向量数据库技术全景
本文深入探讨了向量数据库的基础概念、架构设计及实现技术,详细介绍了HNSW、FAISS和Milvus等关键算法和工具,旨在为高效管理和检索高维向量数据提供全面的技术指南。
关注TechLead,复旦博士,分享云服务领域全维度开发技术。拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,复旦机器人智能实验室成员,国家级大学生赛事评审专家,发表多篇SCI核心期刊学术论文,阿里云认证的资深架构师,上亿营收AI产品研发负责人。

1. 引言
1.1 什么是向量数据库

向量数据库是一种专门用于存储和查询高维向量数据的数据库系统。在现代数据处理和人工智能应用中,越来越多的数据以高维向量的形式存在,例如图像特征、文本嵌入和用户行为等。传统的关系型数据库在处理这种高维数据时效率低下,而向量数据库则通过特定的索引结构和优化算法,使得高维向量的存储、管理和检索变得更加高效。
向量数据库不仅支持大规模向量数据的存储,还提供高效的相似性搜索功能,即快速找到与查询向量最相似的若干个向量。这在推荐系统、图像识别、自然语言处理等领域具有广泛的应用。向量数据库的核心技术包括向量空间模型、距离度量、索引构建和优化检索算法等。
1.2 向量数据库的起源与发展
向量数据库的概念并不是凭空出现的,它的起源可以追溯到信息检索和机器学习领域中的向量空间模型(Vector Space Model, VSM)。向量空间模型是一种用于信息检索的数学模型,它将文档和查询都表示为向量,通过计算向量之间的相似性来进行检索。这一模型在20世纪60年代由Gerard Salton提出,为向量数据库的发展奠定了理论基础。
随着计算机技术的发展,尤其是存储和计算能力的提升,高维数据处理成为可能。20世纪90年代,随着大规模数据集和复杂算法的出现,研究者们开始探索如何高效地存储和查询这些高维数据。2000年代,随着机器学习和深度学习的兴起,向量数据的需求急剧增加。例如,图像识别中的卷积神经网络(CNN)和自然语言处理中的词嵌入(Word Embeddings)都产生了大量的高维向量数据,这些数据需要专门的存储和处理技术。
近年来,向量数据库的发展进入了快车道,得益于以下几个方面的推动:
- 硬件技术的进步:包括大规模存储设备、GPU和分布式计算技术的发展,使得处理海量高维数据成为可能。
- 算法的优化:新的索引结构和检索算法(如HNSW、ANNOY、FAISS等)显著提高了向量数据的检索效率。
- 开源社区的推动:许多优秀的开源项目,如Milvus、Elasticsearch的向量搜索插件等,加速了向量数据库的普及和应用。
总的来说,向量数据库的发展是一个多领域交叉、持续创新的过程。从最初的信息检索模型,到现代复杂的深度学习应用,向量数据库在数据科学、人工智能和大数据领域发挥着越来越重要的作用。通过优化向量数据的存储和检索,向量数据库为各类应用提供了高效的数据支持,推动了技术进步和商业应用的创新。
2. 向量数据库的基础概念
2.1 向量空间模型
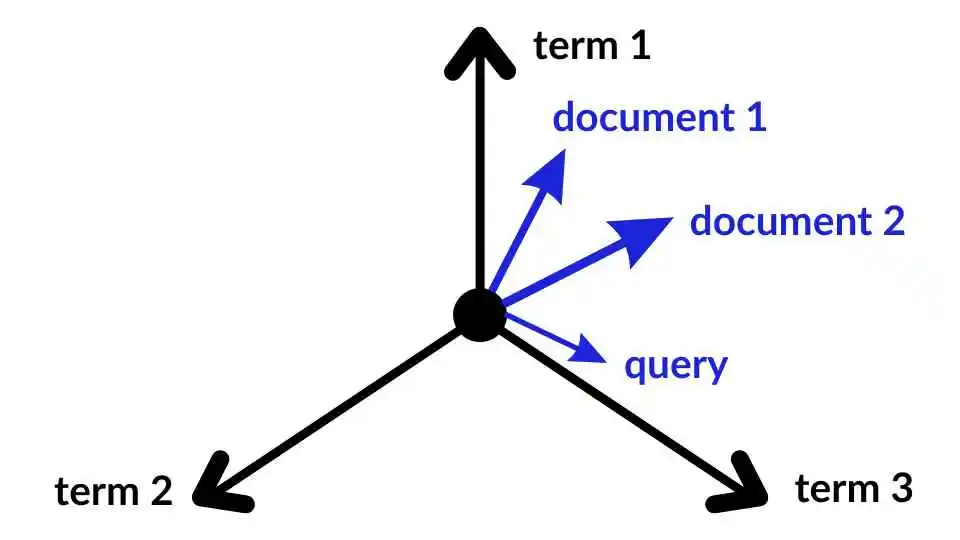
向量空间模型(Vector Space Model, VSM)是向量数据库的基础概念之一。VSM是信息检索领域中广泛使用的模型,它将文档和查询都表示为向量,利用向量之间的相似性进行检索。向量空间模型的核心思想是将文本数据转化为多维空间中的点,通过点之间的距离或夹角来衡量相似性。
在VSM中,每个文档或查询向量的维度通常表示词汇表中的一个词,向量的每个分量表示该词在文档或查询中的重要性。常见的权重计算方法包括词频-逆文档频率(TF-IDF)和词嵌入(Word Embeddings)。向量之间的相似性通常通过余弦相似度、欧氏距离或曼哈顿距离等度量方法来计算。
词频-逆文档频率(TF-IDF)
TF-IDF是一种统计方法,用于评估一个词在文档集合中的重要性。词频(TF)表示一个词在文档中出现的频率,而逆文档频率(IDF)衡量词在整个文档集合中的普遍性。TF-IDF的计算公式如下:

其中,(N)是文档集合中的文档总数,(n_t)是包含词(t)的文档数量。
词嵌入(Word Embeddings)
词嵌入是一种将词映射到低维连续向量空间的技术,使得相似词在向量空间中距离较近。常见的词嵌入方法包括Word2Vec、GloVe和FastText。词嵌入的关键在于通过神经网络模型学习词的上下文关系,从而生成具有语义信息的向量表示。这些向量表示可以用于文本分类、聚类和检索等任务。
2.2 向量检索的基本原理
向量检索是向量数据库的核心功能之一,即根据查询向量找到最相似的向量集合。向量检索的基本原理包括相似性度量、索引结构和检索算法。
相似性度量
向量相似性的度量方法有多种,常见的包括:

索引结构
为了提高向量检索的效率,向量数据库通常会构建索引结构。常见的索引结构包括:
- 倒排索引:用于稀疏向量,记录每个词在文档中的出现位置。
- 树形结构:如KD树(k-dimensional tree)和R树(R-tree),适用于低维向量的检索。
- 图结构:如HNSW(Hierarchical Navigable Small World),适用于高维向量的近似最近邻搜索。
检索算法
向量检索算法旨在快速找到与查询向量最相似的若干个向量。常见的检索算法包括:
- 暴力搜索:直接计算查询向量与数据库中所有向量的相似性,适用于小规模数据集。
- 局部敏感哈希(LSH):通过哈希函数将相似的向量映射到相同的桶中,从而减少计算量。
- 近似最近邻搜索(ANN):如FAISS(Facebook AI Similarity Search)和ANNOY(Approximate Nearest Neighbors Oh Yeah),通过构建近似索引结构,提高检索效率。
2.3 常用距离度量方法
在向量数据库中,距离度量方法是检索过程中的重要组成部分。除了余弦相似度、欧氏距离和曼哈顿距离外,还有其他几种常用的距离度量方法:

每种距离度量方法都有其适用的场景和特点,选择合适的距离度量方法对于提高向量检索的准确性和效率至关重要。
3. 向量数据库的架构
向量数据库的架构是其高效存储、管理和检索高维向量数据的基础。了解向量数据库的架构有助于我们更好地理解其工作原理,并在实际应用中进行优化。本章将深入探讨向量数据库的核心架构,包括数据存储与索引机制、查询处理与优化,以及并行与分布式计算。
3.1 数据存储与索引机制
向量数据库的存储与索引机制是其性能和效率的关键组成部分。高效的数据存储和索引可以显著提高向量检索的速度和准确性。
3.1.1 数据存储
向量数据的存储方式直接影响数据库的读取和写入性能。常见的存储方式包括:
- 行存储(Row Storage):将每个向量作为一行存储,每个分量作为一列。这种方式适用于频繁的逐行读取和写入操作。
- 列存储(Column Storage):将每个分量作为一列存储,每个向量的所有分量分散在不同的列中。这种方式适用于需要对特定维度进行聚合或筛选的操作。
- 压缩存储(Compressed Storage):通过对向量数据进行压缩存储,可以减少存储空间和I/O开销。常见的压缩技术包括稀疏向量的稀疏矩阵存储和密集向量的量化存储。
3.1.2 索引机制
索引机制是向量数据库中提升查询效率的重要手段。常见的索引结构包括:
-
倒排索引(Inverted Index):倒排索引将每个词或特征映射到包含该特征的向量ID列表。倒排索引适用于稀疏向量的相似性检索。
-
树形索引(Tree-based Index):包括KD树(k-dimensional tree)和R树(R-tree)等,适用于低维向量的精确最近邻搜索。KD树通过递归划分向量空间来构建索引,而R树则通过分层的最小包围矩形来组织向量数据。
-
图索引(Graph-based Index):如HNSW(Hierarchical Navigable Small World)和NSW(Navigable Small World)图,适用于高维向量的近似最近邻搜索。图索引通过构建小世界网络来提高检索效率,节点之间的连接表示向量之间的相似性。
3.2 查询处理与优化
查询处理与优化是向量数据库提供高效检索服务的核心。向量数据库需要处理大量的高维向量数据,优化查询处理过程对于提升系统性能至关重要。
3.2.1 查询处理流程
向量查询处理流程通常包括以下几个步骤:
- 查询解析:将用户输入的查询向量进行解析和预处理,包括向量归一化、特征选择等。
- 索引检索:根据预先构建的索引结构,快速筛选出与查询向量最相似的候选向量集合。
- 相似性计算:对候选向量集合进行相似性度量,计算查询向量与每个候选向量之间的距离或相似度。
- 结果排序:根据相似性度量结果,对候选向量进行排序,选择相似度最高的若干个向量作为最终结果。
- 结果返回:将排序后的相似向量结果返回给用户。
3.2.2 查询优化技术
为了提高查询处理效率,向量数据库通常采用多种优化技术,包括:
- 并行查询:通过并行化查询处理,可以充分利用多核CPU和分布式计算资源,加速相似性检索过程。
- 缓存机制:在内存中缓存常用的查询向量和索引结果,减少重复计算和I/O开销。
- 近似算法:采用近似最近邻搜索(ANN)算法,如LSH(Locality-Sensitive Hashing)和PQ(Product Quantization),在保证结果精度的前提下,加快检索速度。
- 剪枝策略:在索引检索和相似性计算过程中,采用剪枝策略剔除不可能的候选向量,减少计算量。
3.3 并行与分布式计算
随着数据规模的不断扩大和应用场景的复杂化,向量数据库需要支持并行和分布式计算,以提升处理能力和系统性能。
3.3.1 并行计算
并行计算通过将计算任务分解为多个子任务,并在多个处理器上同时执行,从而提高计算效率。向量数据库中的并行计算主要体现在以下几个方面:
- 并行索引构建:在构建索引时,可以将向量数据划分为多个子集,分别在多个处理器上并行构建索引。
- 并行查询处理:在进行相似性检索时,可以将查询向量分发到多个处理器,并行计算相似性度量结果。
- 并行数据处理:在数据预处理和特征提取过程中,可以并行处理不同的数据块,提高处理速度。
3.3.2 分布式计算
分布式计算通过将计算任务分布到多个独立的计算节点上进行处理,从而扩展系统的处理能力和存储容量。向量数据库中的分布式计算主要体现在以下几个方面:
- 分布式存储:将向量数据分布存储在多个节点上,提高数据的存储容量和访问速度。常见的分布式存储系统包括HDFS(Hadoop Distributed File System)和Cassandra等。
- 分布式索引:在多个节点上并行构建和维护索引结构,提高索引构建和更新效率。
- 分布式查询:将查询任务分发到多个计算节点,并行处理查询请求,汇总各节点的查询结果,提供高效的相似性检索服务。
4. 向量数据库的实现技术
向量数据库的实现技术涉及多种算法和工具,通过优化数据存储、索引构建和查询处理,实现高效的高维向量数据管理和检索。本章将深入探讨几种核心的实现技术,包括HNSW算法、FAISS、Milvus的架构与实现,帮助读者全面理解向量数据库的技术细节。
4.1 HNSW(Hierarchical Navigable Small World)算法
HNSW(Hierarchical Navigable Small World)是一种基于小世界图理论的近似最近邻搜索(ANN)算法。它通过构建一个分层的导航图结构,实现高效的高维向量相似性检索。
4.1.1 HNSW的基本原理
HNSW算法通过以下几个步骤构建和检索向量数据:
- 图构建:HNSW构建一个分层的图结构,每一层是一个稀疏的近似最近邻图。顶层包含较少的节点,每层向下节点数逐渐增加,底层包含所有的向量数据。
- 插入操作:向图中插入新向量时,从顶层开始,通过贪心搜索找到最接近的新节点的若干个邻居,然后逐层向下进行邻居更新,最终在底层插入新节点。
- 检索操作:从顶层的一个或多个入口节点开始,通过贪心搜索找到与查询向量最接近的节点,逐层向下进行精确搜索,最终在底层返回最相似的若干个向量。
4.1.2 HNSW的优势与应用
HNSW算法在检索效率和精度上具有显著优势,适用于大规模高维向量数据的近似最近邻搜索。其主要优势包括:
- 高效性:通过分层结构和贪心搜索,大幅减少了检索过程中的计算量。
- 高精度:能够在较低的计算开销下实现高精度的相似性检索。
- 灵活性:支持动态插入和删除操作,适用于不断更新的数据集。
4.2 FAISS(Facebook AI Similarity Search)
FAISS是由Facebook AI Research团队开发的开源库,用于高效的相似性搜索和密集向量聚类。它提供了多种索引和优化算法,能够处理数十亿规模的高维向量数据。
4.2.1 FAISS的核心功能
FAISS提供了多种索引结构和优化算法,主要包括:
- 扁平索引(Flat Index):适用于小规模数据集,通过暴力搜索实现精确最近邻检索。
- 倒排文件索引(IVF, Inverted File Index):将向量数据划分为若干个簇,通过簇中心进行初步筛选,提高检索效率。
- PQ(Product Quantization):将向量数据分块量化,减少存储空间和计算量。
- HNSW索引:结合了HNSW算法,提供高效的近似最近邻搜索。
4.2.2 FAISS的应用场景
FAISS适用于以下应用场景:
- 大规模图像搜索:利用卷积神经网络提取图像特征,进行高效的相似性搜索。
- 自然语言处理:对文本数据进行词嵌入或句子嵌入,进行相似性检索和聚类。
- 推荐系统:根据用户行为特征,进行相似用户或相似物品的快速检索。
4.3 Milvus的架构与实现
Milvus是一个开源的、高性能的向量数据库,旨在处理大规模高维向量数据。它采用多种先进的实现技术,以满足不同应用场景的需求。
4.3.1 Milvus的核心架构
Milvus的核心架构包括以下几个模块:
- 存储引擎:支持多种存储后端,包括本地文件系统和分布式存储系统(如HDFS、S3等)。
- 索引模块:提供多种索引结构,如IVF、PQ、HNSW等,根据数据特点和应用需求选择最优的索引策略。
- 查询引擎:实现高效的相似性检索,支持并行查询和分布式计算。
- 管理模块:提供数据导入、导出、备份和恢复等管理功能,保证数据的安全性和可用性。
4.3.2 Milvus的实现细节
Milvus的实现细节包括:
- 多种索引策略:根据数据规模和查询需求,选择适当的索引策略进行优化。
- 高效存储管理:采用内存映射文件和分层存储技术,提高数据的读写性能。
- 并行和分布式计算:支持多线程并行处理和分布式计算,提升系统的处理能力和扩展性。
- 自动调优:根据数据分布和查询负载,动态调整索引参数和查询策略,优化系统性能。
4.4 其他实现技术
除了上述几种主要技术,向量数据库还采用了其他一些实现技术,以提高系统性能和可靠性。
4.4.1 局部敏感哈希(LSH)
LSH(Locality-Sensitive Hashing)是一种近似最近邻搜索算法,通过将相似的向量映射到相同的哈希桶中,实现高效的相似性检索。LSH的主要优点是能够处理高维稀疏向量,但在处理密集向量时性能可能不如HNSW和FAISS。
4.4.2 产品量化(PQ)
PQ(Product Quantization)是一种向量量化技术,通过将向量数据分块,并对每个块进行独立的量化编码,实现数据压缩和加速检索。PQ在FAISS中得到了广泛应用,适用于大规模高维向量数据的存储和检索。
4.4.3 实时更新与动态调整
向量数据库需要支持实时数据更新和动态索引调整,以适应不断变化的数据和查询需求。实现这些功能的技术包括在线学习、增量索引更新和动态负载均衡等。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号