正则表达式语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种我们所需要的子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
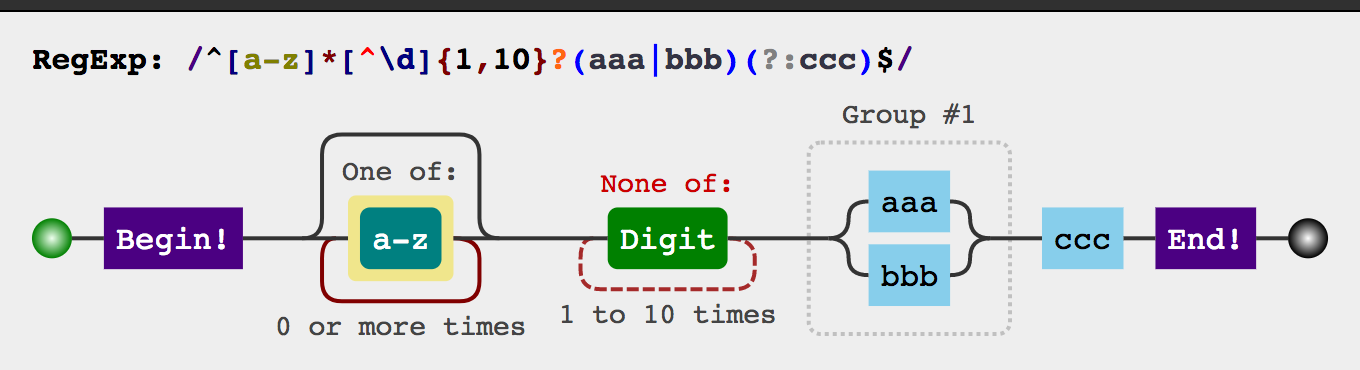
正则表达式语法
简单字符
没有特殊意义的字符都是简单字符,简单字符就代表自身,绝大部分字符都是简单字符,举个例子:
Pattern pattern = Pattern.compile("123");
Matcher matcher = pattern.matcher("12345");
//pattern = Pattern.compile("海镜");
//matcher = pattern.matcher("海镜");
if (matcher.find()) {
System.out.println("match : " + matcher.group());
} else {
System.out.println("not match ");
}转义字符
\是转义字符,其后面的字符会代表不同的意思,转义字符主要有三个作用:
第一种,是为了匹配不方便显示的特殊字符,比如换行,tab符号等
第二种,正则中预先定义了一些代表特殊意义的字符,比如\w等
第三种,在正则中某些字符有特殊含义(比如下面说到的),转义字符可以让其显示自身的含义
下面是常用转义字符列表:

字符集合
有时我们需要匹配一类字符,字符集可以实现这个功能,字符集的语法用[]分隔,下面的代码能够匹配a或b或c
[abc]如果要表示字符很多,可以使用-表示一个范围内的字符,下面两个功能相同
[0123456789]
[0-9]在前面添加^,可表示非的意思,下面的代码能够匹配abc之外的任意字符
[^abc]其实正则还内置了一些字符集,在上面的转义字符有提到,下面给出内置字符集对应的自定义字符集
- . 匹配除了换行符(\n)以外的任意一个字符 = [^\n],如果是表示小数点,记得使用转义符号:\.
- \w = [0-9a-Z_]
- \W = [^0-9a-Z_]
- \s = [ \t\n\v]
- \S = [^ \t\n\v]
- \d = [0-9]
- \D = [^0-9]
量词
如果我们有三个苹果,我们可以说自己有个3个苹果,也可以说有一个苹果,一个苹果,一个苹果,每种语言都有量词的概念
如果需要匹配多次某个字符,正则也提供了量词的功能,正则中的量词有多个,如?、+、*、{n}、{m,n}、{m,}
{n}匹配n次,比如a{2},匹配aa
{m, n}匹配m-n次,优先匹配n次,比如a{1,3},可以匹配aaa、aa、a
{m,}匹配m-∞次,优先匹配∞次,比如a{1,},可以匹配aaaa...
?匹配0次或1次,优先匹配1次,相当于{0,1}
+匹配1-n次,优先匹配n次,相当于{1,}
*匹配0-n次,优先匹配n次,相当于{0,}
正则默认和人心一样是贪婪的,也就是常说的贪婪模式,凡是表示范围的量词,都优先匹配上限而不是下限。
a{1, 3} // 匹配字符串'aaa'的话,会匹配aaa而不是a有时候这不是我们想要的结果,可以在量词后面加上?,就可以开启非贪婪模式
a{1, 3}? // 匹配字符串'aaa'的话,会匹配a而不是aaa字符边界
有时我们会有边界的匹配要求,比如以xxx开头,以xxx结尾。
^在[]外表示匹配开头的意思:
^abc // 可以匹配abc,但是不能匹配aabc$表示匹配结尾的意思:
abc$ // 可以匹配abc,但是不能匹配abcc上面提到的\b表示单词的边界
abc\b // 可以匹配 abc ,但是不能匹配 abcc选择表达式
有时我们想匹配x或者y,如果x和y是单个字符,可以使用字符集,[abc]可以匹配a或b或c,如果x和y是多个字符,字符集就无能为力了,此时就要用到分组
正则中用|来表示分组,a|b表示匹配a或者b的意思
123|456|789 // 匹配 123 或 456 或 789分组与引用
分组是正则中非常强大的一个功能,可以让上面提到的量词作用于一组字符,而非单个字符,分组的语法是圆括号包裹(xxx)
(abc){2} // 匹配abcabc分组不能放在[]中,分组中还可以使用选择表达式
(123|456){2} // 匹配 123123、456456、123456、456123和分组相关的概念还有一个捕获分组和非捕获分组,分组默认都是捕获的,在分组的(后面添加?:可以让分组变为非捕获分组,非捕获分组可以提高性能和简化逻辑。
和分组相关的另一个概念是引用,比如在匹配html标签时,通常希望<xxx></xxx>后面的xxx能够和前面保持一致
引用的语法是\数字,数字代表引用前面第几个捕获分组,注意非捕获分组不能被引用
<([a-z]+)><\/\1> // 可以匹配 `<span></span>` 或 `<div></div>`等修饰符
默认正则是区分大小写,这可能并不是我们想要的,正则提供了修饰符的功能,修饰的语法如下:
- g正则遇到第一个匹配的字符就会结束,加上全局修复符,可以让其匹配到结束
- i正则默认是区分大小写的,i可以忽略大小写
- m正则默认遇到换行符就结束了,不能匹配多行文本,m可以让其匹配多行文本
//忽略大小写
Pattern pattern = Pattern.compile("HELLO", Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher("hello");
if (matcher.find()) {
System.out.println("match : " + matcher.group());
} else {
System.out.println("not match ");
}JavaScript使用正则表达式
创建正则对象
RegExp 对象是带有预定义属性和方法的正则表达式对象。
方式1:var reg = new RegExp("\d", 'i');
方式2:var reg = /\d/i;
参数说明
- i:忽略大小写
- g:全局匹配
- gi:全局匹配 + 忽略大小写
正则匹配
test() 是一个正则表达式方法。它通过模式来搜索字符串,然后根据结果返回 true 或 false。
匹配日期:
// 匹配日期
var dateStr = "2019-09-10";
var reg = /^\d{4}-\d{2}-\d{2}$/;
console.log(reg.test(dateStr));运算符优先级
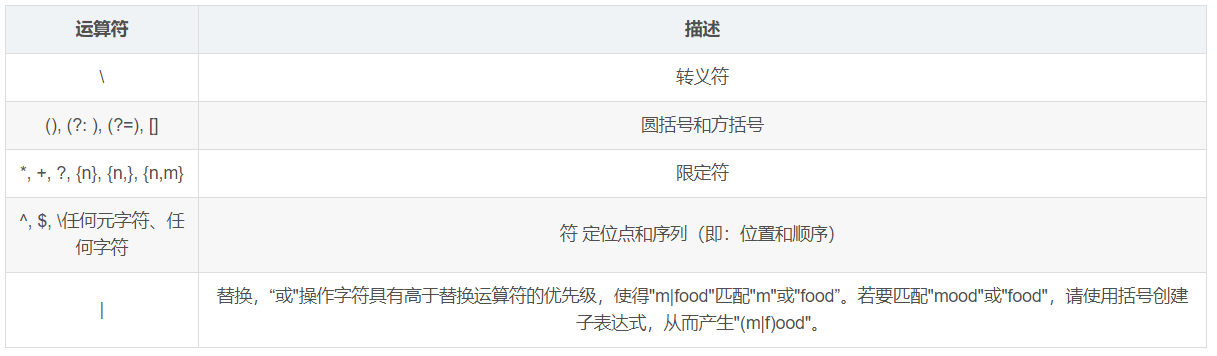
正则表达式从左到右进行计算,并遵循优先级顺序,这与算术表达式非常类似。
相同优先级的从左到右进行运算,不同优先级的运算先高后低。下表从最高到最低说明了各种正则表达式运算符的优先级顺序:
Java使用正则表达式
Java 中使用正则表达式需要用到两个类,分别为 java.util.regex.Pattern 和 java.util.regex.Matcher。
第一步,通过正则表达式创建模式对象 Pattern。
第二步,通过模式对象 Pattern,根据指定字符串创建匹配对象 Matcher。
第三步,通过匹配对象 Matcher,根据正则表达式操作字符
Pattern类
Pattern类表示正则表达式中的模式。可以使用Pattern.compile(String regex)方法来创建Pattern对象。
import java.util.regex.Pattern;
Pattern pattern = Pattern.compile("[abc]");Matcher类
Matcher类表示对指定字符串和模式进行匹配。可以使用Pattern.matcher(String input)方法来创建Matcher对象。
- goupCount() 返回该正则表达式模式中的分组数目,对应于「左括号」的数目
- group(int i) 返回对应组的匹配字符,没有匹配到则返回 null
- start(int group) 返回对应组的匹配字符的起始索引
- end(int group) 返回对应组的匹配字符的最后一个字符索引加一的值
String txt = "明天2天 后天3天";
String reg = "明天\\d天\\s(后天\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.start(1));
System.out.println(matcher.end(1));
System.out.println(matcher.groupCount());
}
输出:
双休日2天 节假日3天
节假日3天
6
11
1find和matches
- find()方法在部分匹配时和完全匹配时返回true,匹配不上返回false
- matches()方法只有在完全匹配时返回true,匹配不上和部分匹配都返回false
String txt = "明天2天 后天3天2";
String reg = "明天\\d天\\s(后天\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(true);
}
if (!matcher.matches()) {
System.out.println(false);
}
输出:
true
falselookingAt()
lookingAt()对前面的字符串进行匹配,只有匹配到的字符串在最前面才返回true。
reset()
重置匹配器。
String txt ="abbc";
String reg = "ab+";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println("贪婪模式");
System.out.println(matcher.group(0));
}
if (matcher.find()) {
System.out.println("懒惰模式");
System.out.println(matcher.group(0));
}
输出:
贪婪模式
abb
String txt ="abbc";
String reg = "ab+";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println("贪婪模式");
System.out.println(matcher.group(0));
}
matcher.reset();
if (matcher.find()) {
System.out.println("懒惰模式");
System.out.println(matcher.group(0));
}
输出:
贪婪模式
abb
懒惰模式
abb捕获分组和非捕获分组
()表示捕获分组,()会把每个分组里的匹配的值保存起来,使用$n(n是一个数字,表示第n个捕获组的内容) (?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来。
分组和反向引用
捕获分组会在正则表达式中创建反向引用。在以正则表达式替换字符串的语法中,是通过 $ 来引用分组的反向引用,$0 是匹配完整模式的字符串(注意在 JavaScript 中是用 $& 表示);$1 是第一个分组的反向引用;$2 是第二个分组的反向引用,以此类推。
String Str = "Hello , World .";
String pattern = "(\\w)(\\s+)([.,])";
// $0 匹配 `(\w)(\s+)([.,])` 结果为 `o空格,` 和 `d空格.`
// $1 匹配 `(\w)` 结果为 `o` 和 `d`
// $2 匹配 `(\s+)` 结果为 `空格` 和 `空格`
// $3 匹配 `([.,])` 结果为 `,` 和 `.`
System.out.println(Str.replaceAll(pattern, "$1$3")); // Hello, World.
输出
Hello, World.分组的反向引用副本
Java 中可以在小括号中使用 ?<name> 将小括号中匹配的内容保存为一个名字为 name 的副本。
String str = "2ddx 在哪儿";
Pattern pattern = Pattern.compile("2(?<first>\\w+\\s)"); // 保存一个副本
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
System.out.println(matcher.group());
System.out.println(matcher.group(1));
System.out.println(matcher.group("first"));
}
输出
2ddx
ddx
ddx 前瞻、后顾、负前瞻、负后顾
非捕获分组的前瞻、后顾、负前瞻、负后顾四个概念,下面以都是以匹配exp1来进行说明。
// 前瞻: exp1(?=exp2) 查找exp2前面的exp1
// 后顾: (?<=exp2)exp1 查找exp2后面的exp1
// 负前瞻: exp1(?!exp2) 查找后面不是exp2的exp1
// 负后顾: (?<!exp2)exp1 查找前面不是exp2的exp1
说明:(?<=...)和(?<!...)这种写法,里面的内容必须是定长的,不能是变长的,比如不能使用(?<=a+)
例子:前瞻
String txt = "明天2天 后天3天都在家";
String reg = "(\\d天)(?=\\s后天\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.groupCount());
}
输出
2天
2天
1
例子:后顾
String txt = "明天2天 后天3天都在家";
String reg = "(?<=\\d天)(\\s后天\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.groupCount());
}
输出:
后天3天
后天3天
1
例子:负前瞻
String txt = "明天2天 后天3天都在家";
String reg = "(?<!后天)(\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.groupCount());
}
输出
2天
2天
1
例子:负后顾
String txt = "后天3天";
String reg = "([\\u4e00-\\u9fa5]+)(?!\\d天)";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
System.out.println(matcher.group(1));
System.out.println(matcher.groupCount());
}
输出
后
后
1正则表达式的模式
可以在正则的开头指定模式修饰符。
- (?i) 使正则忽略大小写。
- (?s) 表示*单行模式*("single line mode")使正则的 . 匹配所有字符,包括换行符。
- (?m) 表示*多行模式*("multi-line mode"),使正则的 ^ 和 $ 匹配字符串中每行的开始和结束
String txt = "后天Abc天";
String reg = "(?i)[a-z]+";
Pattern pattern = Pattern.compile(reg);
Matcher matcher = pattern.matcher(txt);
if (matcher.find()) {
System.out.println(matcher.group(0));
}
输出:
AbcString类的正则表达式方法
String类提供了一些方法来支持正则表达式的处理,例如:
- matches(String regex):判断字符串是否匹配指定的正则表达式。
- replaceAll(String regex, String replacement):使用指定的替换字符串替换匹配的字符串。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现