【♆数据结构】数据结构
数据结构,也就是 Data Structure,是一种存储数据的结构体,数据与数据之间存在着一定的关系,这样的关系有数据的逻辑关系、数据的存储关系和数据的运算关系。
在 Java 中,数据结构一般可以分为两大类:线性数据结构和非线性数据结构。
数组
数组(Array) 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
数组这种数据结构最大的好处,就是可以根据下标(或者叫索引)进行操作,插入的时候可以根据下标直接插入到具体的位置,但与此同时,后面的元素就需要全部向后移动,需要移动的数据越多,就越累。
时间复杂度
- 通过下标(index)访问一个元素的时间复杂度为 O(1),因为是直达的,无论数据增大多少倍,耗时都不变
- 数组末尾添加一个元素,时间复杂度为 O(1)
- 删除一个元素的时间复杂度为 O(n),因为要遍历数组,数据量增大几倍,耗时也增大几倍
- 查找一个未排序的数组时间复杂度为 O(n),因为要遍历数组;查找排序过的数组时间复杂度为 O(log n),因为可以使用二分查找法,当数据增大 n 倍时,耗时增大 logn 倍(这里的 log 是以 2 为底的,每找一次排除一半的可能)
数组长度固定,不支持动态扩容。可以随机访问元素。
链表
虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时间复杂度为 O(n) 。
特点
长度不固定,插入和删除比较简单,只需要知道目标位置的上一个原色即可。查找复杂。使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
单向链表
单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。
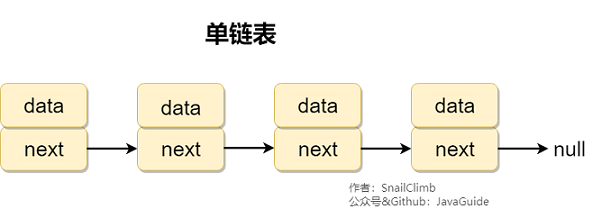
双向链表
双向链表 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
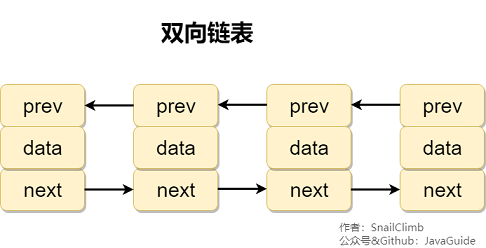
循环链表
循环链表 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
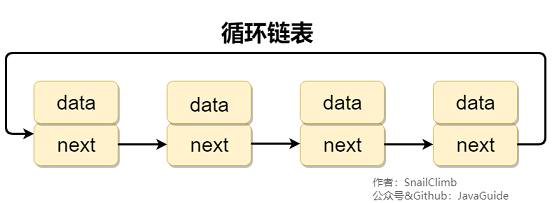
双向循环链表
双向循环链表 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
数组和链表比较
- 数组长度固定且支持随机访问元素,链表长度不固定不支持随机访问。
- 如果需要的元素数量固定,且不需要经常的插入和删除,数组适合。
- 如果需要的元素数量不固定,且需要经常插入和删除链表更合适。
- 数组开辟连续的空间,链表不是开辟的连续空间。
栈
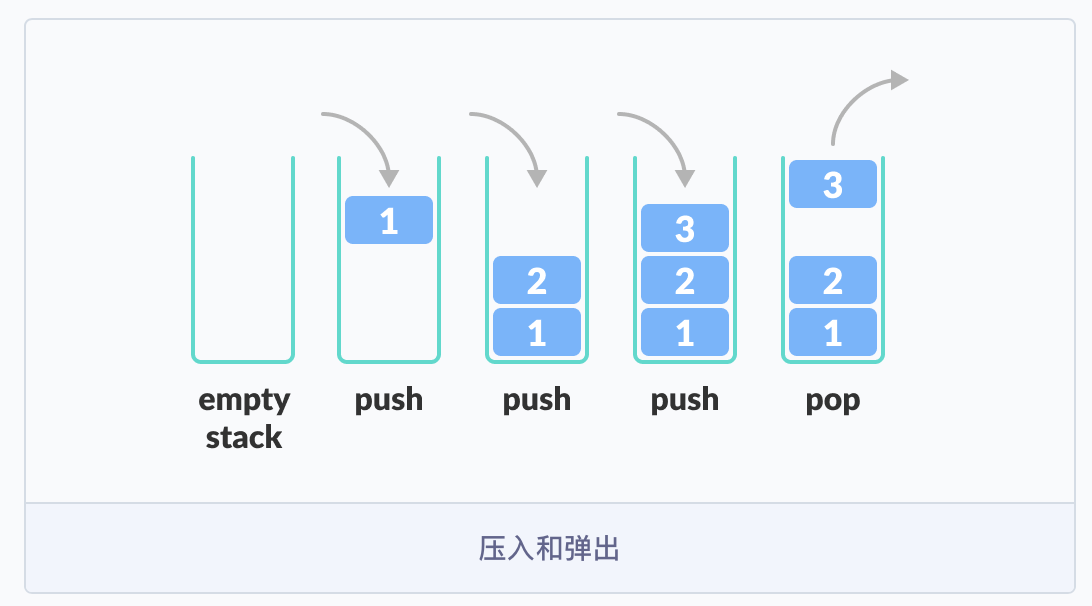
栈 (stack)只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 后进先出(LIFO, Last In First Out) 的原理运作。在栈中,push 和 pop 的操作都发生在栈顶。
栈常用一维数组或链表来实现,用数组实现的栈叫作 顺序栈 ,用链表实现的栈叫作 链式栈 。
队列
队列 是 先进先出( FIFO,First In, First Out) 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 顺序队列 ,用链表实现的队列叫作 链式队列 。队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue。
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。

树
树是一种典型的非线性结构,它是由 n(n>0)个有限节点组成的一个具有层次关系的集合。之所以叫“树”,是因为这种数据结构看起来就像是一个倒挂的树,只不过根在上,叶在下。树形数据结构有以下这些特点:
- 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- 一棵树不包含回路。
下图展示了树的一些术语:
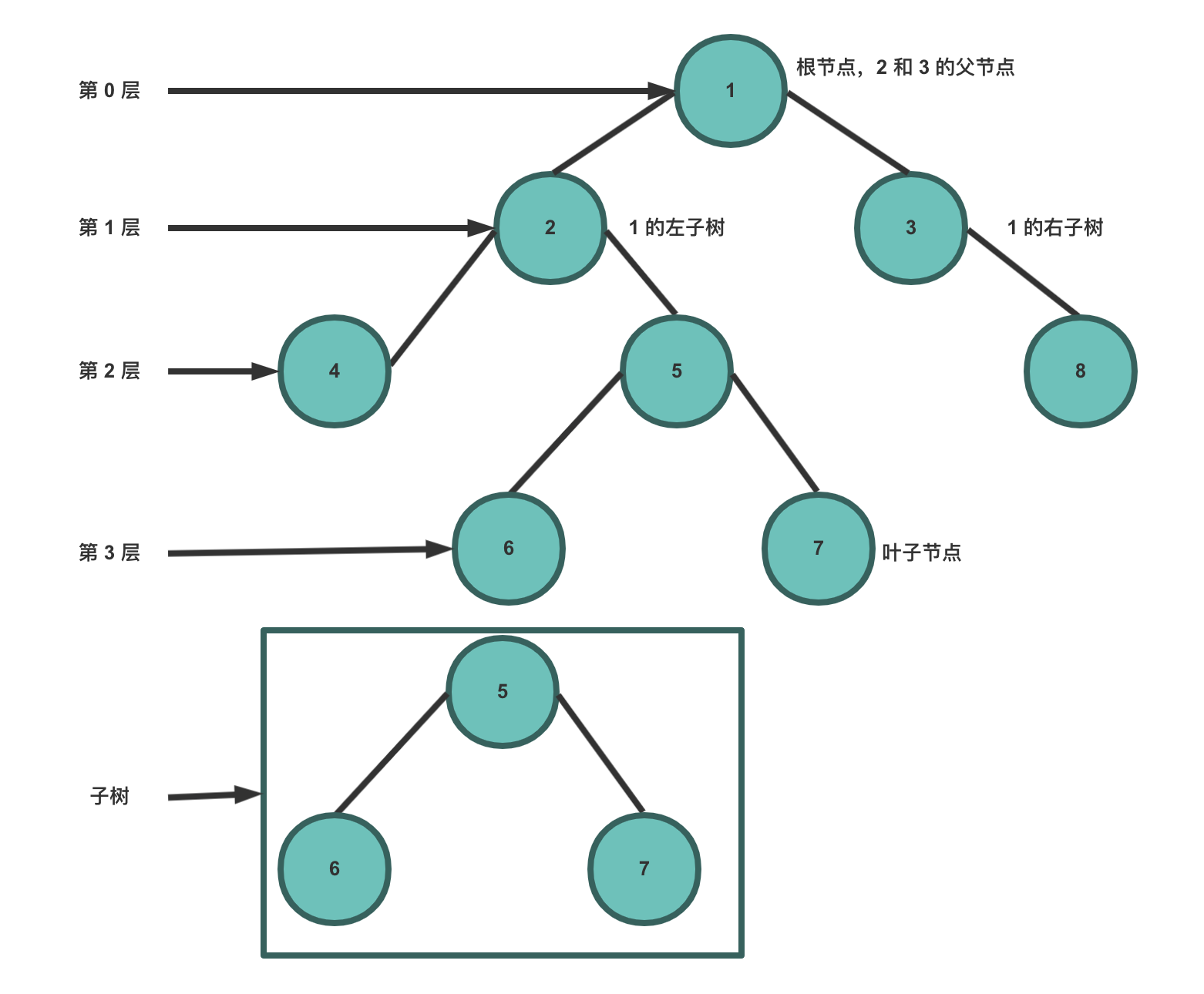
根节点是第 0 层,它的子节点是第 1 层,子节点的子节点为第 2 层,以此类推。
- 节点 :树中的每个元素都可以统称为节点。
- 根节点 :顶层节点或者说没有父节点的节点。
- 父节点 :若一个节点含有子节点,则这个节点称为其子节点的父节点。
- 子节点 :一个节点含有的子树的根节点称为该节点的子节点。
- 兄弟节点 :具有相同父节点的节点互称为兄弟节点。
- 叶子节点 :没有子节点的节点。
- 节点的高度 :该节点到叶子节点的最长路径所包含的边数。
- 节点的深度 :根节点到该节点的路径所包含的边数
- 节点的层数 :节点的深度+1。
- 树的高度 :根节点的高度。
- 深度:对于任意节点 n,n 的深度为从根到 n 的唯一路径长,根的深度为 0。
- 高度:对于任意节点 n,n 的高度为从 n 到一片树叶的最长路径长,所有树叶的高度为 0。
树又可以细分为下面几种:
(1)普通树
对子节点没有任何约束。
(2)二叉树
每个节点最多含有两个子节点的树。 二叉树按照不同的表现形式又可以分为多种。
1)普通二叉树
每个子节点的父节点不一定有两个子节点的二叉树。
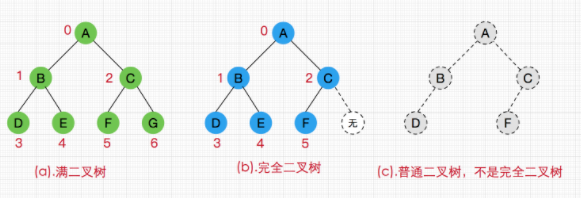
2)完全二叉树
对于一颗二叉树,假设其深度为d(d>1)。除了第 d 层外,其它各层的节点数目均已达最大值,且第 d 层所有节点从左向右连续地紧密排列。
3)满二叉树
一颗每一层的节点数都达到了最大值的二叉树。有两种表现形式,第一种,像下图这样(每一层都是满的),满足每一层的节点数都达到了最大值 2。
4)最优二叉树(哈夫曼树)
树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。
哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。应用:哈夫曼编码。
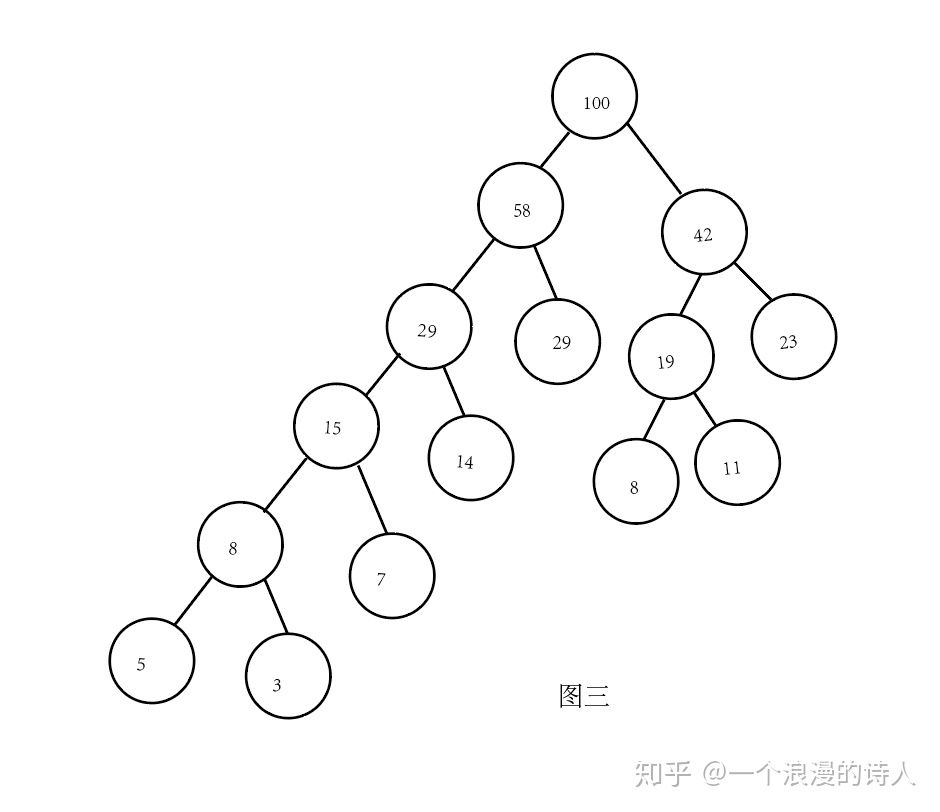
二叉树的遍历:
- 先序遍历:二叉树的先序遍历,就是先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则,也就是说,我们可以递归实现先序遍历。
- 中序遍历:二叉树的中序遍历,就是先递归中序遍历左子树,再输出根结点的值,再递归中序遍历右子树。
- 后序遍历:二叉树的后序遍历,就是先递归后序遍历左子树,再递归后序遍历右子树,最后输出根结点的值。
(3)二叉查找树
英文名叫 Binary Search Tree,即 BST,需要满足以下条件:
- 任意节点的左子树不空,左子树上所有节点的值均小于它的根节点的值;
- 任意节点的右子树不空,右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉查找树。
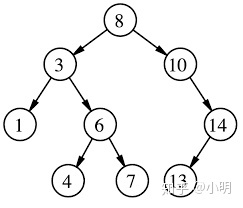
1)平衡二叉树
当且仅当任何节点的两棵子树的高度差不大于 1 的二叉树。由前苏联的数学家 Adelse-Velskil 和 Landis 在 1962 年提出的高度平衡的二叉树,根据科学家的英文名也称为 AVL 树。
平衡二叉树本质上也是一颗二叉查找树,不过为了限制左右子树的高度差,避免出现倾斜树等偏向于线性结构演化的情况,所以对二叉搜索树中每个节点的左右子树作了限制,左右子树的高度差称之为平衡因子,树中每个节点的平衡因子绝对值不大于 1。
平衡二叉树的难点在于,当删除或者增加节点的情况下,如何通过左旋或者右旋的方式来保持左右平衡。
平衡二叉树在添加和删除时需要进行复杂的旋转保持整个树的平衡,最终,插入、查找的时间复杂度都是 O(logn),性能已经相当好了。
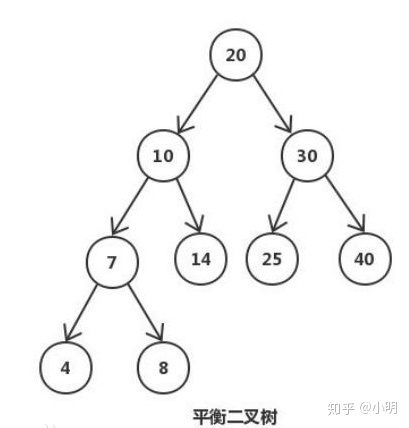
2)红黑树
红黑树是一种常见的平衡二叉树,节点是红色或者黑色,通过颜色的约束来维持着二叉树的平衡:
- 每个节点都只能是红色或者黑色
- 根节点是黑色
- 每个叶节点(NIL 节点,空节点)是黑色的。
- 如果一个节点是红色的,则它两个子节点都是黑色的。也就是说在一条路径上不能出现相邻的两个红色节点。
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
(4)B 树
一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多于两个的子树。
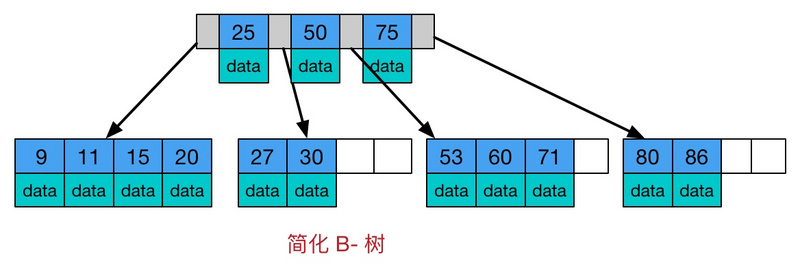
(5)B+ 树
B 树的变体。
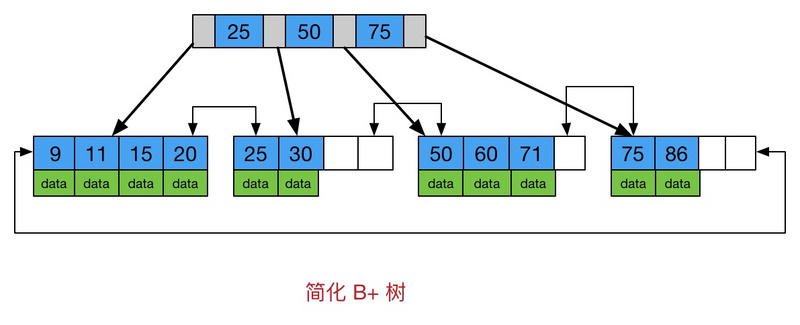
HashMap 里面的 TreeNode 就用到了红黑树,而 B 树、B+ 树在数据库的索引原理里面有典型的应用。
哈希表
哈希表(Hash Table),也叫散列表,是一种可以通过关键码值(key-value)直接访问的数据结构,它最大的特点就是可以快速实现查找、插入和删除。其中用到的算法叫做哈希,就是把任意长度的输入,变换成固定长度的输出,该输出就是哈希值。像 MD5、SHA1 都用的是哈希算法。
每一个 Java 对象都会有一个哈希值,默认情况就是通过调用本地方法执行哈希算法,计算出对象的内存地址 + 对象的值的关键码值。
数组的最大特点就是查找容易,插入和删除困难;而链表正好相反,查找困难,而插入和删除容易。哈希表很完美地结合了两者的优点, Java 的 HashMap 在此基础上还加入了树的优点。
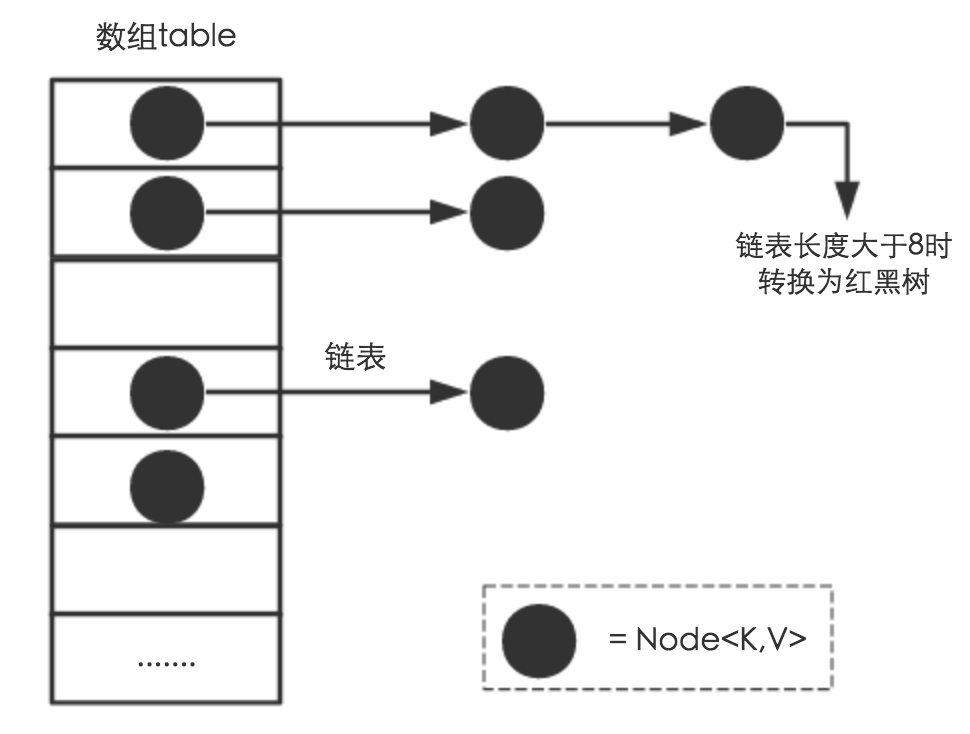
哈希表具有较快(常量级)的查询速度,以及相对较快的增删速度,所以很适合在海量数据的环境中使用。
对于任意两个不同的数据块,其哈希值相同的可能性极小,也就是说,对于一个给定的数据块,找到和它哈希值相同的数据块极为困难。再者,对于一个数据块,哪怕只改动它的一个比特位,其哈希值的改动也会非常的大——这正是 Hash 存在的价值!
尽管可能性极小,但仍然会发生,如果哈希冲突了,Java 的 HashMap 会在数组的同一个位置上增加链表,如果链表的长度大于 8,将会转化成红黑树进行处理——这就是所谓的拉链法(数组+链表)。
图
图是一种复杂的非线性结构,由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
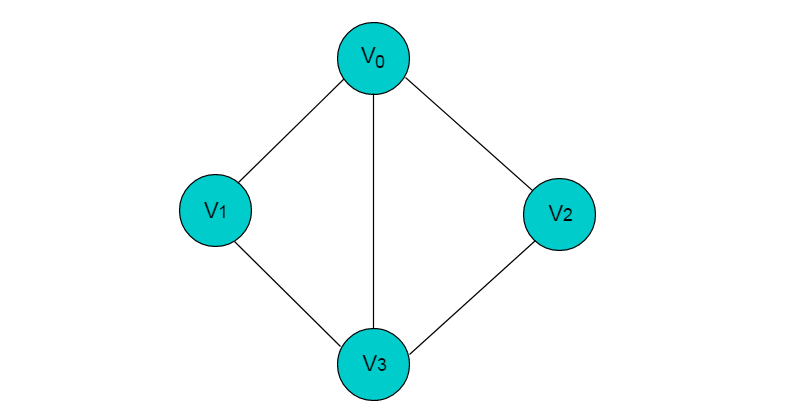
上图共有 V0,V1,V2,V3 这 4 个顶点,4 个顶点之间共有 5 条边。
在线性结构中,数据元素之间满足唯一的线性关系,每个数据元素(除第一个和最后一个外)均有唯一的“前驱”和“后继”;
在树形结构中,数据元素之间有着明显的层次关系,并且每个数据元素只与上一层中的一个元素(父节点)及下一层的多个元素(子节点)相关;
而在图形结构中,节点之间的关系是任意的,图中任意两个数据元素之间都有可能相关。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2022-04-09 【Linux】Redis集群部署
2022-04-09 【Linux】安装MySQL
2022-04-09 【Linux】安装JDK
2022-04-09 【Linux】安装Tomcat