|
from numpy import *
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#对数据进行分类,根据阈值划分数据
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):#弱分类器的构建,基于输入的权重向量寻找最好错误率最小的分类方法
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))#设定步数,建立存储最好决策树的空字典
minError = inf #初始错误值,设为无穷大
for i in range(n):#对于数据特征的每一维度进行循环
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()#该维度的最大最小值
stepSize = (rangeMax-rangeMin)/numSteps#设定步长
for j in range(-1,int(numSteps)+1):#循环步数,阈值循环
for inequal in ['lt', 'gt']: #对于阈值我们并不知道是设定大于或者小于阈值为-1哪种效果好,因此需要对两种情况讨论,取最好的方法
threshVal = (rangeMin + float(j) * stepSize)#阈值
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0
weightedError = D.T*errArr #
#print("split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError))
if weightedError < minError:#判断错误率是否下降,若下降则更新分类字典。直到找到最好的哪个
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
return bestStump,minError,bestClasEst
def adaBoostTrainDS(dataArr,classLabels,numIt=40):#迭代次数默认为40
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #初始化权重值
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#构件简单树
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#计算alpgha,同时控制其下溢为0
bestStump['alpha'] = alpha
weakClassArr.append(bestStump) #把树存储到分类器中
#一下用于计算样本权重值
expon = multiply(-1*alpha*mat(classLabels).T,classEst) #exponent for D calc, getting messy
D = multiply(D,exp(expon)) #Calc New D for next iteration
D = D/D.sum()
#计算所有分类器的错误数
aggClassEst += alpha*classEst
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
errorRate = aggErrors.sum()/m
if errorRate == 0.0: break
return weakClassArr,aggClassEst
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])#此处在书中版本可能出现问题,需要在[i]前面加[0]
aggClassEst += classifierArr[i]['alpha']*classEst
#print(aggClassEst)
return sign(aggClassEst)
def plotROC(predStrengths, classLabels):
import matplotlib.pyplot as plt
cur = (1.0,1.0) #cursor
ySum = 0.0 #variable to calculate AUC
numPosClas = sum(array(classLabels)==1.0)
yStep = 1/float(numPosClas); xStep = 1/float(len(classLabels)-numPosClas)
sortedIndicies = predStrengths.argsort()#get sorted index, it's reverse
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
#loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0; delY = yStep;
else:
delX = xStep; delY = 0;
ySum += cur[1]
#draw line from cur to (cur[0]-delX,cur[1]-delY)
ax.plot([cur[0],cur[0]-delX],[cur[1],cur[1]-delY], c='b')
cur = (cur[0]-delX,cur[1]-delY)
ax.plot([0,1],[0,1],'b--')
plt.xlabel('False positive rate'); plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
ax.axis([0,1,0,1])
plt.show()
print("the Area Under the Curve is: ",ySum*xStep)
|

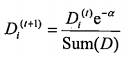

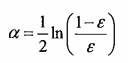
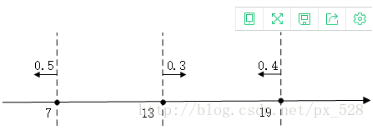
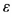 为分类器的错误率。迭代n次之后,我们就能得到n个分类器h(x)。接下来我们给每一个分类器赋予一个权重,然后将所有分类器组合在一起,这样我们就形成了一个最终的分类器H(x).这样分类出来的效果是不是类似于将数据集所在的(超)平面分成了许多个小区域呢。在理论上可以证明这样做是合理的,下面我们通过一个简单例子对adaboost算法过程进行说明。
为分类器的错误率。迭代n次之后,我们就能得到n个分类器h(x)。接下来我们给每一个分类器赋予一个权重,然后将所有分类器组合在一起,这样我们就形成了一个最终的分类器H(x).这样分类出来的效果是不是类似于将数据集所在的(超)平面分成了许多个小区域呢。在理论上可以证明这样做是合理的,下面我们通过一个简单例子对adaboost算法过程进行说明。