath): filePath=r'E:\CodeDemo\train'#train目录下的文件 labelImg(filePath)#将所有该目录下的文件重新标记并保存到data目录中去 ################__对特征进行分析,做出不同字符的特征图,选出合适的特征__######## #分别做出13个字符的特征图 def plotFeats():# filePath=r'E:\CodeDemo\dataTest1' featArr,labels=get_feats(filePath) x=range(len(featArr[0])) for i in range(1,len(featArr)+1): plt.subplot(3,5,i) plt.plot(x,featArr[i-1]) plt.xlabel('特征位置x') plt.ylabel('黑点个数y') plt.title(U'字符%s的特征图'%(labels[i-1])) plt.show() #特征的归一化 def standardlize(feat): standFeat=[]#存储标准化之后的值 Max=max(feat)#最大值 Min=min(feat)#最小值 for vet in feat:#对每个数据进行归一化 newVet=float((vet-Min)/(Max-Min)) standFeat.append(newVet) return standFeat #将特征划分为3块 def getNewFeat(featArr): newFeatArr=[] for feat in featArr: newfeat=[]#存储新特征 newfeat.append(sum(feat[0:int(len(feat)/3)])) newfeat.append(sum(feat[int(len(feat)/3):int(len(feat)*2/3)])) newfeat.append(sum(feat[int(len(feat)*2/3):len(feat)])) newFeatArr.append(newfeat) return newFeatArr ################__KNN分类算法__################ #计算两个数组之间的距离 def getDistance(x,y): distance=sum([(x[i]-y[i])**2 for i in range(x)])**0.5 #distance=0 #for i in range(len(x)): #distance+=(x[i]-y[i])**2#计算两点距离和 #distance=distance**0.5 return distance #j计算两个数组之间欧式距离的标准差 def getDisVar(x,y): disVar=sum([(x[i]-y[i])**2 for i in range(len(x))])**0.5#利用列表推导式,速度更快 ''' disArr=[]#距离方差 for i in range(len(x)): distance=(x[i]-y[i])**2#计算两点距离和 disArr.append(distance**0.5) disArr=array(disArr)#将距离转化为numpy数组 disVar=std(disArr) ''' return disVar #计算两个数组之间的pearson相关距离 def getPearsonDis(x,y): x=array(x);y=array(y)#把列表x,y转化为numpy矩阵 pearson=corrcoef(x,y,)#pearson矩阵 pearson=pearson[0][1]#pearson相关系数 return (1-pearson)#皮尔逊相关距离 #计算两个数组之间的卡方值 def getChi_SquDis(x,y): Chi_Squ=sum([(x[i]-y[i])**2/(y[i]+1) for i in range(len(x))]) return Chi_Squ #计算两个向量的余弦相似距离 def getCosDis(x,y): #X=sum([x[i]**2 for i in range(len(x))])**0.5#计算x的平方和 #Y=sum([y[i]**2 for i in range(len(y))])**0.5#计算y的平方和 X=0;Y=0 for i in range(len(x)): X+=x[i]**2 Y+=y[i]**2 cosDis=round(1-dot(x,y)/(X*Y)**0.5,8) return cosDis #获取标签中个数最多的那个标签 def getLabel(labels): classCount={}#创建装标签的空字典 for label in labels: if label not in classCount.keys():#如果标签不在字典里面,将该标签加入其中 classCount[label]=0 classCount[label]+=1 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) return sortedClassCount[0][0] #输入测试集特征,训练集特征,训练集标签,以及K值分类出所有测试集的标签 def classfy(testFeatArr,trainFeatArr,trainLabels,k): classLabels=[]#存储分类出的标签列表 for testFeat in testFeatArr: distance_Arr=[]#存储该图片特征到训练集中所有特征的距离 for trainFeat in trainFeatArr: distance=getDisVar(testFeat,trainFeat)#1、利用距离误差之和作为评价相似度的标准,越小越好 distance_Arr.append(distance) ##寻找distance_Arr中前k个元素的标签,把这k标签中最多的标签作为它的标签 distance_Arr=array(distance_Arr)#将列表转化为numpy数组 disIndex=argsort(distance_Arr)#储存索引距离排序的索引值 kLabels=[]#存储前K个值对应的标签 for i in range(k):#获取k个标签 kLabels.append(trainLabels[disIndex[i]]) classLabel=getLabel(kLabels)#获取可能性最大的标签 if classLabel=='M':#换成*号 classLabel='*' classLabels.append(classLabel)#将标签存放在classLabels中 return classLabels#返回分类出的测试集的标签 ##########__测试算法的准确率__############ def test(classLabels,testLabels): if len(classLabels)!=len(testLabels): print('测试标签有误!') return count=0#用于计算分类正确的标签个数 dataLen=len(classLabels)#表示标签的长度 for i in range(dataLen): if classLabels[i]==testLabels[i]: count+=1 corRate=100*count/dataLen#计算准确率 #print(count)输出正确的个数 print('测试的准确率为:{:<4.2f}%'.format(corRate)) return corRate ########__主函数__########### def main(): print('程序开始运行...') t1=time.time()#开始计时 #transferData(filePath)#将文件重新标记并保存在data目录中 ##外部操作将文件转移到dataTrain和dataTest中,形成两个训练集 trainPath=r'E:\CodeDemo\dataTrain'#训练集的位置 testPath=r'E:\CodeDemo\dataTest' trainFeatArr,trainLabels=get_feats(trainPath)#训练集特征 testFeatArr,testLabels=get_feats(testPath)#测试集特征 k=3#选择k=3 classLabels=classfy(testFeatArr,trainFeatArr,trainLabels,k) test(classLabels,testLabels)#测试算法的准确率 #plotFeats()#绘制字符的特征图 #K=range(3,20) #plt.bar(K,corRate) #plt.xlabel('k') #plt.ylabel(U'准确率') #plt.title(U'准确率随k变化图') #plt.show() #print(testLabels,'\n',classLabels) t2=time.time()#结束计时 print('本次运行时间为:%fs'%(t2-t1))#输出所用时间 if __name__=='__main__': main()
#本模块主要用于将输入的验证码,进行端对端的识别。输入单一图片,输出图片中的表达式。 #imgRecognition.py ''' 实现方法: step1:输入图片,对图片进行灰度处理,二值化 step2:对清洗的图片进行切割,找出验证码上包含字符的子图存在列表中 step3:对子图列表进行分类,输出标签,将标签列表转化为字符 step3:对标签字符串表达式进行求解,输出图片的标签、 step4:重复上述三个步骤,对数据集进行识别,计算准确率 ''' from time import*#计时 from ImageSegment import*#图片分割 from KNN_Identify import*#单个字符分类 import itertools#计数 from PIL import Image#图片操作 import os#文件路径操作 import matplotlib.pyplot as plt#绘图 from numpy import*#numpy数组 from scipy.stats import* ##############__代码区__############### #提取图片投影在垂直方向的特征 def getRowFeat(img): rowArr=[]#存储特征向量 height=img.height#高度 width=img.width#宽度 for j in range(height):#获取图片的特征 count=0#计算黑点个数 for i in range(width): if img.getpixel((i,j))==0: count+=1#如果为黑点则计数加1 rowArr.append(count) return rowArr #获取输入图片的包含字符的子图 def getCropImg(img):#输入图像,输出图像的包含子图的二维列表 cropList=[]#存储图像中包含的所有字符 biImg=Get_BiImg(img)#获取二值化图像 clearImg=Get_ClearImg(biImg)#对图像进行清理 colArr=[]#用于存储图像按照高度为20到66投影到水平方向时的列表 for i in range(clearImg.width): count=0 for j in range(20,67,1):#图片的高度为从20开始到66,共47个元素 if clearImg.getpixel((i,j))==0: count+=1 colArr.append(count) charStart=[]#存储字符起始 charEnd=[]#存储字符末尾 for k in range(len(colArr)-2):#找出所有子图的起始和终止位置 if colArr[k]==0 and colArr[k-1]!=0 and (colArr[k+1]!=0 or colArr[k+2]!=0 or colArr[k+3]!=0): colArr[k]=1#进行修补 if colArr[k-1]==0 and colArr[k]!=0: charStart.append(k) if colArr[k-1]!=0 and colArr[k]==0: charEnd.append(k) ##开始分割字符 for l in range(len(charStart)):#存储包含所有字符的列表 child_img=clearImg.crop((charStart[l],20,charEnd[l],66)) childRow=getRowFeat(child_img) cropList.append(childRow) return cropList #对一张图片中的子图进行计算返回图像完整标签 def getLabels(cropList,trainFeatArr,trainLabels,k):#提供训练集、训练集标签以及K cropLabels=classfy(cropList,trainFeatArr,trainLabels,k)#对标签进行识别 labelStr=''.join(cropLabels)#将列表转化为字符串 result=eval(labelStr)#计算标签表达式 labels=labelStr+'='+str(result)#创建标签 return labels #计算测试的准确率 def KNN_test(testPath,testLabelsPath,trainFeatArr,trainLabels,k): count=0#用于计算标签对的个数 childDir=os.listdir(testPath)#存储图片的名称 dataLen=len(childDir)#数据的总个数 f = open(testLabelsPath,"r")#读取测试集的标签 lines = f.readlines()#读取标签中的全部行 print('总共检验的数据个数为%i'%dataLen) for i in range(dataLen): print(i) filename=os.path.join(r'%s\%s'%(testPath,childDir[i])) orderNum=childDir[i][0:4] img=Image.open(filename) cropList=getCropImg(img) label=getLabels(cropList,trainFeatArr,trainLabels,k) testRow=orderNum+','+label test=lines[i].strip('\n') #print(testRow) #print(test) if testRow==test: count+=1 corRate=100*count/dataLen#计算准确率 print(count) print('测试的准确率为:{:<4.2f}%'.format(corRate)) ''' #此处用于将标签存储到txt文件中 with open("E:\CodeDemo\classLabel.txt","w") as f: for allDir in childDir: filename=os.path.join(r'%s\%s'%(testPath,allDir)) orderNum=allDir[0:4]#表示该图片的序号 img=Image.open(filename) cropList=getCropImg(img)#表示一张验证码上所有字符的垂直特征列表 label=getLabels(cropList,trainFeatArr,trainLabels,k)#获取标签 row=orderNum+','+label+'\n' f.write(row) ''' return corRate #获取标准的特征,标签。从同一个标签中的多个数据中计算出它们的特征。 #此处是按照数据量达到一定程度的时候可以把它作为标准值 def getStandFeat(filePath): standFeat=[] standLabel=[] childDir=os.listdir(filePath) for allDir in childDir:#遍历嵌套了两层文件夹的文件 standLabel.append(allDir)#标签 feat=[] childPath=os.path.join(r'%s\%s'%(filePath,allDir)) childDir=os.listdir(childPath) for allfile in childDir: filename=os.path.join(r'%s\%s'%(childPath,allfile)) rowArr,y=get_feat_label(filename) feat.append(rowArr) meanFeat=mean(feat,0)#按照列进行求平均值 standFeat.append(meanFeat) #将特征向量中的数组类型转化为列表类型 for i in range(len(standFeat)): standFeat[i]=standFeat[i].tolist() return standFeat,standLabel ###########__主函数__########## def main(): print('程序开始运行') t1=time.time() trainPath=r'E:\CodeDemo\dataTrain'#训练集的位置 testPath=r'E:\CodeDemo\data2'#测试集的位置 trainFeatArr,trainLabels=get_feats(trainPath)#训练集特征,标签 #trainFeatArr,trainLabels=getStandFeat(r'E:\CodeDemo\train') testLabelsPath=r'E:\CodeDemo\Label2.txt'#测试标签的位置 #testFeatArr,testLabels=get_feats(testPath)#测试集特征 k=3 KNN_test(testPath,testLabelsPath,trainFeatArr,trainLabels,k) t2=time.time() print('程序所用时间为%fs'%(t2-t1)) if __name__=='__main__': main()

