
数据库——多表查询
被引用的表是主表,引用外键的表是从表,两个表是主从关系
***外键是指引用另一张表的一行或多列,被引用的列应该具有主键约束或唯一约束
引入外键后,外键列只能插入参照列存在的值,参照列被参照的值不能被删除,这就保证了数据的参照完整性
建立外键是为了保证数据的完整性和统一性
**为表添加外键约束
alter table 表名 add constraint 外键名 foreign key (外键字段名) references 主表表名(主键字段名)
** 为表添加外键时需要注意的是:
(1)建立外键的表必须是InnoDB型,不能是临时表,因为mysql表中只有InnoDB类型的表才支持外键
(2)定义外键名时,不能加引号
mysql可以在建立外键时添加on delete 或 on update 子句来告诉数据库,怎样避免垃圾数据的产生,具体语法格式如下:
alter table 表名 add constraint FK_ID foreign key(外键字段名) references 主表表名(主键字段名);
[on delete{cascade|set null|no action|restrict}]
[on update{cascade|set null|no action|restrict}]
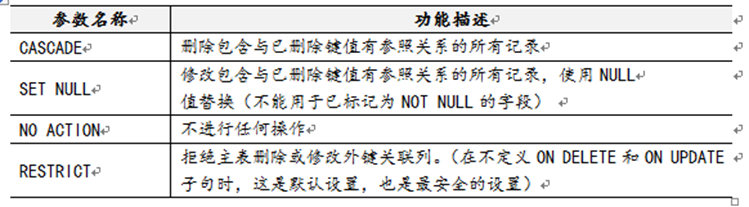
**删除外键约束(解除两个表之间的关系): alter table 表名 drop foreign key 外键名;
-------------------------------------------------------------------------------
******操作关联表
**关联关系
1.多对一(在多对一的表关系中,应该将外键建在多的一方,否则会造成数据的冗余)
2.多对多(为了实现这种关系需要定义一张中间表(成为连接表),连接表的两个外键都是可以重复的,但是两个外键之间的关系是不能重复的,所以这两个外键又是链接表的联合主键)
3.一对一(要注意主从关系,通常在从表中建立外键)
在两个具有关联的表中删除数据时,一定要先删除从表中的数据,然后再删除主表中的数据,否则会报错
**连接查询
1.交叉连接
(交叉连接返回的结果是被连接的两个表中所有数据行的笛卡儿积,也就是返回第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数)
交叉连接的语法格式:select * from 表1 cross join 表2;
需要注意的是,在一般的开发过程中这种业务需求是很少见的,一般不会使用交叉连接,而是使用具体的条件对数据进行有目的的查询。
2.内连接
(又称简单连接或自然连接,是一种常见的连接查询。内连接使用比较运算符对两个表的数据进行比较,并列出与连接条件匹配的数据行,组合成新的记录,也就是说在内连接查询中,只有满足条件的记录才能出现在查询结果中。)
select 查询字段 from 表1 [inner] join 表2 on 表1.关系字段 = 表2.关系字段 ---> inner join 用于连接两个表,on来指定连接条件,inner可以省略
语句可以起别名,如:在department表和employee表之间使用where,sql语句如下:
select employee.name,department.dname from department,employee where department.did = employee.did;
<==> select e.name,d.dname from department d join employee on d.did = e.did;
注: where子句查询结果和inner join 的查询结果是一致的,但是inner join 是内连接语句,where是条件判断语句,在where语句后可以直接添加其他条件,而inner join 语句不可以
**外连接
(只包含符合查询条件和连接条件的数据)
语法:select 所查字段 from 表1 left|right [outer] join 表2 on 表1.关系字段=表2.关系字段 where 条件 --->先执行on 符合条件在执行where
注:(1)关键字左边的表被称为左表,关键字右边的被称为右表,左右表位置不变
(2)left join (左连接):返回左表中的所有记录和右表中符合连接条件
(3)right join (右连接):返回右表中的所有记录和左表中符合连接条件
**复合条件连接查询
(就是在连接查询的过程中,通过添加过滤条件来限制查询结果,是查询结果更精确)
如:在department 表 和employee 表之间使用内连接查询,并将查询结果按照年龄从大到小进行排序,语句如下:
select employee.name, employee.age, department.dname from department join employee on department.did=employee.did order by age;
****子查询
**带in关键字的子查询
如:查询存在年龄为20岁的员工的部门,sql语句如下:
select * from department where did in (select did from employee where age=20);
(首先会执行内层子查询,得到年龄为20岁的员工部门id,然后根据部门id与外层查询的比较条件)
**带exists关键字的子查询(常用,比in关键字运行效率高)
(exists关键字后面的参数可以是任意一个子查询,这个子查询的作用相当于测试,他不会产生任何数据,只返回true或false,当返回值为true时,外层查询才会执行)
如:查询employee表中 是否存在年龄大于21岁的员工,如果存在,则查询department表中的所有记录,sql语句如下:
select * from department where exists (select did from employee where age>21);
**带any关键字的子查询
(只要满足内层查询中的任意一个比较条件,就返回一个结果作为外层查询条件)
如:使用带any关键字的子查询,查询条件满足的部门,sql语句如下:
select * from department where did>any(select did from employee);
**带all关键字的子查询
(all关键字的子查询返回的结果需同时满足所有内层查询条件)
如:使用带all关键字的子查询,查询条件满足的部门,sql语句如下:
select * from department where did > all (select did from employee);
**带比较运算符的子查询
如:使用带all关键字的子查询,查询条件满足的部门,sql语句如下:
select * from department where did =(select did from employee where name='赵四');

 浙公网安备 33010602011771号
浙公网安备 33010602011771号