验证码识别全流程实战
本文将介绍验证码的历史与发展、验证码破解的历史与发展,验证码破解全流程实战。
验证码的历史与发展
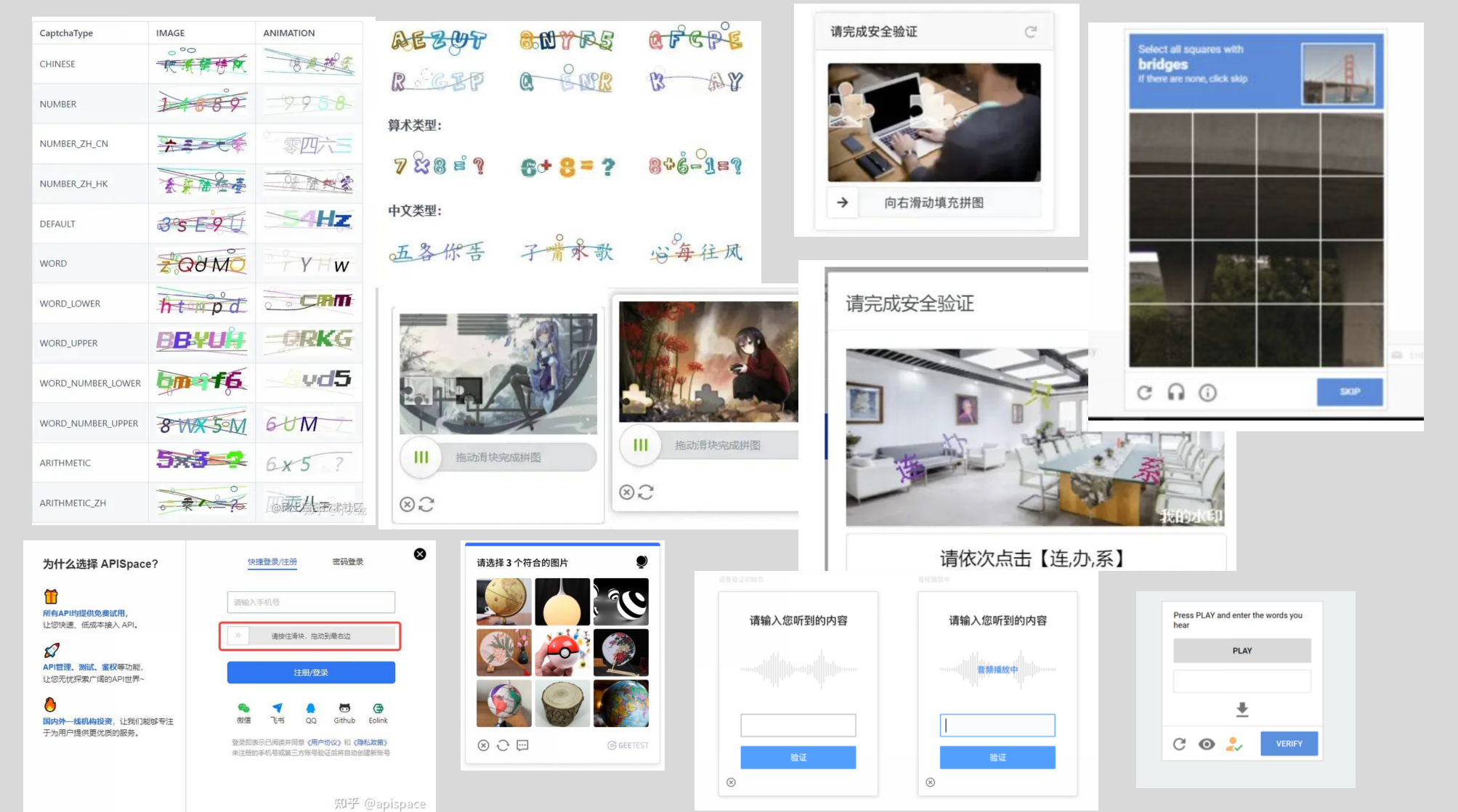
验证码,全称为“Completely Automated Public Turing test to tell Computers and Humans Apart”,即全自动区分计算机和人类的图灵测试,Captcha。早在上个世纪90年代,为了防止恶意的网络机器人行为,像邮件轰炸、暴力破解密码等,验证码应运而生。
最初的验证码是简单的文本字符,如用户只需输入一组扭曲的字母和数字。然后验证码发展到图像验证码,例如,要求用户识别哪些图片中包含某个特定对象(比如猫、狗或汽车等)。随着技术的发展,更为复杂的验证码类型出现了,例如逻辑验证码(例如,3+4=?),音频验证码(用户必须听音频然后输入听到的字符)和3D验证码(用户需要解读3D对象或者场景)。
此外,也有一些新的验证码设计,为了提高用户体验同时维护网站安全,它们需要用户进行更为人性化的操作。例如,滑动验证码让用户通过滑动解锁,点击验证码让用户点击特定的图片或文字,旋转验证码则要求用户调整图片到正确的方向。
一些大公司也开发了自己的验证码系统。例如,Google的reCAPTCHA v2引入了复杂的图像识别任务,需要用户选择包含特定物体(如汽车,交通灯)的图片;而Google的reCAPTCHA v3则摒弃了用户交互的方式,通过分析用户的行为模式来确定是人类还是机器。同样,第三方验证服务如GeeTest CAPTCHA和hCaptcha等,也为网站提供了验证服务,使得他们可以更好地防止自动化的恶意行为。
验证码破解的历史与发展
验证码破解的历史,与验证码的发展紧密相连。早期的验证码破解主要依赖于OCR(Optical Character Recognition,光学字符识别)技术,这是一种将图像中的文本转换为机器可读的字符的技术,用于识别简单的文本验证码。
然而,随着验证码的复杂性的增加,验证码破解也需要更为复杂的技术。例如,对于图像验证码,可能需要使用图像处理技术来处理噪声和扭曲。这可能包括灰度化(将图像转换为黑白),二值化(将图像进一步简化为只有黑和白两种颜色),边缘检测(识别图像中的边缘)等步骤。
对于更为复杂的验证码,例如点击验证码和旋转验证码,可能需要使用更复杂的机器视觉技术。这可能涉及到特征提取(识别图像中的重要特征),对象识别(识别特定的对象或形状),甚至深度学习(训练模型来识别复杂的模式)。
近年来,随着人工智能的发展,机器学习和深度学习等技术也被应用于验证码破解中。例如,卷积神经网络(CNN)已经被用来识别复杂的图像验证码,而递归神经网络(RNN)可以用于识别音频验证码。这些模型通过在大量的数据上进行训练,可以学习到识别验证码的复杂模式,大大提高了验证码破解的准确性和效率。
新时代高精准识别验证码的人工服务
人工验证码识别服务是一种基于人工智能或人工劳动力的验证码识别解决方案。当机器无法识别复杂的验证码时,这种服务能够提供相对高效且准确的解决方案。

2Captcha
2Captcha是一种基于人工劳动力的验证码识别服务。它提供了一个API接口,允许开发者将无法识别的验证码发送到2Captcha服务。然后2Captcha的工人会手动识别并返回结果。这种服务对处理图像验证码、文本验证码、点击类验证码、GeeTest、reCAPTCHA、FunCaptcha等复杂验证码有很高的准确率,并且提供多种编程语言的接口文档Python、PHP、Java、Go、Ruby、C++、C#。2Captcha的主要优点是其优异的精确性和灵活的API,使得开发者可以轻松集成并在不同环境中使用。
云码
云码基于图像识别技术和人工辅助提供验证码识别服务,提供在线普通图片、滑动、点选、谷歌、HCaptcha、数字计算题验证码识别服务。其对于图像类的验证码有比较好的效果,尤其是各种不同类型的图像验证码。但其对于复杂的验证码存在准确率下降和识别时间较长的情况、验证码种类跟进相较也会慢一些。
冰拓
冰拓可识别各种常见图片验证码,AI识别 + 真人识别双模式,可高效识别坐标题、计算题、字符题、滑块题、拼图题等各种图片。API支持Python、JAVA、PHP、JAVASCRIPT调用,支持按键精灵集成。对于多样化的滑块、拼图、旋转、坐标有自己独特的处理方法和提供定制服务,不支持谷歌验证码。
超级鹰
超级鹰是专业的人工打码平台,对图片数据进行精准、快速分类处理,并实时返还分类结果。支持英文数字、中文汉字、坐标选择计算等多种类型图片验证码,并且提供定制化的验证码识别服务。对于通用的验证码、传统验证码有较好的识别效果,但对于复杂验证码尚未提供更多服务。
验证码破解实战
以2Captcha破解reCAPTCHA v2为例
1. 注册2Captcha,https://cn.2captcha.com/ ,支持支付宝充值
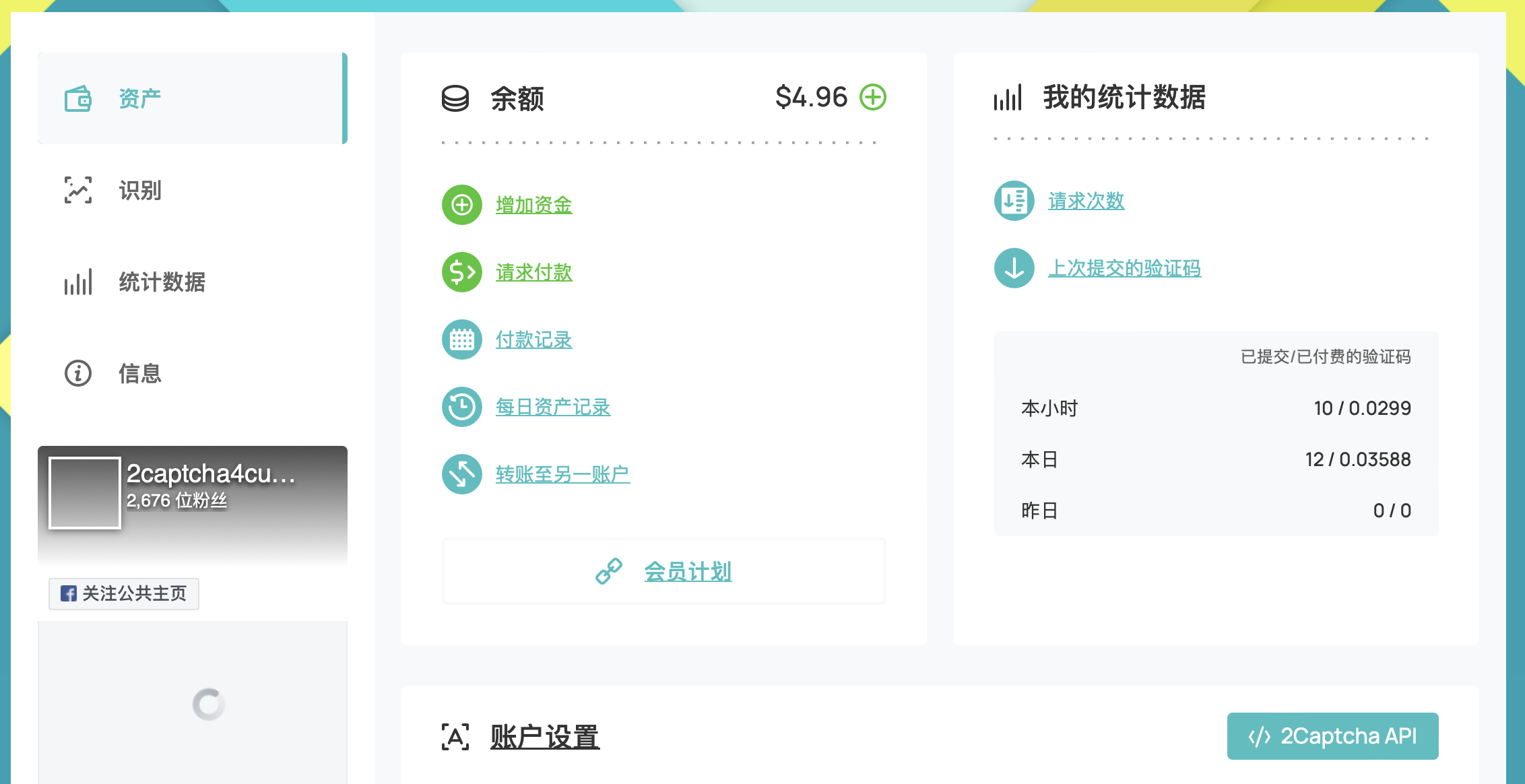
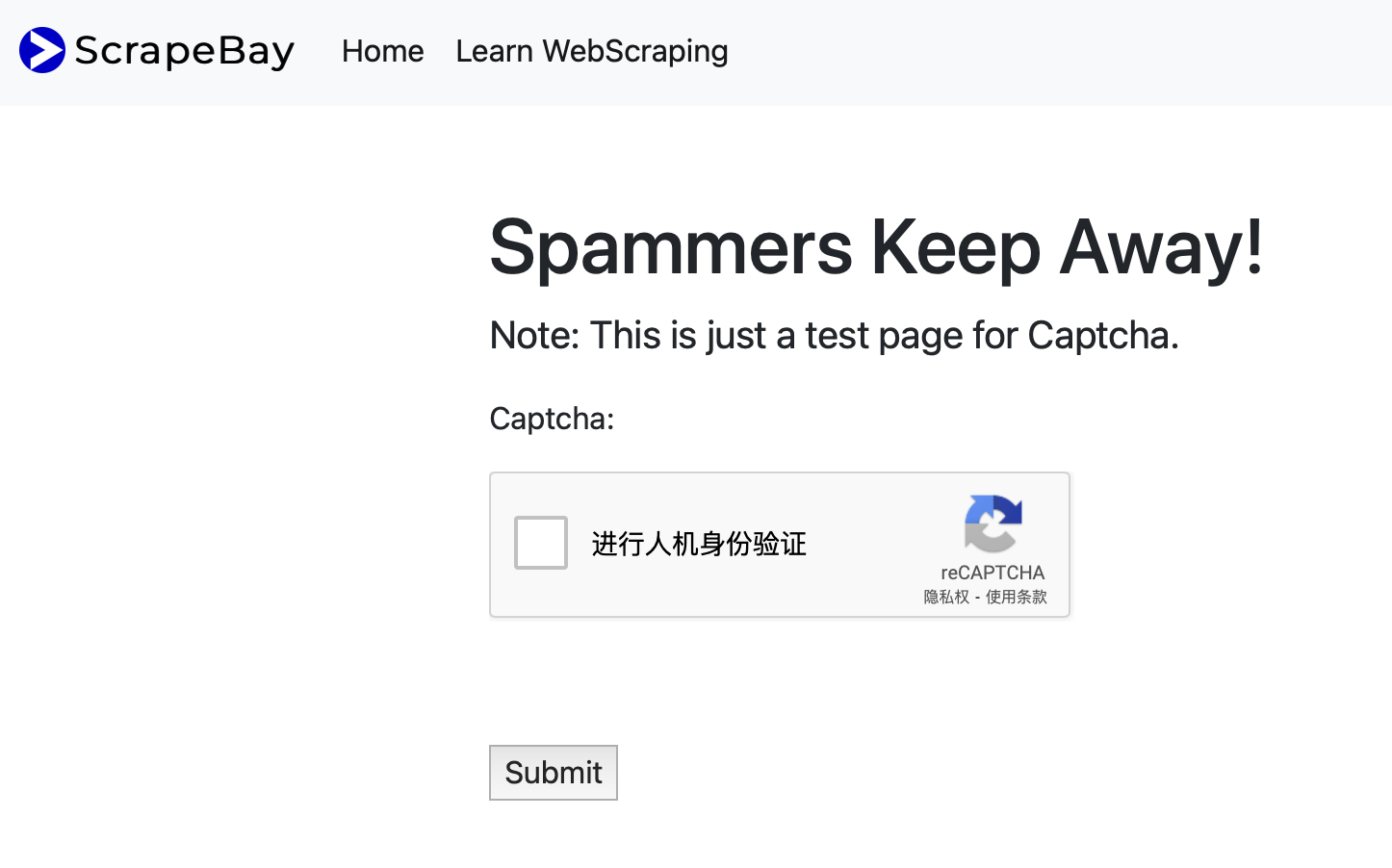
2. 目标破解https://www.scrapebay.com/spam 网站reCAPTCHA v2
3. 拿到2Captcha API_KEY
4. 拿到google sitekey
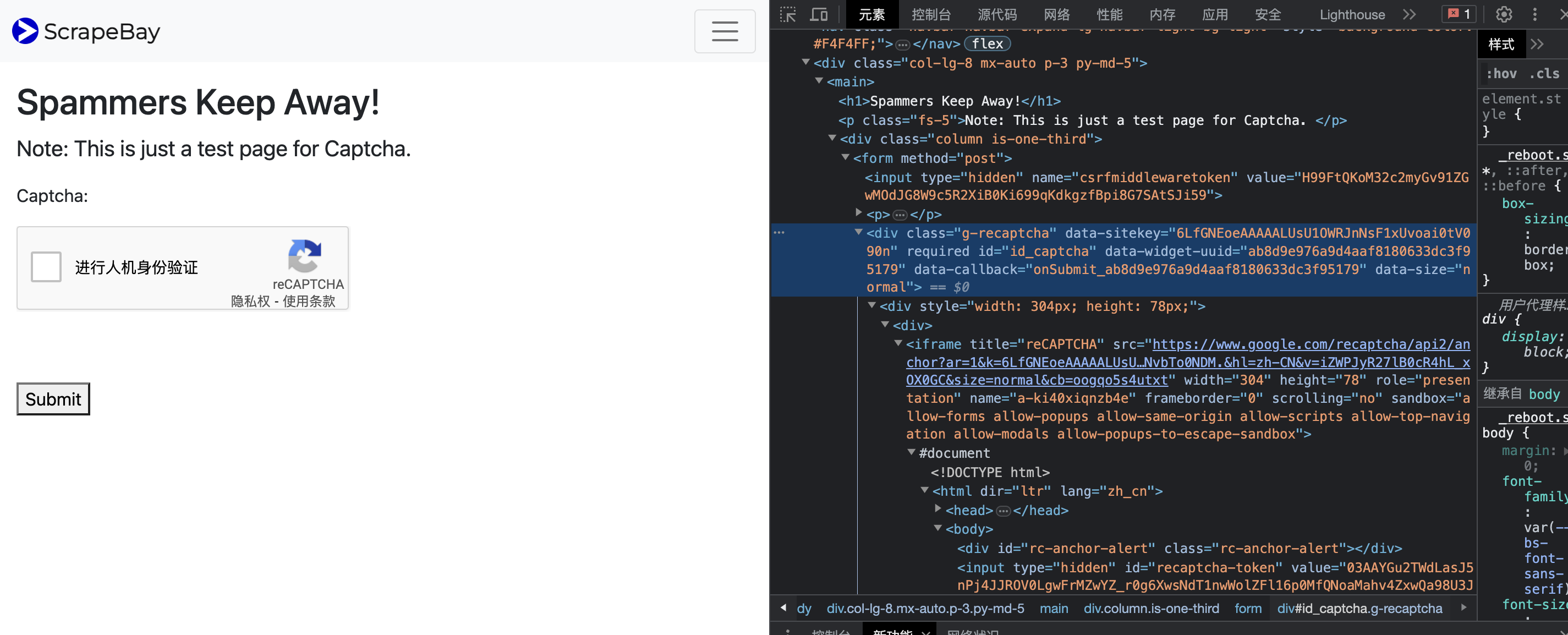

5. 破解验证码
安装2captcha-python
pip3 install 2captcha-python
破解验证码
# 导入BeautifulSoup、TwoCaptcha、requests库
from bs4 import BeautifulSoup
from twocaptcha import TwoCaptcha
import requests
# TwoCaptcha服务的API秘钥,你需要使用自己的
API_KEY = 'xxxxxxxxxxxxxx'
# 利用TwoCaptcha库,使用提供的API秘钥初始化一个solver对象,该对象可以解决ReCAPTCHA问题
solver = TwoCaptcha(API_KEY)
# 要抓取的网页的URL
url = "https://www.scrapebay.com/spam"
# 这是ReCAPTCHA的site key,可以从网页源码中找到。
site_key='6LfGNEoeAAAAALUsU1OWRJnNsF1xUvoai0tV090n'
# 这个函数用来获取CSRF token和cookies。它首先通过requests.get()获取页面内容,然后通过BeautifulSoup找到CSRF token。最后返回CSRF token和cookies。
def get_csrf_cookie(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
csrf_el = soup.select_one('[name=csrfmiddlewaretoken]')
csrf = csrf_el['value']
cokkies = response.cookies
return csrf, cokkies
# 这个函数用来解决ReCAPTCHA问题。它使用TwoCaptcha solver对象的recaptcha()方法,如果发生异常则打印错误并退出。
def solve(url,sitekey):
try:
result = solver.recaptcha(sitekey=sitekey, url=url)
except Exception as e:
print(e)
exit()
return result
# 首先通过get_csrf_cookie(url)获取CSRF token和cookies,然后通过solve(url,site_key)解决ReCAPTCHA问题,获得ReCAPTCHA的验证码结果
def main():
csrf,cokkies = get_csrf_cookie(url)
print("csrf:",csrf)
print("cokkies:",cokkies)
result = solve(url,site_key)
print("captcha:",result)
if __name__ == "__main__":
main()
运行结果:

6. 获得验证码后的页面数据
包含破解验证码的全部代码如下:
# 导入BeautifulSoup、TwoCaptcha、requests库
from bs4 import BeautifulSoup
from twocaptcha import TwoCaptcha
import requests
# 2Captcha服务的API秘钥,你需要使用自己的
API_KEY = 'xxxxxxxxxxxxxx'
# 利用TwoCaptcha库,使用提供的API秘钥初始化一个solver对象,该对象可以解决ReCAPTCHA问题
solver = TwoCaptcha(API_KEY)
# 要抓取的网页的URL
url = "https://www.scrapebay.com/spam"
# 这是ReCAPTCHA的site key,可以从网页源码中找到。
site_key='6LfGNEoeAAAAALUsU1OWRJnNsF1xUvoai0tV090n'
# 这个函数用来获取CSRF token和cookies。它首先通过requests.get()获取页面内容,然后通过BeautifulSoup找到CSRF token。最后返回CSRF token和cookies。
def get_csrf_cookie(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
csrf_el = soup.select_one('[name=csrfmiddlewaretoken]')
csrf = csrf_el['value']
cokkies = response.cookies
return csrf, cokkies
# 这个函数用来解决ReCAPTCHA问题。它使用TwoCaptcha solver对象的recaptcha()方法,如果发生异常则打印错误并退出。
def solve(url,sitekey):
try:
result = solver.recaptcha(sitekey=sitekey, url=url)
except Exception as e:
print(e)
exit()
return result
# 这个函数用来提交解决ReCAPTCHA后的页面。它首先构建一个POST请求的payload,然后通过requests.post()方法发送请求。最后返回网页的最后一列的文本。
def post_page(url, csrf, cookie, result):
payload = 'csrfmiddlewaretoken={}&g-recaptcha-response={}'
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Referer': 'https://www.scrapebay.com/spam'
}
response = requests.post(url,data=payload.format(csrf,result),headers=headers,cookies=cookie)
soup = BeautifulSoup(response.text, "lxml")
el = soup.select_one('td:last-child')
return el.get_text()
# 先通过get_csrf_cookie(url)获取CSRF token和cookies,然后通过solve(url,site_key)解决ReCAPTCHA问题,最后通过post_page(url,csrf,cokkies,result)提交页面并打印出结果。
def main():
csrf,cokkies = get_csrf_cookie(url)
print("csrf:",csrf)
print("cokkies:",cokkies)
result = solve(url,site_key)
print("captcha:",result)
data = post_page(url,csrf,cokkies,result)
print("result:",data)
if __name__ == "__main__":
main()
网站验证后的页面:
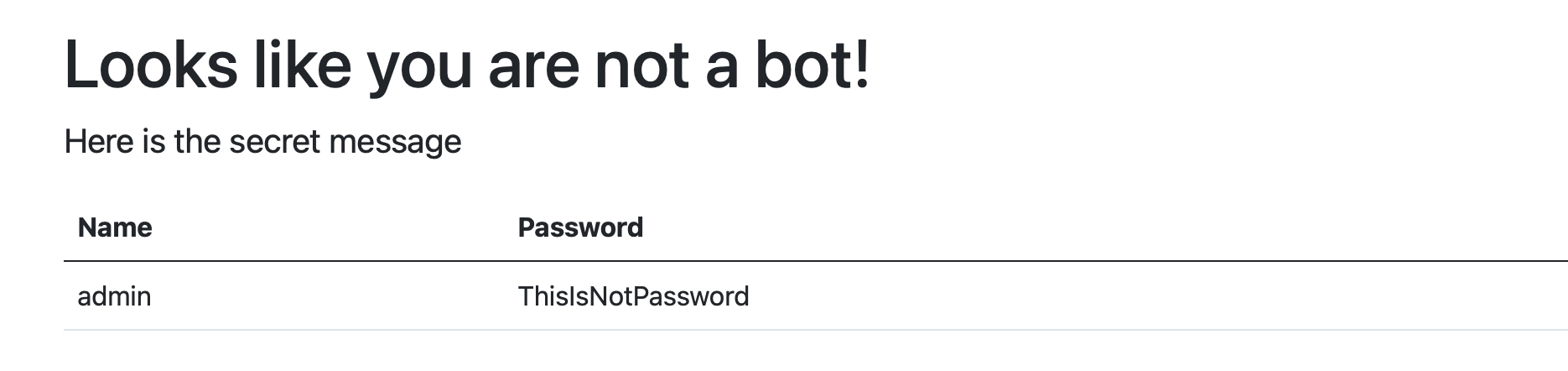
运行结果:

7. 结束
至此我们使用2Captcha服务破解了reCAPTCHA v2,并获得了需要爬取的内容。2Captcha服务包含多种验证码格式,均可以使用上述的流程,修改其中不同验证码的细节部分,攻克验证码的识别难点。
如有帮助,请多关注
个人微信公众号:【TechLead】分享AI与云服务研发的全维度知识,谈谈我作为TechLead对技术的独特洞察。
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号