【◐系统架构】高可用系统设计
高可用系统设计指南
什么是高可用?可用性的判断标准是什么?
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的。
一般情况下,我们使用多少个 9 来评判一个系统的可用性,比如 99.9999% 就是代表该系统在所有的运行时间中只有 0.0001% 的时间是不可用的,这样的系统就是非常非常高可用的了!当然,也会有系统如果可用性不太好的话,可能连 9 都上不了。
除此之外,系统的可用性还可以用某功能的失败次数与总的请求次数之比来衡量,比如对网站请求 1000 次,其中有 10 次请求失败,那么可用性就是 99%。
哪些情况会导致系统不可用?
- 黑客攻击;
- 硬件故障,比如服务器坏掉;
- 并发量/用户请求量激增导致整个服务宕掉或者部分服务不可用;
- 代码错误导致内存泄漏或者其他问题导致程序挂掉;
- 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用;
- 自然灾害或者人为破坏;
- ......
有哪些提高系统可用性的方法?
注重代码质量,测试严格把关
这是最重要,也是最基础的。代码质量有问题比如比较常见的内存泄漏、循环依赖都是对系统可用性极大的损害。
几个对提高代码质量有实际效果的神器:
- SonarQube:SonarQube 是一个开源的代码分析平台, 用来持续分析和评测项目源代码的质量。 通过SonarQube我们可以检测出项目中重复代码, 潜在bug, 代码规范,安全性漏洞等问题, 并通过SonarQube web UI展示出来。
- Arthas:是一款阿里巴巴开源的 Java 线上诊断工具,功能非常强大,可以解决很多线上不方便解决的问题。
- 阿里巴巴Java开发规范
- IDEA 自带的代码分析等工具
使用集群,减少单点故障
用Redis举个例子。
我们如何保证我们的 Redis 缓存高可用呢?答案就是使用集群,避免单点故障。当我们使用一个 Redis 实例作为缓存的时候,这个 Redis 实例挂了之后,整个缓存服务可能就挂了。使用了集群之后,即使一台 Redis 实例挂了,不到一秒就会有另外一台 Redis 实例顶上。
限流
流量控制(flow control),其原理是监控应用流量的 QPS 或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
QPS:每秒查询率。指一台服务器每秒能够响应的查询次数
超时和重试机制设置
一旦用户请求超过某个时间得不到响应,就抛出异常。这个是非常重要的,很多线上系统故障都是因为没有进行超时设置或者超时设置的方式不对导致的。我们在读取第三方服务的时候,尤其适合设置超时和重试机制。一般我们使用一些 RPC 框架的时候,这些框架都自带的超时重试的配置。如果不进行超时设置可能会导致请求响应速度慢,甚至导致请求堆积进而让系统无法再处理请求。重试的次数一般设为 3 次,再多次的重试没有好处,反而会加重服务器压力(部分场景使用失败重试机制会不太适合)。
熔断机制
超时和重试机制设置之外,熔断机制也是很重要的。 熔断机制说的是系统自动收集所依赖服务的资源使用情况和性能指标,当所依赖的服务恶化或者调用失败次数达到某个阈值的时候就迅速失败,让当前系统立即切换依赖其他备用服务。 比较常用的流量控制和熔断降级框架是 Netflix 的 Hystrix 和 alibaba 的 Sentinel。
异步调用
异步调用的话我们不需要关心最后的结果,这样我们就可以在用户请求完成之后就立即返回结果,具体处理我们可以后续再做,秒杀场景用这个还是用的蛮多的。但是,使用异步之后我们可能需要 适当修改业务流程进行配合,比如用户在提交订单之后,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功。除了可以在程序中实现异步之外,我们常常还使用消息队列,消息队列可以通过异步处理提高系统性能(削峰、减少响应所需时间)并且可以降低系统耦合性。
使用缓存
如果我们的系统属于并发量比较高的话,如果我们单纯使用数据库的话,当大量请求直接落到数据库可能数据库就会直接挂掉。使用缓存缓存热点数据,因为缓存存储在内存中,所以速度相当地快!
其他
- 核心应用和服务优先使用更好的硬件;
- 监控系统资源使用情况增加报警设置;
- 注意备份,必要时候回滚;
- 灰度发布:将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可;
- 定期检查/更换硬件:如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级;
- .....
冗余设计
冗余设计是保证系统和数据高可用的最常的手段。
对于服务来说,冗余的思想就是相同的服务部署多份,如果正在使用的服务突然挂掉的话,系统可以很快切换到备份服务上,大大减少系统的不可用时间,提高系统的可用性。
对于数据来说,冗余的思想就是相同的数据备份多份,这样就可以很简单地提高数据的安全性。
高可用集群(High Availability Cluster,简称 HA Cluster)、同城灾备、异地灾备、同城多活和异地多活是冗余思想在高可用系统设计中最典型的应用。
- 高可用集群:同一份服务部署两份或者多份,当正在使用的服务突然挂掉的话,可以切换到另外一台服务,从而保证服务的高可用。
- 同城灾备:一整个集群可以部署在同一个机房,而同城灾备中相同服务部署在同一个城市的不同机房中。并且,备用服务不处理请求。这样可以避免机房出现意外情况比如停电、火灾。
- 异地灾备:类似于同城灾备,不同的是,相同服务部署在异地(通常距离较远,甚至是在不同的城市或者国家)的不同机房中
- 同城多活:类似于同城灾备,但备用服务可以处理请求,这样可以充分利用系统资源,提高系统的并发。
- 异地多活:将服务部署在异地的不同机房中,并且,它们可以同时对外提供服务。
高可用集群单纯是服务的冗余,并没有强调地域。同城灾备、异地灾备、同城多活和异地多活实现了地域上的冗余。
同城和异地的主要区别在于机房之间的距离。异地通常距离较远,甚至是在不同的城市或者国家。
和传统的灾备设计相比,同城多活和异地多活最明显的改变在于“多活”,即所有站点都是同时在对外提供服务的。异地多活是为了应对突发状况比如火灾、地震等自然或者人为灾害。
光做好冗余还不够,必须要配合上故障转移才可以! 所谓故障转移,简单来说就是实现不可用服务快速且自动地切换到可用服务,整个过程不需要人为干涉。
举个例子:哨兵模式的 Redis 集群中,如果 Sentinel(哨兵) 检测到 master 节点出现故障的话, 它就会帮助我们实现故障转移,自动将某一台 slave 升级为 master,确保整个 Redis 系统的可用性。整个过程完全自动,不需要人工介入。
再举个例子:Nginx 可以结合 Keepalived 来实现高可用。如果 Nginx 主服务器宕机的话,Keepalived 可以自动进行故障转移,备用 Nginx 主服务器升级为主服务。并且,这个切换对外是透明的,因为使用的虚拟 IP,虚拟 IP 不会改变。
服务限流
针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
限流可能会导致用户的请求无法被正确处理,不过,这往往也是权衡了软件系统的稳定性之后得到的最优解。
现实生活中,处处都有限流的实际应用,就比如排队买票是为了避免大量用户涌入购票而导致售票员无法处理。
常见的限流算法
固定窗口计数器算法
固定窗口其实就是时间窗口。固定窗口计数器算法 规定了我们单位时间处理的请求数量。
假如我们规定系统中某个接口 1 分钟只能访问 33 次的话,使用固定窗口计数器算法的实现思路如下:
- 给定一个变量 counter 来记录当前接口处理的请求数量,初始值为 0(代表接口当前 1 分钟内还未处理请求)。
- 1 分钟之内每处理一个请求之后就将 counter+1 ,当 counter=33 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
- 等到 1 分钟结束后,将 counter 重置 0,重新开始计数。
这种限流算法无法保证限流速率,因而无法保证突然激增的流量。
就比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
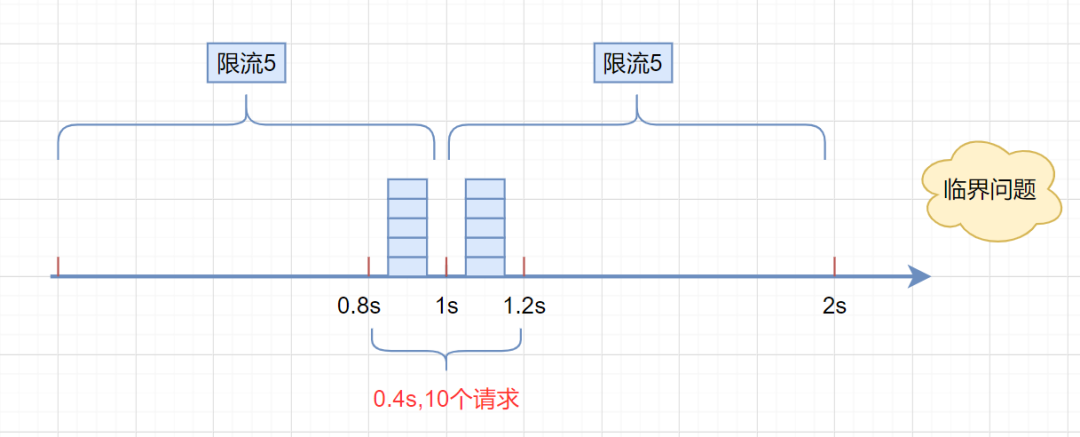
另外还存在一个临界问题:假设限流阀值为5个请求,单位时间窗口是1s,如果我们在单位时间内的前0.8-1s和1-1.2s,分别并发5个请求。虽然都没有超过阀值,但是如果算0.8-1.2s,则并发数高达10,已经超过单位时间1s不超过5阀值的定义。
代码示例:
查看代码
public class CounterTest {
public long timeStamp = getNowTime();
public int reqCount = 0;
public final int limit = 5; // 时间窗口内最大请求数
public final long interval = 1000; // 时间窗口ms
public boolean grant() {
long now = getNowTime(); //获取系统当前时间
//检查是否在时间窗口内
if (now < timeStamp + interval) { // 在时间窗口内
reqCount++;
return reqCount <= limit; // 判断当前时间窗口内是否超过最大请求控制数
} else { // 不在时间窗口内
timeStamp = now; //开启新的时间窗口
reqCount = 1; //计数器加1
return true;
}
}
public long getNowTime() {
return System.currentTimeMillis();
}
public static void main(String[] args) throws Exception {
CounterTest counterTest = new CounterTest();
while (true) {
Thread.sleep(100);
boolean grant = counterTest.grant();
if (grant) {
System.out.println("接口请求量 ========== : " + counterTest.reqCount);
} else {
System.out.println("接口限流.....");
}
}
}
}滑动窗口计数器算法
滑动窗口计数器算法 算的上是固定窗口计数器算法的升级版,解决了固定窗口临界值的问题。它将单位时间周期分为n个小周期,分别记录每个小周期内接口的访问次数,并且根据时间滑动删除过期的小周期。
滑动窗口计数器算法相比于固定窗口计数器算法的优化在于:它把时间以一定比例分片 。
例如我们的接口限流每分钟处理 60 个请求,我们可以把 1 分钟分为 60 个窗口。每隔 1 秒移动一次,每个窗口一秒只能处理 不大于 60(请求数)/60(窗口数) 的请求, 如果当前窗口的请求计数总和超过了限制的数量的话就不再处理其他请求。
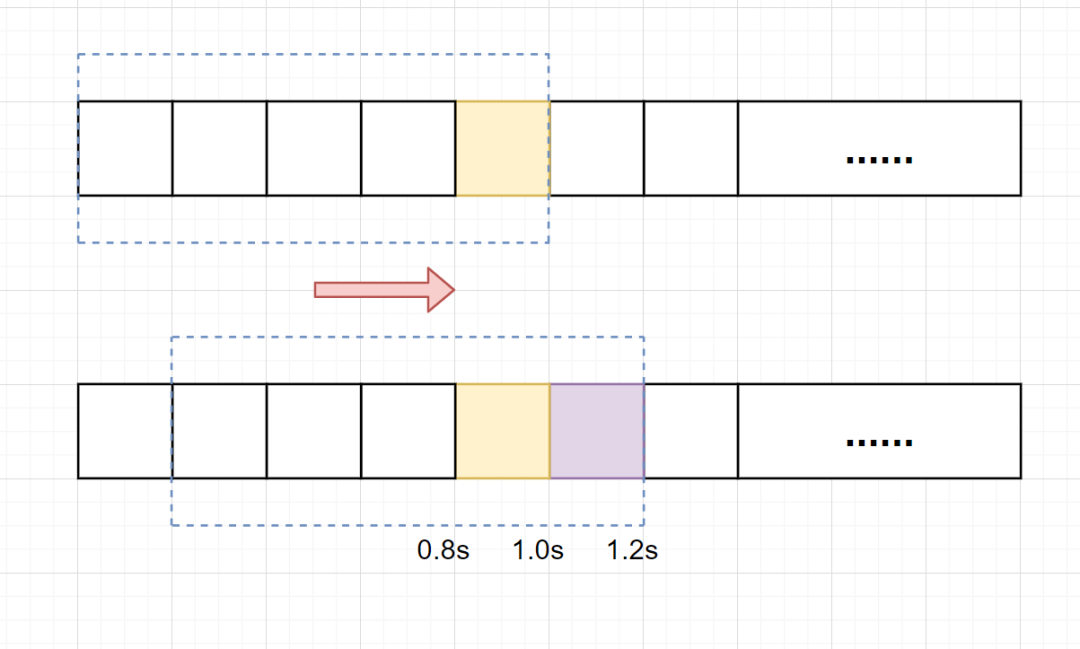
假设单位时间还是1s,滑动窗口算法把它划分为5个小周期,也就是滑动窗口(单位时间)被划分为5个小格子。每格表示0.2s。每过0.2s,时间窗口就会往右滑动一格。然后呢,每个小周期,都有自己独立的计数器,如果请求是0.83s到达的,0.8~1.0s对应的计数器就会加1。
我们来看下滑动窗口是如何解决临界问题的?
假设我们1s内的限流阀值还是5个请求,0.8~1.0s内(比如0.9s的时候)来了5个请求,落在黄色格子里。时间过了1.0s这个点之后,又来5个请求,落在紫色格子里。如果是固定窗口算法,是不会被限流的,但是滑动窗口的话,每过一个小周期,它会右移一个小格。过了1.0s这个点后,会右移一小格,当前的单位时间段是0.2~1.2s,这个区域的请求已经超过限定的5了,已触发限流啦,实际上,紫色格子的请求都被拒绝啦。
很显然, 当滑动窗口的格子划分的越多,滑动窗口的滚动就越平滑,限流的统计就会越精确。
漏桶算法
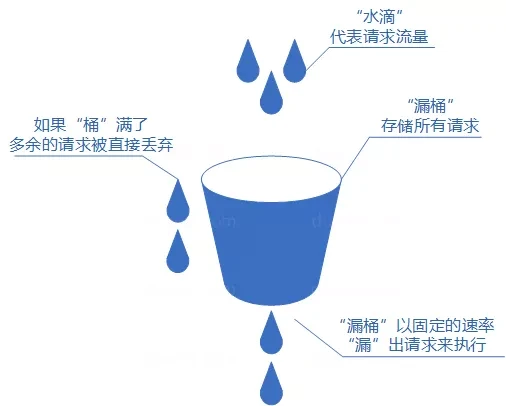
漏桶(Leaky Bucket)算法可以理解为注水漏水的过程,往漏桶中以任意速率流入水,以固定的速率流出水。当水超过桶的容量时,会被溢出,也就是被丢弃。因为桶容量是不变的,保证了整体的速率。
- 流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的;
- 桶的容量一般用来表示系统所能处理的请求数;
- 如果桶的容量满了,也就达到限流的阀值,会丢弃水滴(即:拒绝请求);
- 流出的水滴,是恒定速率的,用来表示服务按照固定的速率处理请求。
消息中间件MQ采用的正是漏桶的思想,水滴的流入和留出可以看做是生产者消费者模式。
- 请求是一个生产者,每一个请求都如一滴水,请求到来后放到一个队列(漏桶)中;
- 桶底有一个孔,不断的漏出水滴,就像消费者不断的消费队列中的内容,并且消费的速率(漏出的速度)等于限流阈值。
如果想要实现这个算法的话也很简单,准备一个队列用来保存请求,然后我们定期从队列中拿请求来执行就好了(和消息队列削峰/限流的思想是一样的)。
查看代码
/**
* 漏桶算法
* <p>
* 可以理解为注水漏水的过程,往漏桶中以任意速率流入水,以固定的速率流出水。
* 当水超过桶的容量时,会被溢出,也就是被丢弃。因为桶容量是不变的,保证了整体的速率。
* 流入的水滴,可以看作是访问系统的请求,这个流入速率是不确定的;
* 桶的容量一般用来表示系统所能处理的请求数;如果桶的容量满了,也就达到限流的阀值,会丢弃水滴(即:拒绝请求);
* 流出的水滴,是恒定速率的,用来表示服务按照固定的速率处理请求。
*
* @author Saint
*/
public class LeakyBucketRateLimiter {
private int qps = 2;
// 漏桶
private LinkedBlockingQueue<Character> waterBucket;
// 表示桶是否被初始化
private volatile boolean initialized = false;
// 关联一个漏桶(一般情况为自身)
private static volatile LeakyBucketRateLimiter leakyBucketRateLimiter;
public static LeakyBucketRateLimiter getLeakyBucket() {
return leakyBucketRateLimiter;
}
/**
* 创建一个漏桶
*
* @param capacity 漏桶容量
* @param qps 漏桶支持的QPS
* @return
*/
public static LeakyBucketRateLimiter create(int capacity, int qps) {
leakyBucketRateLimiter = new LeakyBucketRateLimiter(capacity, qps);
return leakyBucketRateLimiter;
}
private LeakyBucketRateLimiter(int capacity, int qps) {
// 漏桶只能被初始化一次
if (!initialized) {
initialized = true;
this.qps = qps;
waterBucket = new LinkedBlockingQueue<>(capacity);
// 初始化消费者
initConsumer();
}
}
/**
* 漏桶中的水以固定速率流出
*/
private void initConsumer() {
new Thread(() -> {
while (true) {
try {
TimeUnit.MILLISECONDS.sleep(1000 / qps);
} catch (InterruptedException e) {
// log for exception
System.out.println("Exception occur! " + e);
}
// 以固定速率消费
waterBucket.poll();
}
}).start();
}
/**
* 是否将请求加入到漏桶,能存入则代表漏桶没满,允许请求通过,返回true;否则返回false
*
* @return
*/
public boolean tryAcquire() {
return waterBucket.offer('S');
}
/**
* 漏桶容量2,每秒流出2滴水;
* 最初漏桶中没有水,所以第一秒立刻打进去两滴水;又由于漏桶每秒流出2滴水,所以在程序开始跑时,第一秒必会流出一滴水(极限情况2滴)
* 所以第一秒会进入3滴水,第一秒之后每秒稳定流出2滴水,即QPS为2;
*
* @param args
*/
public static void main(String[] args) {
LeakyBucketRateLimiter leakyBucket = LeakyBucketRateLimiter.create(2, 2);
for (int i = 0; i < 20; i++) {
LocalDateTime now = LocalDateTime.now();
if (leakyBucket.tryAcquire()) {
System.out.println(now + " pass the rate limiting");
} else {
System.out.println(now + " was limited");
}
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
// 日志记录
}
}
System.out.println("------------");
// 再次获取漏桶
LeakyBucketRateLimiter leakyBucket2 = LeakyBucketRateLimiter.getLeakyBucket();
// 验证漏桶只会有一个
System.out.println("leakyBucket only one ? " + (leakyBucket == leakyBucket2));
for (int i = 0; i < 10; i++) {
LocalDateTime now = LocalDateTime.now();
if (leakyBucket2.tryAcquire()) {
System.out.println(now + " pass the rate limiting");
} else {
System.out.println(now + " was limited");
}
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
// 日志记录
}
}
}
}令牌桶算法
令牌桶(Token Bucket)算法是对漏桶算法的一种改进,不仅能够平滑限流,还允许一定程度的流量突发;它是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。
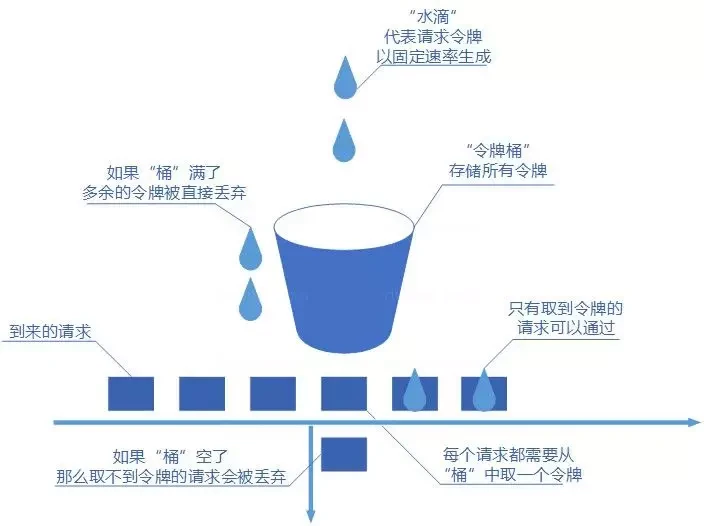
令牌桶的实现思路也类似于生产者和消费之间的关系:
- 系统服务作为生产者,按照指定频率向桶(容器)中添加令牌,如 QPS 为 500,每 2ms 向桶中添加一个令牌,如果桶中令牌数量达到阈值,则不再添加。
- 请求的执行作为消费者,每个请求都需要去桶中拿取一个令牌,取到令牌则继续执行;
- 如果桶中无令牌可取,就触发拒绝策略,可以是超时等待,也可以是直接拒绝请求,以此达到限流目的。
令牌桶的实现特点:
- 1s / 限流阈值(QPS) = 令牌添加时间间隔;
- 桶的容量可以大于限流的阈值(做一定的冗余),令牌数量达到桶容量时,不再添加;
- 可以适应流量突发,N 个请求到来只需要从桶中获取 N 个令牌就可以继续处理;
- 令牌桶启动时桶中无令牌,启动后按照令牌添加时间间隔添加令牌,若启动时就有阈值数量的请求过来,会因为桶中没有足够的令牌而触发拒绝策略,不过如 RateLimiter 限流工具已经优化了这个问题。
Google 的 Java 开发工具包 Guava 中的限流工具类 RateLimiter 就是令牌桶的一个实现。
查看代码
/**
* 令牌桶算法
* 系统服务作为生产者,按照指定频率向桶(容器)中添加令牌,如 QPS 为 500,每 2ms 向桶中添加一个令牌,如果桶中令牌数量达到阈值,则不再添加。
* 请求的执行作为消费者,每个请求都需要去桶中拿取一个令牌,取到令牌则继续执行;
* 如果桶中无令牌可取,就触发拒绝策略,可以是超时等待,也可以是直接拒绝请求,以此达到限流目的。
* <p>
* 1s / 限流阈值(QPS) = 令牌添加时间间隔;
* 桶的容量可以大于限流的阈值(做一定的冗余),令牌数量达到桶容量时,不再添加;
*/
public class TokenBucketRateLimiter {
private int qps = 2;
// 令牌桶
private volatile LinkedBlockingQueue<Character> tokenBucket = null;
// 表示桶是否被初始化
private volatile boolean initialized = false;
// 关联一个;令牌桶(一般情况为自身)
private static volatile TokenBucketRateLimiter tokenBucketRateLimiter;
public static TokenBucketRateLimiter getTokenBucket() {
return tokenBucketRateLimiter;
}
/**
* 创建一个漏桶
*
* @param capacity 漏桶容量
* @param qps 漏桶支持的QPS
* @return
*/
public static TokenBucketRateLimiter create(int capacity, int qps) {
tokenBucketRateLimiter = new TokenBucketRateLimiter(capacity, qps);
return tokenBucketRateLimiter;
}
private TokenBucketRateLimiter(int capacity, int qps) {
// 漏桶只能被初始化一次
if (!initialized) {
initialized = true;
this.qps = qps;
tokenBucket = new LinkedBlockingQueue<>(capacity);
// 初始化生产者
initProducer();
}
}
/**
* 令牌桶中的令牌以固定速率加入
*/
private void initProducer() {
// 令牌桶初始容量为qps
for (int i = 0; i < qps; i++) {
tokenBucket.offer('S');
}
new Thread(() -> {
while (true) {
try {
TimeUnit.MILLISECONDS.sleep(1000 / qps);
} catch (InterruptedException e) {
// log for exception
System.out.println("Exception occur! " + e);
}
// 以固定速率生产令牌
tokenBucket.offer('S');
}
}).start();
}
/**
* 获取令牌,能获取到,允许请求通过,返回true;否则返回false
*
* @return
*/
public boolean tryAcquire() {
return tokenBucket.poll() == null ? false : true;
}
/**
* 令牌桶容量为2,每秒加入2个令牌;
* 最初漏桶中有两个令牌,所以第一秒立刻获取到两个令牌;又由于令牌桶每秒加入2个令牌,所以在程序开始跑时,第一秒必回加入一个令牌(极限情况2个)
* 所以第一秒会获取到3个令牌,第一秒之后每秒稳定获取到两个令牌,即QPS为2;
*
* @param args
*/
public static void main(String[] args) {
TokenBucketRateLimiter tokenBucket = TokenBucketRateLimiter.create(2, 2);
for (int i = 0; i < 20; i++) {
LocalDateTime now = LocalDateTime.now();
if (tokenBucket.tryAcquire()) {
System.out.println(now + " pass the rate limiting");
} else {
System.out.println(now + " was limited");
}
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
// 日志记录
}
}
System.out.println("------------");
// 再次获取漏桶
TokenBucketRateLimiter tokenBucket2 = TokenBucketRateLimiter.getTokenBucket();
// 验证令牌桶只会有一个
System.out.println("tokenBucket only one ? " + (tokenBucket == tokenBucket2));
for (int i = 0; i < 10; i++) {
LocalDateTime now = LocalDateTime.now();
if (tokenBucket2.tryAcquire()) {
System.out.println(now + " pass the rate limiting");
} else {
System.out.println(now + " was limited");
}
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
// 日志记录
}
}
}
}单机限流怎么做?
单机限流针对的是单体架构应用。
单机限流可以直接使用 Google Guava 自带的限流工具类 RateLimiter 。 RateLimiter 基于令牌桶算法,可以应对突发流量。
除了最基本的令牌桶算法(平滑突发限流)实现之外,Guava 的RateLimiter还提供了 平滑预热限流 的算法实现。
平滑突发限流就是按照指定的速率放令牌到桶里,而平滑预热限流会有一段预热时间,预热时间之内,速率会逐渐提升到配置的速率。
我们直接在项目中引入 Guava 相关的依赖即可使用。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>31.0.1-jre</version>
</dependency>下面是一个简单的 Guava 平滑突发限流的 Demo。
public class RateLimiterDemo {
public static void main(String[] args) {
// 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
RateLimiter rateLimiter = RateLimiter.create(5);
for (int i = 0; i < 10; i++) {
double sleepingTime = rateLimiter.acquire(1);
System.out.printf("get 1 tokens: %ss%n", sleepingTime);
}
}
}下面是一个简单的 Guava 平滑预热限流的 Demo。
public class RateLimiterDemo {
public static void main(String[] args) {
// 1s 放 5 个令牌到桶里也就是 0.2s 放 1个令牌到桶里
// 预热时间为3s,也就说刚开始的 3s 内发牌速率会逐渐提升到 0.2s 放 1 个令牌到桶里
RateLimiter rateLimiter = RateLimiter.create(5, 3, TimeUnit.SECONDS);
for (int i = 0; i < 20; i++) {
double sleepingTime = rateLimiter.acquire(1);
System.out.printf("get 1 tokens: %sds%n", sleepingTime);
}
}
}另外,Bucket4j 是一个非常不错的基于令牌/漏桶算法的限流库。
相对于,Guava 的限流工具类来说,Bucket4j 提供的限流功能更加全面。不仅支持单机限流和分布式限流,还可以集成监控,搭配 Prometheus 和 Grafana 使用。
Spring Cloud Gateway 中自带的单机限流的早期版本就是基于 Bucket4j 实现的。后来,替换成了 Resilience4j。
Resilience4j 是一个轻量级的容错组件,其灵感来自于 Hystrix。自Netflix 宣布不再积极开发 Hystrix之后,Spring 官方和 Netflix 都更推荐使用 Resilience4j 来做限流熔断。
一般情况下,为了保证系统的高可用,项目的限流和熔断都是要一起做的。
Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重试等保障系统高可用开箱即用的功能。并且,Resilience4j 的生态也更好,很多网关都使用 Resilience4j 来做限流熔断的。
因此,在绝大部分场景下 Resilience4j 或许会是更好的选择。如果是一些比较简单的限流场景的话,Guava 或者 Bucket4j 也是不错的选择。
分布式限流怎么做?
分布式限流针对的分布式/微服务应用架构应用,在这种架构下,单机限流就不适用了,因为会存在多种服务,并且一种服务也可能会被部署多份。
分布式限流常见的方案:
- 借助中间件架限流 :可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
- 网关层限流 :比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现RedisRateLimiter就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
为什么建议 Redis+Lua 的方式? 主要有两点原因:
- 减少了网络开销 :我们可以利用 Lua 脚本来批量执行多条 Redis 命令,这些 Redis 命令会被提交到 Redis 服务器一次性执行完成,大幅减小了网络开销。
- 原子性 :一段 Lua 脚本可以视作一条命令执行,一段 Lua 脚本执行过程中不会有其他脚本或 Redis 命令同时执行,保证了操作不会被其他指令插入或打扰。
降级 & 熔断
降级
由于爆炸性的流量冲击,对一些服务进行有策略的放弃,以此缓解系统压力,保证目前主要业务的正常运行。它主要是针对非正常情况下的应急服务措施:当此时一些业务服务无法执行时,给出一个统一的返回结果。
降级服务的特征
- 原因:整体负荷超出整体负载承受能力。
- 目的:保证重要或基本服务正常运行,非重要服务延迟使用或暂停使用
- 大小:降低服务粒度,要考虑整体模块粒度的大小,将粒度控制在合适的范围内
- 可控性:在服务粒度大小的基础上增加服务的可控性,后台服务开关的功能是一项必要配置(单机可配置文件,其他可领用数据库和缓存),可分为手动控制和自动控制。
- 次序:一般从外围延伸服务开始降级,需要有一定的配置项,重要性低的优先降级,比如可以分组设置等级1-10,当服务需要降级到某一个级别时,进行相关配置
- 延迟服务:比如发表了评论,重要服务,比如在文章中显示正常,但是延迟给用户增加积分,只是放到一个缓存中,等服务平稳之后再执行。
- 在粒度范围内关闭服务(片段降级或服务功能降级):比如关闭相关文章的推荐,直接关闭推荐区
- 页面异步请求降级:比如商品详情页上有推荐信息/配送至等异步加载的请求,如果这些信息响应慢或者后端服务有问题,可以进行降级;
- 页面跳转(页面降级):比如可以有相关文章推荐,但是更多的页面则直接跳转到某一个地址
- 写降级:比如秒杀抢购,我们可以只进行Cache的更新,然后异步同步扣减库存到DB,保证最终一致性即可,此时可以将DB降级为Cache。
- 读降级:比如多级缓存模式,如果后端服务有问题,可以降级为只读缓存,这种方式适用于对读一致性要求不高的场景。
降级预案
- 一般:比如有些服务偶尔因为网络抖动或者服务正在上线而超时,可以自动降级;
- 警告:有些服务在一段时间内成功率有波动(如在95~100%之间),可以自动降级或人工降级,并发送告警;
- 错误:比如可用率低于90%,或者数据库连接池被打爆了,或者访问量突然猛增到系统能承受的最大阀值,此时可以根据情况自动降级或者人工降级;
- 严重错误:比如因为特殊原因数据错误了,此时需要紧急人工降级。
- 降级按照是否自动化可分为:自动开关降级(超时、失败次数、故障、限流)和人工开关降级(秒杀、电商大促等)。
- 降级按照功能可分为:读服务降级、写服务降级。
- 降级按照处于的系统层次可分为:多级降级。
自动降级分类
- 超时降级:主要配置好超时时间和超时重试次数和机制,并使用异步机制探测回复情况
- 失败次数降级:主要是一些不稳定的api,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
- 故障降级:比如要调用的远程服务挂掉了(网络故障、DNS故障、http服务返回错误的状态码、rpc服务抛出异常),则可以直接降级。降级后的处理方案有:默认值(比如库存服务挂了,返回默认现货)、兜底数据(比如广告挂了,返回提前准备好的一些静态页面)、缓存(之前暂存的一些缓存数据)
- 限流降级:当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)
服务降级需考虑的问题
- 核心服务或非核心服务。
- 是否支持降级及其降级策略。
- 业务放通场景及其策略。
熔断
当下游服务因访问压力过大而响应变慢或失败,上游服务为了保护系统整体的可用性,可以暂时切断对下游服务的调用。
服务雪崩
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C有调用其他的微服务,如果整个链路上某个微服务的调用响应式过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统雪崩,这就是所谓的”雪崩效应”。
断路器
“断路器”本身是一种开关装置(类似熔断保险丝),当某个服务单元发生故障,向调用方法返回一个符合预期的、可处理的备选响应(FallBack),而不是长时间的等待或者抛出调用方法无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延。乃至雪崩。
服务熔断
熔断机制是应对雪崩效应的一种微服务链路保护机制,当整个链路的某个微服务不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回”错误”的响应信息。
Hystrix
Hystrix是一个用于分布式系统的延迟和容错的开源库。在分布式系统里,许多依赖不可避免的调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下,不会导致整个服务失败,避免级联故障,以提高分布式系统的弹性。
服务熔断与服务降级比较
- 服务熔断通常是下级服务故障引起;服务降级通常为整体系统而考虑。
- 熔断是每个微服务都需要的,是一个框架级的处理;而服务降级一般是关注业务,对业务进行考虑,抓住业务的层级,从而决定在哪一层上进行处理:比如在IO层,业务逻辑层,还是在外围进行处理。
超时 & 重试
由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
为了最大限度的减小系统或者服务出现故障之后带来的影响,我们需要用到的 超时(Timeout) 和 重试(Retry) 机制。
超时和重试机制并不是多么高深的概念,但是它俩确实非常的重要和实用。你平时接触到的绝大部分涉及到远程调用的系统或者服务都会应用超时和重试机制。尤其是对于微服务系统来说,正确设置超时和重试非常重要。单体服务通常只涉及数据库、缓存、第三方 API、中间件等的网络调用,而微服务系统内部各个服务之间还存在着网络调用。
超时机制
什么是超时机制
超时机制说的是当一个请求超过指定的时间(比如 1s)还没有被处理的话,这个请求就会直接被取消并抛出指定的异常或者错误(比如 504 Gateway Timeout)。
我们平时接触到的超时可以简单分为下面 2 种:
- 连接超时(ConnectTimeout):客户端与服务端建立连接的最长等待时间。
- 读取超时(ReadTimeout):客户端和服务端已经建立连接,客户端等待服务端处理完请求的最长时间。实际项目中,我们关注比较多的还是读取超时。
一些连接池客户端框架中可能还会有获取连接超时和空闲连接清理超时。
如果没有设置超时的话,就可能会导致服务端连接数爆炸和大量请求堆积的问题。
这些堆积的连接和请求会消耗系统资源,影响新收到的请求的处理。严重的情况下,甚至会拖垮整个系统或者服务。
超时时间应该如何设置?
超时到底设置多长时间是一个难题!超时值设置太高或者太低都有风险。如果设置太高的话,会降低超时机制的有效性,比如你设置超时为 10s 的话,那设置超时就没啥意义了,系统依然可能会出现大量慢请求堆积的问题。如果设置太低的话,就可能会导致在系统或者服务在某些处理请求速度变慢的情况下(比如请求突然增多),大量请求重试(超时通常会结合重试)继续加重系统或者服务的压力,进而导致整个系统或者服务被拖垮的问题。
通常情况下,我们建议读取超时设置为 1500ms ,这是一个比较普适的值。如果你的系统或者服务对于延迟比较敏感的话,那读取超时值可以适当在 1500ms 的基础上进行缩短。反之,读取超时值也可以在 1500ms 的基础上进行加长,不过,尽量还是不要超过 1500ms 。连接超时可以适当设置长一些,建议在 1000ms ~ 5000ms 之内。
超时值具体该设置多大,还是要根据实际项目的需求和情况慢慢调整优化得到。
重试机制
什么是重试机制
重试机制一般配合超时机制一起使用,指的是多次发送相同的请求来避免瞬态故障和偶然性故障。
瞬态故障可以简单理解为某一瞬间系统偶然出现的故障,并不会持久。偶然性故障可以理解为哪些在某些情况下偶尔出现的故障,频率通常较低。
重试的核心思想是通过消耗服务器的资源来尽可能获得请求更大概率被成功处理。由于瞬态故障和偶然性故障是很少发生的,因此,重试对于服务器的资源消耗几乎是可以被忽略的。
重试的次数如何设置?
重试的次数不宜过多,否则依然会对系统负载造成比较大的压力。
重试的次数通常建议设为 3 次。并且,我们通常还会设置重试的间隔,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
重试幂等
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
什么情况下会出现一个请求被多次执行呢?客户端等待服务端完成请求完成超时但此时服务端已经执行了请求,只是由于短暂的网络波动导致响应在发送给客户端的过程中延迟了。
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具