MySQL数据查询语言(DQL)
本篇将会介绍 MySQL 中的各种查询语句,主要使用的数据表结构如下:
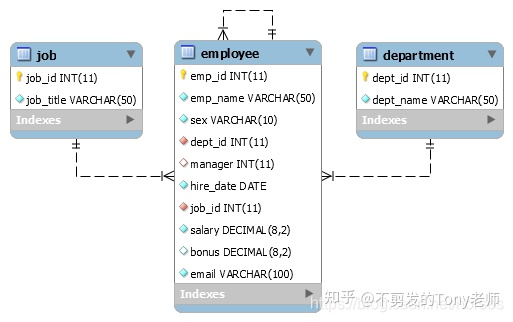
它们分别是:
- 部门表(department),包含部门编号(dept_id)和部门名称(dept_name)字段,主键为部门编号。该表共计 6 条数据。
- 职位表(job),包含职位编号(job_id)和职位名称(job_title)字段,主键为职位编号。该表共计 10 条数据。
- 员工表(employee),包含员工编号(emp_id)和员工姓名(emp_name)等字段,主键为员工编号,部门编号(dept_id)字段是引用部门表的外键,职位编号(job_id)字段是引用职位表的外键,经理编号(manager)字段是引用员工表自身的外键。该表共计 25 条数据。
可以点击下载创建数据表和生成示例数据的脚本,执行这些脚本完成相关的初始化操作。
简单查询
查询指定字段
在 MySQL 中,使用 SELECT 语句查询表中的数据。基本的查询语法如下:
SELECT col1, col2
FROM table_name;其中,SELECT 表示要查询的字段或者表达式;FROM 表示从哪个表中查询;它们都是关键字,SQL 不区分大小写,但是一般关键字大写;最后的分号(;)表示语句的结束。
例如,以下查询语句返回了员工的姓名和年薪(月薪乘以 12):
SELECT emp_name, salary * 12
FROM employee;
emp_name|salary * 12|
---------|-----------|
刘备 | 360000.00|
关羽 | 312000.00|
张飞 | 288000.00|
...查询全部字段
查询表中全部字段的第一个方法就是在 SELECT 列表中写上所有的字段。例如,以下语句返回了员工表中的所有字段:
SELECT emp_id, emp_name, sex, dept_id, manager, hire_date, job_id, salary, bonus, email
FROM employee;
emp_id| emp_name| sex|dept_id|manager|hire_date |job_id|salary |bonus |email |
------|---------|----|-------|-------|----------|------|--------|--------|------------------------|
1|刘备 |男 | 1| |2000-01-01| 1|30000.00|10000.00|liubei@shuguo.com |
2|关羽 |男 | 1| 1|2000-01-01| 2|26000.00|10000.00|guanyu@shuguo.com |
3|张飞 |男 | 1| 1|2000-01-01| 2|24000.00|10000.00|zhangfei@shuguo.com |
...另一个方法就是使用星号(*)表示全部字段。例如,以上语句也可以写成:
SELECT *
FROM employee;MySQL 在解析该语句时,会自动将星号扩展为表中的所有字段名。
⚠️星号可以便于快速编写查询语句,但是在实际项目中不要使用这种写法。一方面,应用程序可能并不需要所有的字段,避免返回过多的无用数据;另一方面,当表结构发生变化时,星号返回的信息也会发生改变。
快速查询
通常来说,我们查询的目标都是数据表;意味着查询语句的基本形式为 SELECT … FROM … 。不过,MySQL 还支持另一种形式的查询语句:只有 SELECT,没有 FROM 的查询。例如:
SELECT version(), now(), 1 + 1;
version()|now() |1 + 1|
---------|-------------------|-----|
8.0.20 |2020-06-04 13:14:24| 2|这种形式的查询语句通常用于快速查找信息,或者当作计算器使用。上面的示例分别返回了 MySQL 服务器的版本、当前时间以及 1 + 1 的值。
Oracle 为了实现快速查询提供了一个特殊的表 dual,它只有一个字段且只包含一行数据。MySQL 也支持类似的写法,例如:
SELECT version(), now(), 1 + 1 FROM dual;使用别名
默认情况下,查询返回的字段标题就是字段名或者表达式的定义。为了提高查询结果的可读性,可以使用关键字 AS 为返回的字段或者查询中的表指定一个别名(Alias)。
SELECT emp_name AS "员工姓名", salary * 12 "年薪"
FROM employee;
姓名 |年薪 |
-----|---------|
刘备 |360000.00|
关羽 |312000.00|
张飞 |288000.00|别名中的关键字 AS 可以省略。别名不会修改数据库中存储的表名或者列名,它只在当前语句中有效。另外,表别名会在多表连接查询时使用到。
使用注释
MySQL 支持代码的注释。注释可以帮助我们理解代码的作用,一般不会被服务器执行。
MySQL 中的注释分为单行注释和多行注释。
单行注释有两种形式,第一种就是以两个连字符(--)开始,直到这一行结束。例如:
SELECT * -- 返回全部字段信息
FROM employee;需要注意的是,与 SQL 标准不同,MySQL 中的两个连字符号之后必须包含一个空白字符(空格、回车、制表符等)。例如:
SELECT 1 -- 1;
1|
-|
1|
SELECT 1 --1;
1 --1|
-----|
2|
SELECT 1 --备注
FROM dual;
ERROR 1054 (42S22): Unknown column '备注' in 'field list'在第一个语句中,两个连字符号表示注释;在第二个语句中,两个连字符号被分开解析,表示 1 减去 -1;第三个语句解析出错。
第二种形式的单行注释以井号(#)开始,直到这一行结束。例如:
SELECT 1 #备注
FROM dual;MySQL 使用 C 语言风格的多行注释(/ … /),例如:
SELECT *
/* 返回全部字段信息
* tony.dong
* 2021-06-04
*/
FROM employee;MySQL 不支持嵌套的多行注释。
除了以上不会被执行的注释之外,MySQL 中还存在一种可能被执行的注释。这种注释可以用于实现不同数据库之间的移植。例如:
SELECT /*! STRAIGHT_JOIN */ col1 FROM table1,table2 WHERE ...其中,STRAIGHT_JOIN 是 MySQL 中的专有特性,会被服务器解析;其他的数据库则会忽略注释中的内容。
这种注释还可以指定 MySQL 的版本。例如:
CREATE TABLE t1 (
k INT AUTO_INCREMENT,
KEY (k)
) /*!50110 KEY_BLOCK_SIZE=1024; */该语句在 MySQL 5.1.10 之后会指定参数 KEY_BLOCK_SIZE 的值,而在之前的版本中没有该属性,不会被执行。因此,这种方式可以编写支持不同 MySQL 版本的 SQL 语句。
过滤条件
简单条件
MySQL 中的 WHERE 子句可以用于指定一个查询条件,只有满足条件的数据才会返回。指定 WHERE 子句的语法如下:
SELECT col1, col2, ...
FROM table_name
WHERE conditions;其中,conditions 是一个逻辑表达式,它的结果可能为 TRUE(1)、FALSE(0)或者 UNKNOWN(NULL)。对于表中的数据行,只有表达式为 TRUE 的才会返回。例如,以下查询只返回月薪大于 10000 的员工姓名:
select emp_name, salary
from employee
where salary > 10000;
emp_name|salary |
---------|--------|
刘备 |30000.00|
关羽 |26000.00|
张飞 |24000.00|
诸葛亮 |25000.00|
孙尚香 |12000.00|
赵云 |15000.00|在 SQL 定义中,WHERE 子句也被称为谓词(predicate)。
以上示例中的大于号(>)是一个比较运算符,用于判断 salary 是否大于 10000。
除了大于号之外,MySQL 还支持以下比较运算符:等于(=)、不等于(<> 或者 !=)、大于等于(>=)、小于(<)、小于等于(<=)。例如,以下查询返回了姓名叫做“张飞”的员工:
select emp_name, hire_date
from employee
where emp_name = '张飞';
emp_name|hire_date |
---------|----------|
张飞 |2000-01-01|另外,BETWEEN 运算符可以用于判断数据是否位于某个范围之内。例如,以下查询返回 2002 年入职的员工:
select emp_name, hire_date
from employee
where hire_date between '2002-01-01' and '2002-12-31';
emp_name|hire_date |
----------|----------|
孙尚香 |2002-08-08|
孙丫鬟 |2002-08-08|BETWEEN 运算符包含了两端的值,所以上面的示例查询的是 2002 年入职的员工。
除此之外,IN 运算符可以用于判断数据是否位于某个列表之中。例如,以下查询返回了编号为 1、2 或者 3 的员工:
select emp_name, hire_date
from employee
where emp_id IN (1, 2, 3);
emp_name|hire_date |
---------|----------|
刘备 |2000-01-01|
关羽 |2000-01-01|
张飞 |2000-01-01|只要数据和 IN 列表中的任意值相等,就表示满足条件。IN 运算符中除了直接给出列表之外,还可以使用子查询返回一个结果集。
空值判断
在数据库中,空值(NULL )表示缺失或者未知的数据,它不等于 0 或者空字符串。对于空值的判断,不能使用普通的等于或者不等于,而需要使用特殊的 IS NULL 和 IS NOT NULL 运算符。例如:
select null is null, null = 0, null = null, null != null;
null is null|null = 0|null = null|null != null|
------------|--------|-----------|------------|
1| | | |只有 null is null 的结果为 True(MySQL 使用 1 表示 True,0 表示 False);null = 0 的结果是未知(Unknown),因为未知数据和 0 比较的结果也是未知;null = null 和 null != null 的结果都是未知。
以下查询返回了没有上级领导的员工:
select emp_name, manager
from employee
where manager is null;
emp_name|manager|
---------|-------|
刘备 | |如果想要查询存在上级领导的员工,可以使用 IS NOT NULL 运算符:
select emp_name, manager
from employee
where manager is not null;除了 IS [NOT] NULL 运算符之外,MySQL 还提供了一个空值判断的函数:ISNULL(expr)。如果 expr 为空值,该函数返回 1;否则,返回 0。例如:
SELECT isnull(0), isnull(null);
isnull(0)|isnull(null)|
---------|------------|
0| 1|另外,MySQL 还提供了一个支持 NULL 值的比较运算符:<=>。例如:
select 0 <=> 0, null <=> null, 0 <=> null;
0 <=> 0|NULL <=> NULL|0 <=> NULL|
-------|-------------|----------|
1| 1| 0|对于非空的数据,<=> 相当于普通的 = 运算符;对于两个 NULL 值,返回 1;对于一个 NULL 值,返回 0。
MySQL 中的 <=> 运算符等价于 SQL 标准中的 IS NOT DISTINCT FROM 运算符。
复合条件
除了使用单个查询条件之外,MySQL 还支持利用逻辑运算符将多个查询条件进行组合:
- AND,逻辑与运算符。当两个表达式的值都为真时结果才为真;
- OR,逻辑或运算符。只要有一个表达式的值为真结果就为真;
- NOT,逻辑非运算符。如果表达式的值为真,结果为假;如果表达式的值为假,结果为真;如果表达式的值为 NULL,结果为 NOT NULL;
- XOR,逻辑异或运算符。只要有一个表达式的值为 NULL,结果就为 NULL;如果一个表达式的值为假,另一个表达式为真,结果就为真;否则结果为假。
以下查询返回了 2011 年之后入职的女性员工:
select emp_name, sex, hire_date
from employee
where sex = '女'
and hire_date >= '2011-01-01';
emp_name |sex |hire_date |
---------|----|----------|
赵氏 |女 |2011-11-10|以下查询返回了所有女性员工以及 2011 年之后入职的员工:
select emp_name, sex, hire_date
from employee
where sex = '女'
or hire_date >= '2011-01-01';
emp_name |sex |hire_date |
----------|----|----------|
孙尚香 |女 |2002-08-08|
孙丫鬟 |女 |2002-08-08|
关平 |男 |2011-07-24|
赵氏 |女 |2011-11-10|
关兴 |男 |2011-07-30|
...以下查询返回了不是 2002 年入职的员工:
select emp_name, hire_date
from employee
where hire_date not between '2002-01-01' and '2002-12-31';
emp_name|hire_date |
---------|----------|
刘备 |2000-01-01|
关羽 |2000-01-01|
张飞 |2000-01-01|
诸葛亮 |2006-03-15|
黄忠 |2008-10-25|NOT 运算符可以对其他运算符的结果取反,例如,NOT IN 运算符返回不在列表中的数据。
对于逻辑运算符,MySQL 使用短路运算(short-circuit)。只要左边的表达式可以决定最终的结果,就不会计算右边的表达式。例如:
select 1 = 0 and 1 / 0;
1 = 0 and 1 / 0|
---------------|
0|因为 1 = 0 的结果为 False,AND 运算符的结果肯定就是 False;所以不会计算 1 / 0,也就不会返回除零错误。
排除重复值
DISTINCT 是一个特殊的运算符,可以排除查询结果中的重复记录:
SELECT [ALL | DISTINCT] col1, col2, ...
FROM table_name;ALL 表示返回全部结果,DISTINCT 表示返回字段组合结果中的不同值。默认选项为 ALL。
例如:
select sex
from employee;
sex|
----|
男 |
男 |
男 |
男 |
男 |
男 |
...
select distinct sex
from employee;
sex|
----|
男 |
女 |对于 DISTINCT 而言,所有的 NULL 值都相同。例如:
select distinct bonus
from employee;
bonus |
--------|
10000.00|
8000.00|
|
5000.00|
6000.00|
2000.00|
1500.00|很多员工的 bonus 都为空,但是查询结果中只返回了一个 NULL 值。
字符串匹配模式
LIKE 运算符
MySQL 中的LIKE运算符可以用于判断字符串是否包含某个模式,返回 1(True)或者 0(False)。使用LIKE运算符的语法如下:
expr LIKE pat如果表达式 expr 能够匹配模式 pat,结果返回 True(1);否则,返回 False(0)。如果 expr 或者 pat 为 NULL, 返回 NULL。
根据 SQL 标准,MySQL 支持两个通配符:
- 百分号(%)匹配零个或多个任意字符。
- 下划线(_)匹配一个任意字符。
例如,以下语句用于查询“关”姓员工:
select emp_name
from employee
where emp_name like '关%';
emp_name|
----------|
关兴 |
关平 |
关羽 |其中,“关%”表示以“关”字开始的字符串。另外,“%xyz%”表示包含 xyz 的字符串;“%xyz”表示以 xyz 结束的字符串。
以下语句演示了下划线的作用:
select emp_name
from employee
where emp_name like '孙__';
emp_name|
----------|
孙丫鬟 |
孙尚香 |其中,“孙__”表示以“孙”字开始并且姓名为三个字的员工;因此查询结果中没有包含“孙乾”。
转义字符
由于百分号和下划线是通配符,具有特殊的意义。当我们想要判断字符串中是否包含这两个字符时,例如“50%”,就需要使用一个转义字符将模式中的通配符解释为普通字符。转义字符使用ESCAPE进行指定:
expr LIKE pat ESCAPE 'escape_char'默认情况下,MySQL 使用反斜线(\)作为转义字符。例如:
select '完成进度:50% 已完成。' like '%50%%' as like1, '日期 20150101' like '%50%%' as like2;
like1|like2|
-----|-----|
1| 1|
select '完成进度:50% 已完成。' like '%50\%%' as like1, '日期 20150101' like '%50\%%' as like2;
like1|like2|
-----|-----|
1| 0|第一个查询没有使用转义字符,直接使用“50%” 进行匹配,结果“日期 20150101”也满足条件;第二个查询使用转义字符,“50\%”只匹配百分之五十(50%)。
我们也可以指定其他的转义字符,例如:
select '2020_06_13' like '%06#_13%' escape '#' as like3;
like3|
-----|
1|以上语句使用“#”作为转义字符。此时如果字符串中存在“#”,需要连写两个“#”表示匹配井号自身。
另外,需要注意 MySQL 中的LIKE运算符不区分大小写。例如:
select 'Tony' like 'tony';
'Tony' like 'tony'|
------------------|
1|如果想要实现区分大小写的匹配,可以使用下文中的REGEXP_LIKE函数。
NOT LIKE运算符可以进行反向模式匹配。例如:
select emp_name, email
from employee
where email not like '%a%';
emp_name|email |
----------|------------------|
刘备 |liubei@shuguo.com |
糜竺 |mizhu@shuguo.com |
邓芝 |dengzhi@shuguo.com|该语句返回了 email 中不包含字母 a 的员工。
正则表达式匹配
LIKE 运算符可以实现简单的模式匹配。但是当我们需要匹配更复杂的模式时,例如判断用户输入的电子邮箱是否合法,则无法通过 LIKE 运算符实现。为此, MySQL 提供了更加强大的正则表达式(Regular Expression)函数和运算符。
正则表达式是一个包含字母、数字和特殊符号的模式,可以用于检索或者替换符合某个模式(规则)的文本字符串。正则表达式可以用于查找电子邮箱、IP 地址、身份证等具有特定规则的数据,也可以用于验证用户名是否符合指定规则(例如只包含字符、数字、下划线并且字符数量为某个范围)。
关于正则表达式的具体内容可以参考 GitHub上的正则表达式教程。
MySQL 提供以下三种的正则表达式匹配函数和运算符:
REGEXP_LIKE(expr, pat[, match_type])
expr REGEXP pat
expr RLIKE pat如果字符串 expr 匹配模式 pat 指定的正则表达式,返回 Ture(1),否则返回 False(0)。如果 expr 或者 pat 为 NULL,返回 NULL。可选参数 match_type 可以用于指定匹配方式,可以是以下选项之一或者全部:
- c:区分大小写;
- i:不区分大小写,默认方式;
- m:多行匹配,可以识别字符串内部的行终止符。默认情况下只在字符串的开始或结束匹配行终止符;
- n:点号( . )匹配行终止符。默认情况下,点号遇到一行的结束时会终止匹配;
- u:只匹配 Unix 行终止符,此时只有换行符被 .、^ 和 $ 看作一行的结束。
REGEXP 和 RLIKE 运算符实际上是 REGEXP_LIKE 函数的同义词,但是不支持 match_type 匹配选项,而是使用默认选项。
我们看一个区分大小写的匹配示例:
select regexp_like('Tony', 'tony') as regexp1, regexp_like('Tony', 'tony', 'c') as regexp2;
regexp1|regexp2|
-------|-------|
1| 0|默认情况下不区分大小写,所以返回了 1;c 选项表示区分大小写,因此返回了 0。
正则表达式的强大之处在于它提供了许多元字符(metacharacter),可以用于构造复杂的模式。下表列出了 MySQL 支持的元字符:
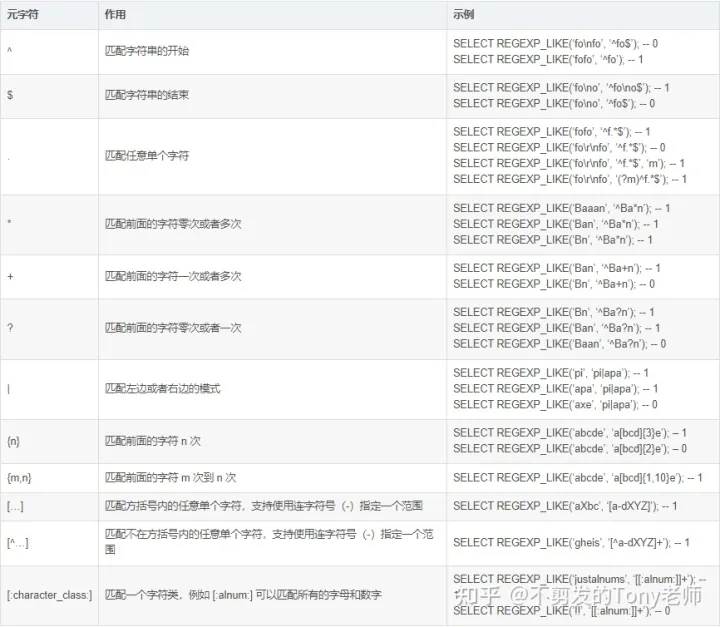
对于 Web 开发中常见邮箱地址合法性验证,可以采用以下简单的规则:
- 以字母或者数字开头;
- 后面是一个或者多个字母、数组或特殊字符( . _ - );
- 然后是一个 @ 字符;
- 之后包含一个或者多个字母、数组或特殊字符( . - );
- 最后是域名,即 . 以及 2 到 4 个字母。
使用正则表达式可以表示为:
^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,4}$其中,^ 匹配字符串的开头;[a-zA-Z0-9] 匹配大小写字母或数字;+ 表示匹配前面的内容一次或多次;. 匹配任何一个字符,\. 匹配点号自身;{2,4} 匹配前面的内容 2 次到 4次;$ 匹配字符串的结束。
我们创建一个测试表:
CREATE TABLE t_regexp (
email VARCHAR(50)
);
INSERT INTO t_regexp VALUES ('TEST@shuguo.com');
INSERT INTO t_regexp VALUES ('test@shuguo');
INSERT INTO t_regexp VALUES ('.123@shuguo.com');
INSERT INTO t_regexp VALUES ('test+email@shuguo.cn');
INSERT INTO t_regexp VALUES ('me.me@ shuguo.com');
INSERT INTO t_regexp VALUES ('123.test@shuguo-sanguo.org');使用以下语句查找合法的邮箱地址:
SELECT email
FROM t_regexp
WHERE REGEXP_LIKE(email, '^[a-zA-Z0-9]+[a-zA-Z0-9._-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,4}$');
email |
--------------------------|
TEST@shuguo.com |
123.test@shuguo-sanguo.org|查询返回了两个合法的邮箱地址。注意其中的转义字符需要使用两个反斜线(\),因为 MySQL 解析器会解析一个反斜线,正则表达式会解析另一个。
expr NOT REGEXP pat和expr NOT RLIKE pat可以用于执行反向模式匹配。
数据排序
默认情况下,SELECT语句不会对返回的结果进行排序,意味着查询结果的显示顺序是不确定的。如果想要将结果按照某种规则进行排序,例如按照入职先后顺序显示员工的信息,可以使用ORDER BY子句。
基于单个字段排序
按照单个字段的值进行排序称为单列排序。单列排序的语法如下:
SELECT col1, col2, ...
FROM table_name
[WHERE conditions]
ORDER BY col1 [ASC | DESC];其中,ORDER BY用于指定排序的字段;ASC表示升序排序(Ascending),DESC表示降序排序(Descending),默认值为升序排序。
例如,以下查询按照员工的入职先后顺序进行排序显示:
select emp_name, hire_date
from employee
order by hire_date;
emp_name|hire_date |
---------|----------|
关羽 |2000-01-01|
张飞 |2000-01-01|
刘备 |2000-01-01|
孙尚香 |2002-08-08|
孙丫鬟 |2002-08-08|
赵云 |2005-12-19|
...对于升序排序,数字按照从小到大的顺序排列,字符按照编码的顺序排列,日期时间按照从早到晚的顺序排列;降序排序正好相反。
在上面的查询结果中,入职日期为 2000-01-01 的员工有 3 位。那么他们谁排在前面,谁排在后面呢?答案是不确定。如果要解决这个问题,需要使用多列排序。
基于多个字段排序
多列排序是指基于多个字段的值排序,多个字段使用逗号进行分隔。多列排序的语法如下:
SELECT col1, col2, ...
FROM table_name
[WHERE conditions]
ORDER BY col1 [ASC | DESC], col2 [ASC | DESC], ...;执行过程中,先基于第一个字段进行排序;对于第一个字段排序相同的数据,再基于第二个字段进行排序;依此类推。
例如,以下语句查询行政管理部(dept_id = 1)的员工信息;按照入职先后进行排序,入职日期相同再按照月薪从高到低排序:
select emp_name, sex, hire_date, salary
from employee
where dept_id = 1
order by hire_date asc, salary desc;
emp_name|sex |hire_date |salary |
---------|----|----------|--------|
刘备 |男 |2000-01-01|30000.00|
关羽 |男 |2000-01-01|26000.00|
张飞 |男 |2000-01-01|24000.00|基于表达式排序
select emp_name, salary, bonus, salary * 12 + ifnull(bonus, 0) as total_income
from employee
order by total_income;
emp_name|salary |bonus |salary * 12 + ifnull(bonus, 0)|
emp_name|salary |bonus |total_income|
---------|--------|--------|------------|
邓芝 | 4000.00| | 48000.00|
蒋琬 | 4000.00| 1500.00| 49500.00|
黄权 | 4200.00| | 50400.00|
庞统 | 4100.00| 2000.00| 51200.00|
糜竺 | 4300.00| | 51600.00|
孙乾 | 4700.00| | 56400.00|
...其中,ifnull(bonus, 0) 函数用于将 bonus 为空的数据转换为 0。
另外,在指定排序字段时,除了使用字段名或者表达式之外,也可以使用它们在查询列表中出现的数字编号顺序。上面的示例可以改写如下:
select emp_name, salary, bonus, salary * 12 + ifnull(bonus, 0) as total_income
from employee
order by 4;在查询列表中,total_income 是返回的第 4 个字段;因此该语句也是按照年度总收入从低到高进行排序。
空值排序
空值(NULL)在 SQL 中表示未知或者缺失的值。如果排序的字段中存在空值时,结果会怎么样呢?以下语句按照奖金从高到低进行排序:
select emp_name, bonus
from employee
where dept_id = 3
order by bonus desc;
emp_name|bonus |
----------|-------|
孙尚香 |5000.00|
孙丫鬟 | |从查询结果可以看到,空值排在了最后。也就是说,MySQL 认为空值最小,升序时排在最前,降序时排在最后。
如果想要调整空值的排序位置,可以使用函数(例如 ifnull)将空值转换为一个指定的值。例如,以下语句将奖金为空的数据转换为 0:
select emp_name, ifnull(bonus, 0) as bonus
from employee
where dept_id = 3
order by ifnull(bonus, 0);
emp_name|bonus |
----------|-------|
孙丫鬟 | 0.00|
孙尚香 |5000.00|中文排序
我们可以为数据库、表或者字段指定一个字符集(Charset)和排序规则(Collation)。字符集决定了能够存储哪些字符,比如 ASCII 字符集只能存储简单的英文、数字和一些控制字符;GB2312 字符集可以存储中文;Unicode 字符集能够支持世界上的各种语言。
排序规则定义了字符集中字符的排序顺序,包括是否区分大小写,是否区分重音等。对于中文而言,排序方式与英文有所不同;中文通常需要按照拼音、偏旁部首或者笔画进行排序。
MySQL 8.0 默认使用 utf8mb4 字符编码,默认的排序规则为 utf8mb4_0900_ai_ci,对于中文按照偏旁部首进行排序。以下语句按照员工的姓名进行排序:
select emp_name, email
from employee
where dept_id = 5
order by emp_name;
emp_name|email |
---------|--------------------|
孙乾 |sunqian@shuguo.net |
庞统 |pangtong@shuguo.com |
法正 |fazheng@shuguo.com |
简雍 |jianyong@shuguo.com |
糜竺 |mizhu@shuguo.com |
蒋琬 |jiangwan@shuguo.com |
邓芝 |dengzhi@shuguo.com |
黄权 |huangquan@shuguo.com|如果想要按照拼音进行排序,可以指定排序规则。例如:
select emp_name, email
from employee
where dept_id = 5
order by emp_name collate 'utf8mb4_zh_0900_as_cs';
emp_name|email |
---------|--------------------|
邓芝 |dengzhi@shuguo.com |
法正 |fazheng@shuguo.com |
黄权 |huangquan@shuguo.com|
简雍 |jianyong@shuguo.com |
蒋琬 |jiangwan@shuguo.com |
糜竺 |mizhu@shuguo.com |
庞统 |pangtong@shuguo.com |
孙乾 |sunqian@shuguo.net |按照拼音进行排序的另一种方法就是将数据转换为其他字符集。例如 gbk:
select emp_name, email
from employee
where dept_id = 5
order by convert(emp_name using gbk);
emp_name|email |
---------|--------------------|
邓芝 |dengzhi@shuguo.com |
法正 |fazheng@shuguo.com |
黄权 |huangquan@shuguo.com|
简雍 |jianyong@shuguo.com |
蒋琬 |jiangwan@shuguo.com |
糜竺 |mizhu@shuguo.com |
庞统 |pangtong@shuguo.com |
孙乾 |sunqian@shuguo.net |CONVERT 是一个函数,用于转换数据的字符集编码;这里是中文 GBK 字符集,默认使用拼音排序。当然,我们也可以在创建数据库或者表(字段)时指定支持中文排序的排序规则,查询时就不需要再做任何操作了。
自定义排序
自定义排序可以按照我们预先定义好的特定顺序进行排序,关键在于如何定义每个数据的顺序。例如,以下查询通过 field() 函数实现自定义的排序:
select emp_name, field(emp_name, '刘备','关羽','张飞') as num
from employee
where dept_id = 1
order by field(emp_name, '刘备','关羽','张飞');
emp_name|num|
---------|---|
刘备 | 1|
关羽 | 2|
张飞 | 3|通过查询结果可以看出,field(str,str1,str2,str3,...) 函数返回了 str 在后续列表中的下标位置,没有匹配到数据时返回 0。以上示例实际上相当于将“刘备”编号为 1,“关羽”编号为 2,“张飞”编号为 3。
除了 field() 函数之外,我们还可以通过 CASE 表达式实现类似的转换逻辑,在后续文章中会介绍 CASE 表达式的作用。
另一种实现自定义排序的方法就是在表中增加一个额外的排序字段,为数据设置不同的数字,然后通过这个字段进行排序。例如,应用程序中的菜单就可以通过这种方式进行排序显示。
限制查询结果数量
MySQL 中的LIMIT子句可以用于限制查询返回结果的数量,从而实现常见的 Top-N 查询和分页查询等功能。
在 SQL 标准中,定义了 FETCH子句实现查询结果数量的限制。如果使用 Oracle、SQL Server 或者 PostgreSQL,可能会见到这种语法。
LIMIT 子句
在查询语句中使用LIMIT子句的语法如下:
SELECT col1, col2, ...
FROM table_name
[WHERE conditions]
[ORDER BY ...]
LIMIT [off_set,] row_count;其中:
- off_set 指定一个行偏移量,从第 off_set + 1 行开始返回数据。默认值为 0,表示从第一行开始返回。
- row_count 指定返回记录的上限数量。
这两个参数都必须是大于等于 0 的整数。例如,以下查询返回了 10 位员工的信息:
select emp_name, sex
from employee
limit 10;
emp_name|sex |
---------|----|
刘备 |男 |
关羽 |男 |
张飞 |男 |
诸葛亮 |男 |
黄忠 |男 |
魏延 |男 |
孙尚香 |女 |
孙丫鬟 |女 |
赵云 |男 |
廖化 |男 |除了以上语法形式的LIMIT子句之外,MySQL 也支持以下写法(兼容 PostgreSQL):
LIMIT row_count OFFSET off_set因此,上面的示例也可以写成:
select emp_name, sex
from employee
limit 10 offset 0;一般而言,LIMIT子句很少单独使用,而是和ORDER BY子句一起返回更有意义的数据。
Top-N 查询
Top-N 查询通常用于返回按照指定规则排序之后的前 N 条记录,例如销售排行榜。
以下查询用于获取最先入职的前 5 名员工:
select emp_name, hire_date
from employee
order by hire_date
limit 5;
emp_name |hire_date |
----------|----------|
刘备 |2000-01-01|
关羽 |2000-01-01|
张飞 |2000-01-01|
孙尚香 |2002-08-08|
孙丫鬟 |2002-08-08|执行该语句时,先按照 hire_date 从早到晚进行排序;然后通过LIMIT子句限制返回前 5 条记录。如果将 hire_date 降序排序,可以获取到目前为止最后入职的 5 名员工。
这种返回 Top-N 的方式存在一个局限性,就是如果最后有多条记录排名相同,只能随机选择其中一些数据返回。这个问题我们可以利用窗口函数解决,在后续文章中会介绍 MySQL 8.0 新增的窗口函数。
分页查询
在应用程序的前端页面中,通常不会直接显示全部数据,而是采用分页显示的方式。
首先会返回一个记录总数,然后每页显示 15 条记录,并且提供“上一页”、“下一页”等跳转功能。返回总数的方法就是使用 COUNT(*) 函数,例如:
select count(*)
from employee;
count(*)|
--------|
25|员工表中总共有 25 条记录,COUNT(*) 属于聚合函数。
然后就是通过LIMIT子句获取指定页码中对应的数据,实现的方法就是排序后跳过指定的行数,再返回 Top-N 记录。假如我们需要按照月薪从高到低显示员工信息,每页显示 10 条记录;意味着最多需要 3 页。以下查询可以用于返回第 3 页的数据(第 21 到第 25 条记录):
select emp_id,emp_name, sex, hire_date,salary
from employee
order by salary desc
limit 20, 10;
emp_id|emp_name |sex |hire_date |salary |
------|---------|----|----------|-------|
22|糜竺 |男 |2018-03-27|4300.00|
21|黄权 |男 |2018-03-14|4200.00|
19|庞统 |男 |2017-06-06|4100.00|
20|蒋琬 |男 |2018-01-28|4000.00|
23|邓芝 |男 |2018-11-11|4000.00|由于第 3 页是最后一页,返回的结果数量只有 5 条。
对于应用程序而言,传递给数据库的参数 off_set 等于(页码 - 1)乘以每页显示的记录数,参数 row_count 就是每页显示的记录数。
返回指定名次
基于分页查询的实现,我们还可以获取指定名次的数据,也就是第 N 行数据。例如,以下查询返回了销售部奖金第 2 高的员工:
select emp_id,emp_name, bonus
from employee
where dept_id = 5
order by bonus desc
limit 1, 1;
emp_id|emp_name |bonus |
------|----------|-------|
19|庞统 |2000.00|销售部所有员工按照奖金从高到低的排名结果如下:
select emp_id,emp_name, bonus
from employee
where dept_id = 5
order by bonus desc;
emp_id|emp_name |bonus |
------|----------|-------|
18|法正 |5000.00|
19|庞统 |2000.00|
20|蒋琬 |1500.00|
21|黄权 | |
22|糜竺 | |
23|邓芝 | |
24|简雍 | |
25|孙乾 | |分组统计
聚合函数
在 SQL 中,聚合函数(Aggregate Function)用于对一组数据进行汇总计算,并且返回单个分析结果。例如,公司中的员工总数、所有员工的平均月薪等。MySQL 中常见的聚合函数包括:
- COUNT,返回查询结果的行数;
- AVG,计算一组数值的平均值;
- SUM,计算一组数值的总和;
- MAX ,计算一组数据中的最大值;
- MIN,计算一组数据中的最小值;
- GROUP_CONCAT,连接一组字符串。
例如,以下查询返回了公司中的员工总数、平均月薪、最高月薪、最低月薪以及所有员工的月薪总和:
select count(*) "员工数量",
avg(salary) "平均月薪",
max(salary) "最高月薪",
min(salary) "最低月薪",
sum(salary) "月薪总和"
from employee;
员工数量|平均月薪 |最高月薪 |最低月薪 |月薪总和 |
-------|-----------|--------|-------|---------|
25|9912.000000|30000.00|4000.00|247800.00|以下查询返回了行政管理部所有员工的姓名组成的字符串:
select group_concat(emp_name) "所有员工",
group_concat(emp_name order by salary separator ':') "所有员工"
from employee
where dept_id = 1;
所有员工 |所有员工 |
------------|------------|
刘备,关羽,张飞|张飞:关羽:刘备|第一个 group_concat 函数使用默认的参数和分隔符,第二个 group_concat 函数指定了字符串的连接顺序和分隔符。
使用聚合函数时需要注意两点:
- 在聚合函数的参数中加上 DISTINCT 关键字,可以在计算之前排除重复值。例如,当 AVG 函数中包含 DISTINCT 参数时,在计算平均值之前会排除掉重复值。因此,(1、1、2)的平均值为 (1 + 2) / 2 = 1.5,而不是 (1 + 1 + 2) / 3 = 1.33。
- 聚合函数在计算时,忽略输入值为 NULL 的数据行;COUNT(*) 除外。例如,当 AVG 函数中存在空值时,计算之前会忽略这些空值。因此,(1,2,NULL)的平均值为 (1 + 2) / 2 = 1.5,而不是 (1 + 2) / 3 = 1。
例如:
select count(*),
count(distinct sex),
count(bonus)
from employee;
count(*)|count(distinct sex)|count(bonus)|
--------|-------------------|------------|
25| 2| 9|其中,COUNT(*) 返回了员工的总数;count(distinct sex) 返回了不同性别的种类(男、女);count(bonus) 返回了拥有奖金的员工数量,只有 9 名员工有奖金。
聚合函数的完整语法如下:
aggregate_function( [ALL | DISTINCT] expression)其中,ALL 表示计算时不排除重复值。这是默认行为,通常省略。
聚合函数单独使用时,只能返回所有数据的整体汇总结果。如果我们想要按照不同的分组进行统计,例如按照部门统计员工的平均薪水、员工数量等,就要将聚合函数和GROUP BY分组子句一起使用。
分组统计
GROUP BY 子句可以将数据按照某种规则进行分组,并且为每一个组返回一条记录。在查询语句中使用分组子句的语法如下:
SELECT col1,
col2,
aggregate_function(expression)
FROM table_name
[WHERE conditions]
GROUP BY col1, col2;例如,以下查询返回了不同部门中的员工数量和月薪总和:
select dept_id, count(*), sum(salary)
from employee
group by dept_id;
dept_id|count(*)|sum(salary)|
-------|--------|-----------|
1| 3| 80000.00|
2| 3| 41500.00|
3| 2| 18000.00|
4| 9| 68200.00|
5| 8| 40100.00|以下语句同时按照部门和性别统计员工的数量:
select dept_id, sex, count(*)
from employee
group by dept_id, sex;
dept_id|sex |count(*)|
-------|----|--------|
1|男 | 3|
2|男 | 3|
3|女 | 2|
4|男 | 8|
4|女 | 1|
5|男 | 8|以下语句统计了每年入职的员工数量:
select extract(year from hire_date) as "入职年份",
count(*) as "员工数量"
from employee
group by extract(year from hire_date);
入职年份|员工数量|
----|----|
2000| 3|
2006| 1|
2008| 1|
2007| 1|
2002| 2|
2005| 1|
2009| 1|
2011| 3|
2012| 2|
2010| 1|
2014| 1|
2017| 2|
2018| 5|
2019| 1|GROUP BY 支持使用表达式进行分组。EXTRACT 函数用于提取日期中的年份信息。
另外,GROUP BY 也可以使用字段在 SELECT 列表中出现的次序指定分组方式。上面的示例可以改写如下:
select extract(year from hire_date) as "入职年份",
count(*) as "员工数量"
from employee
group by 1;extract(year from hire_date) 是查询返回的第 1个字段;因此该语句也是按照年度统计入职的员工数量。
如果GROUP BY后的分组字段存在 NULL 值,多个 NULL 值将被看作一个分组。以下语句按照不同奖金值统计员工的数量:
SELECT bonus, COUNT(*)
FROM employee
GROUP BY bonus;
bonus |COUNT(*)|
--------|--------|
10000.00| 3|
8000.00| 1|
[NULL]| 16|
5000.00| 2|
6000.00| 1|
2000.00| 1|
1500.00| 1|从查询结果可以看出,16 个员工没有奖金;但是他们都被分组同一个组中,而不是多个不同的组。
在使用分组汇总时,初学者常见的一个错误就是在 SELECT 列表中使用了既不是聚合函数,也不属于分组字段的字段。例如:
-- GROUP BY 错误示例
select dept_id, emp_name, avg(salary)
from employee
group by dept_id;
ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'hrdb.employee.emp_name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by以上语句返回了一个错误:字段 emp_name 没有出现在 GROUP BY 子句或者聚合函数中。原因在于该查询按照部门进行分组,但是每个部门包含多个员工;因此无法确定需要显示哪个员工的姓名。
MySQL 通过 SQL 模式参数 ONLY_FULL_GROUP_BY 控制该行为,默认值表示遵循 SQL 标准;如果禁用该参数,以上示例不会出错。
另外,MySQL 也可以通过 ANY_VALUE 函数返回一个随机的数据,可以避免以上错误:
select dept_id, any_value(emp_name), avg(salary)
from employee
group by dept_id;
dept_id|any_value(emp_name)|avg(salary) |
-------|-------------------|------------|
1|刘备 |26666.666667|
2|诸葛亮 |13833.333333|
3|孙尚香 | 9000.000000|
4|赵云 | 7577.777778|
5|法正 | 5012.500000|需要小心的是,any_value 函数返回的数据是不确定的。
分组过滤
当我们需要对分组后的数据再次进行过滤,例如找出人数多于 5 个的部门时,如果在 WHERE 子句中增加一个过滤条件:
select dept_id, count(*)
from employee
where count(*) > 5
group by dept_id;
ERROR 1111 (HY000): Invalid use of group function该语句执行出错。错误的原因在于 WHERE 子句在 GROUP BY 子句之前执行,此时还没有计算聚合函数,因此它只能基于分组之前的数据进行过滤。如果需要对分组后的结果进行过滤,需要使用HAVING子句。以上查询的正确写法如下:
select dept_id, count(*)
from employee
group by dept_id
having count(*) > 5;
dept_id|count(*)|
-------|--------|
4| 9|
5| 8|HAVING 子句位于 GROUP BY 之后,并且必须与 GROUP BY 一起使用。
我们可以使用 WHERE 子句对表进行过滤,同时使用 HAVING 对分组结果进行过滤。例如,以下语句返回了存在 2 名以上女性员工的部门:
select dept_id, count(*) cnt
from employee
where sex = '女'
group by dept_id
having cnt >= 2;
dept_id|cnt|
-------|---|
3| 2|首先通过 WHERE子句找出女性员工;然后,按照部门编号进行分组,计算每个组内的员工数量;最后,使用 HAVING 子句过滤员工数量等于或多于 2 个人的部门。MySQL 允许在 HAVING 子句中使用列的别名(cnt)进行过滤。
到目前为止,我们学习过的完整查询语句如下:
SELECT col1,
col2,
aggregate_function(expression)
FROM table_name
WHERE conditions
GROUP BY col1, col2
HAVING conditions
ORDER BY col1 [ASC | DESC], col2 [ASC | DESC], ...
LIMIT [off_set,] row_count;对于以上各个子句,MySQL 的逻辑执行顺序为 FROM、WHERE、SELECT、GROUP BY、HAVING、ORDER BY 以及 LIMIT。
高级分组
MySQL 中的 GROUP BY 子句还支持一个WITH ROLLUP选项,除了分组统计之外还会生成更高层级的汇总,类似于报表中的小计和总计。
首先创建一个销售数据表:
CREATE TABLE sales (
item VARCHAR(10),
year VARCHAR(4),
quantity INT
);
INSERT INTO sales VALUES('apple', '2018', 800);
INSERT INTO sales VALUES('apple', '2018', 1000);
INSERT INTO sales VALUES('banana', '2018', 500);
INSERT INTO sales VALUES('banana', '2018', 600);
INSERT INTO sales VALUES('apple', '2019', 1200);
INSERT INTO sales VALUES('banana', '2019', 1800);使用以下查询可以返回按照产品和年度统计的销量小计,按照产品统计的销量合计,以及所有产品的销量总计:
select item, year, sum(quantity)
from sales
group by item, year with rollup;
item |year|sum(quantity)|
------|----|-------------|
apple |2018| 1800|
apple |2019| 1200|
apple | | 3000|
banana|2018| 1100|
banana|2019| 1800|
banana| | 2900|
| | 5900|其中,第三行数据表示 apple 在所有年度的销量合计;最后一行表示所有产品在所有年度的销量总计。
对于以下形式的 WITH ROLLUP 而言:
GROUP BY col1, col2 WITH ROLLUP实际上等价于以下三种分组统计的结果相加:
GROUP BY col1, col2
GROUP BY col1
GROUP BY null使用了 WITH ROLLUP 选项之后,会产生一些数据为 NULL 的结果,表示相应字段上的汇总结果。但是这种显示方式意义不明确,而且如果原数据也有 NULL 数据,则无法进行区分。因此 MySQL 提供了GROUPING()函数。
如果某个数据是汇总的小计或者总计,GROUPING() 函数返回 1;否则,返回 0。例如:
select item, year, sum(quantity), grouping(item), grouping(year), grouping(item, year)
from sales
group by item, year with rollup;
item |year|sum(quantity)|grouping(item)|grouping(year)|grouping(item, year)|
------|----|-------------|--------------|--------------|--------------------|
apple |2018| 1800| 0| 0| 0|
apple |2019| 1200| 0| 0| 0|
apple | | 3000| 0| 1| 1|
banana|2018| 1100| 0| 0| 0|
banana|2019| 1800| 0| 0| 0|
banana| | 2900| 0| 1| 1|
| | 5900| 1| 1| 3|其中,第三行数据是按照年度计算的合计,grouping(item) 返回 0,grouping(year) 返回 1;最后一行是所有产品在所有年度的销量总计,grouping(item) 返回 1,grouping(year) 返回 1。grouping(item, year) 的计算方式是 grouping(item) * 2 + grouping(year)。
对于 grouping(col1, col2, col3),计算的方式如下:
grouping(col1) * 4 + grouping(col2) * 2 + grouping(col3)我们可以将上面的示例修改如下:
select if(grouping(item) = 1, '所有产品', item) as "产品",
if(grouping(year) = 1, '所有年度', item) as "年度",
sum(quantity) as "销量"
from sales
group by item, year with rollup;
产品 |年度 |销量 |
---------|---------|----|
apple |apple |1800|
apple |apple |1200|
apple |所有年度 |3000|
banana |banana |1100|
banana |banana |1800|
banana |所有年度 |2900|
所有产品 |所有年度 |5900|其中,IF(expr1,expr2,expr3) 函数当 expr1 为 TRUE 时(expr1 <> 0 and expr1 <> NULL)返回 expr2 的值;否则,返回 expr3 的值。
GROUPING() 函数可以用于 SELECT 列表、HAVING 子句以及 ORDER BY 子句中。
多表连接查询
关系型数据库通常采用规范化的设计方式,将不同的实体对象和它们之间的联系存储到多个表中。比如员工的个人信息存储在 employee 表中,部门相关的信息存储在 department 表中,同时 employee 表中存在一个外键字段(dept_id),引用了 department 表的主键字段。
因此,当我们想要查看员工的个人信息以及他/她所在的部门信息,就需要同时查询 employee 和 department 表中的信息。此时,我们需要使用连接查询。连接查询(join)可以基于两个表中的连接字段将数据行拼接到一起,返回两个表中的相关数据。
以下查询返回了人力资源部门中的所有员工信息:
select d.dept_id,
e.dept_id,
dept_name,
e.emp_name,
e.sex
from employee e
join department d on e.dept_id = d.dept_id
where dept_name = '人力资源部';其中, JOIN 表示连接查询,连接 employee 表和 department 表;ON 用于指定连接条件,这里表示 employee 中的部门编号等于 department 的部门编号。另外,查询语句中的 e 和 d 都是表的别名,当存在两个同名的字段时可以通过别名指定字段的来源。
该查询返回的结果如下:
dept_id|dept_id|dept_name |emp_name |sex|
-------|-------|-------------|-----------|---|
2| 2|人力资源部 |诸葛亮 |男 |
2| 2|人力资源部 |黄忠 |男 |
2| 2|人力资源部 |魏延 |男 |以上示例使用 JOIN 和 ON 关键字指定表的连接查询,属于 ANSI SQL/92 标准语法;对于该查询,也可以使用 FROM 和 WHERE 实现如下:
select d.dept_id,
e.dept_id,
dept_name,
e.emp_name,
e.sex
from employee e, department d
where dept_name = '人力资源部'
and e.dept_id = d.dept_id;这种使用 FROM 和 WHERE 关键字指定表的连接属于 ANSI SQL/86 标准。
推荐使用 JOIN 和 ON 进行连接查询,它们的语义更清晰,更符合 SQL 的声明性;另外,当 WHERE 中包含多个查询条件,又用于指定表的连接关系时,会显得比较混乱。
MySQL 支持以下 SQL 连接查询:
- 内连接(INNER JOIN);
- 左外连接(LEFT OUTER JOIN);
- 右外连接(RIGHT OUTER JOIN);
- 交叉连接(CROSS JOIN);
- 自然连接(NATURAL JOIN);
- 自连接(Self Join)。
其中,左外连接和右外连接都属于外连接(OUTER JOIN);MySQL 目前还不支持 SQL 全外连接(FULL OUTER JOIN)。
连接查询中的 ON 子句与 WHERE 子句类似,可以支持各种条件运算符(=、>=、!=、BETWEEN 等)。但最常用的是等值连接(=),我们主要介绍这种条件的连接查询。
内连接
内连接用于返回两个表中都满足连接条件的数据,使用关键字INNER JOIN表示,也可以简写成JOIN; 以下是内连接的示意图(基于两个表的 id 进行等值连接):

其中,id = 1 和 id = 3 是两个表中匹配( table1.id = table2.id )的数据,因此内连接返回了 2 行记录。上文已经给出了内连接的示例,不再重复。
左外连接
左外连接返回左表中所有的数据行;对于右表,如果没有匹配的数据,显示为空值。左外连接使用关键字LEFT OUTER JOIN表示,也可以简写成LEFT JOIN。 左外连接可以参考以下示意图(基于两个表的 id 进行等值连接):

查询首先返回左表中的全部数据(id 等于 1、2、3)。由于 id = 2 在 table2 中不存在对应的数据,对于 table2 中的字段返回空值。
由于某些部门刚刚成立,可能还没有员工,因此前面的内连接查询不会显示这些部门的信息。如果想要在连接查询中返回这些部门的信息,需要使用左外连接:
select d.dept_id, e.dept_id, d.dept_name, e.emp_name
from department d
left join employee e on (e.dept_id = d.dept_id)
order by d.dept_id desc;查询结果如下:
dept_id|dept_id|dept_name |emp_name |
-------|-------|-----------|----------|
6| |保卫部 | |
5| 5|销售部 |法正 |
5| 5|销售部 |庞统 |
5| 5|销售部 |蒋琬 |
5| 5|销售部 |黄权 |
...从结果可以看出,“保卫部”目前还没有任何员工。
右外连接
右外连接返回右表中所有的数据行;对于左表,如果没有匹配的数据,显示为空值。右外连接使用关键字RIGHT OUTER JOIN表示,也可以简写成RIGHT JOIN; 右外连接可以参考以下示意图(基于两个表的 id 进行等值连接):
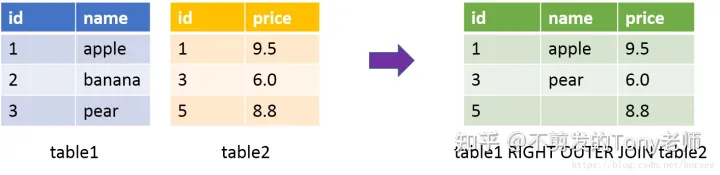
查询首先返回右表中的全部数据(id 等于 1、3、5)。由于 id = 5 在 table1 中不存在对应的数据,对于 table1 中的字段返回空值。 也就是说:
table1 RIGHT JOIN table2等价于
table2 LEFT JOIN table1因此,上面的查询也可以使用右外连接来表示:
select d.dept_id, e.dept_id, d.dept_name, e.emp_name
from employee e
right join department d on (e.dept_id = d.dept_id)
order by d.dept_id desc;该语句返回的结果和上文中的左连接示例相同。
全外连接
SQL 全外连接等效于左外连接加上右外连接,返回左表和右表中所有的数据行。全外连接使用关键字FULL OUTER JOIN表示,也可以简写成FULL JOIN。全外连接的示意图如下(基于两个表的 id 进行连接):
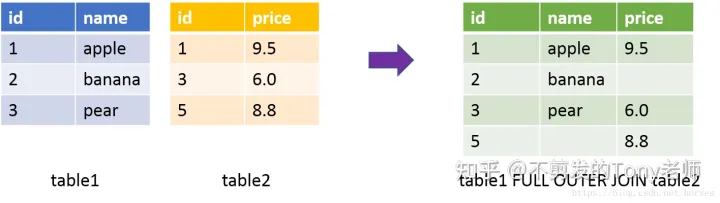
查询首先返回两个表中匹配的数据(id 等于 1 和 3,只返回一次);对于 table1 中的 id = 2,table2 中的对应字段(price)显示为空;对于 table2 中的 id = 5,对应的 table1 中的字段(name)显示为空。
MySQL 目前还不支持全外连接,但是可以通过左/右外连接进行模拟。例如:
select *
from
(select 1 as id) t1
left join (select 2 as id) t2 on t1.id = t2.id;
id|id|
--|--|
1| |以上左连接查询返回了 t1 中的数据,如果换成右连接则只返回 t2 中的数据,使用以下语句可以同时返回两个表中的数据:
select *
from
(select 1 as id) t1
left join (select 2 as id) t2 on t1.id = t2.id
union all
select *
from
(select 1 as id) t1
right join (select 2 as id) t2 on t1.id = t2.id
where t1.id is null;
id|id|
--|--|
1| |
| 2|其中,union all 表示将两个查询的结果合并成一个更大的结果。第二个 select 语句中的 where 条件用于排除两次查询中重复返回的数据。(union all并不会排除重复行)
对于外连接,需要注意WHERE条件和ON条件之间的差异:ON条件是针对连接之前的数据进行过滤,WHERE是针对连接之后的数据进行过滤,同一个条件放在不同的子句中可能会导致不同的结果。
以下示例将部门表与员工表进行左外连接查询,并且在 ON 子句中指定了多个条件:
select d.dept_id, e.dept_id, d.dept_name, e.emp_name
from department d
left join employee e on (e.dept_id = d.dept_id and e.emp_id = 0);其中,ON 子句指定了一个不存在的员工( 编号为 0),因此员工表不会返回任何数据。但是由于查询指定的是左外连接,仍然会返回部门信息,查询结果如下:
dept_id|dept_id|dept_name |emp_name|
-------|-------|-------------|--------|
1| |行政管理部 | |
2| |人力资源部 | |
3| |财务部 | |
4| |研发部 | |
5| |销售部 | |
6| |保卫部 | |对于相同的查询条件,使用 WHERE 子句的示例如下:
select d.dept_id, e.dept_id, d.dept_name, e.emp_name
from department d
left join employee e on (e.dept_id = d.dept_id)
where e.emp_id = 0;该查询没有返回任何数据,因为左连接产生的结果经过 WHERE 条件(e.emp_id = 0)过滤之后没有任何满足的数据。
交叉连接
当连接查询没有指定任何连接条件时,就称为交叉连接。交叉连接使用关键字CROSS JOIN表示,也称为笛卡尔积(Cartesian product)。
两个表的笛卡尔积相当于一个表的所有行和另一个表的所有行两两组合,结果数量为两个表的行数相乘。假如第一个表有 100 行,第二个表有 200 行,它们的交叉连接将会产生 100 × 200 = 20000 行结果。交叉连接的示意图如下(基于两个表的 id 进行等值连接):

自然连接
对于连接查询,如果满足以下条件就可以使用USING替代ON子句,简化连接条件的输入:
- 连接条件是等值连接,即 t1.col1 = t2.col1;
- 两个表中的列必须同名同类型,即 t1.col1 和 t2.col1 的类型相同。
由于 employee 表和 department 表中的 dept_id 字段名称和类型都相同,可以使用USING简写前文中的内连接查询:
select d.dept_id,
e.dept_id,
dept_name,
e.emp_name,
e.sex
from employee e
join department d using (dept_id)
where dept_name = '人力资源部';其中,USING 表示使用两个表中的公共字段(dept_id)进行等值连接。查询语句中的公共字段不需要添加表名限定。
进一步来说,如果等值连接条件中包含了两个表中所有同名同类型的字段,可以使用自然连接(NATURAL JOIN)。例如,员工表和部门表只拥有 1 个同名字段 dept_id;因此上面的示例可以使用自然连接改写如下:
select d.dept_id,
e.dept_id,
dept_name,
e.emp_name,
e.sex
from employee e
natural join department d
where dept_name = '人力资源部';自然连接并不是一种新的连接方式,只是特定情况下的简写形式,也可以用于简化外连接查询。
自连接
自连接(Self join)是指连接操作符的两边都是同一个表,即把一个表和它自己进行连接。自连接本质上并没有什么特殊之处,主要用于处理那些对自己进行了外键引用的表。
例如,员工表中的经理字段(manager)是一个外键列,指向了员工表自身的员工编号字段(emp_id)。如果要显示员工姓名以及他们经理的姓名,可以通过自连接实现:
select e.emp_name as "员工姓名",
m.emp_name as "经理姓名"
from employee e
left join employee m on (m.emp_id = e.manager)
where e.dept_id = 1
order by e.emp_id;
员工姓名|经理姓名|
-------|--------|
刘备 | |
关羽 |刘备 |
张飞 |刘备 |该查询使用自连接关联了 2 次员工表,一个用于代表员工(e),另一个用于代表经理(m);连接条件是经理的员工编号等于员工的经理编号。这种情况下,必须使用表别名才能区分两个员工表。该查询使用了左外连接,因为“刘备”是该公司的老板,他没有上级。
子查询
子查询(Subquery)是指嵌套在其他 SQL 语句( SELECT、INSERT、UPDATE、DELETE 等)中的查询语句。子查询也称为内查询(inner query),必须位于括号之中;包含子查询的查询也称为外查询(outer query)。子查询支持多层嵌套,也就是子查询中包含其他子查询。
例如,以下语句返回了月薪大于平均月薪的员工:
select emp_name, salary
from employee
where salary > (
select avg(salary)
from employee
);其中,括号内部的子查询用于获得员工的平均月薪(9832.00);外查询用于返回月薪大于平均月薪的员工信息。该查询的结果如下:
emp_name |salary |
----------|--------|
刘备 |30000.00|
关羽 |26000.00|
张飞 |24000.00|
诸葛亮 |24000.00|
孙尚香 |12000.00|
赵云 |15000.00|
法正 |10000.00|MySQL 中的子查询可以分为以下三种类型:
- 标量子查询(Scalar Subquery):返回单个值(一行一列)的子查询。上面的示例就是一个标量子查询。
- 行子查询(Row Subquery):返回单行结果(一行多列)的子查询,标量子查询是行子查询的一个特例。
- 表子查询(Table Subquery):返回一个虚拟表(多行多列)的子查询,行子查询是表子查询的一个特例。
标量子查询
标量子查询的结果就像一个常量一样,可以用于 SELECT、WHERE、GROUP BY、HAVING 以及 ORDER BY 等子句中。对于上面的子查询示例,实际相当于先执行以下语句得到平均月薪:
select avg(salary)
from employee;
avg(salary)|
-----------|
9832.000000|然后将该值替换到外查询中:
select emp_name, salary
from employee
where salary > ( 9832 );行子查询
行子查询可以当作一个一行多列的临时表使用。以下语句查找所有与“黄忠”在同一个部门并且职位相同的员工:
select emp_name, dept_id, job_id
from employee
where (dept_id, job_id) = (select dept_id, job_id
from employee
where emp_name = '黄忠')
and emp_name != '黄忠';
emp_name|dept_id|job_id|
--------|-------|------|
魏延 | 2| 4|子查询返回了“黄忠”所在的部门编号和职位编号,这两个数值构成了一行数据;外部查询的 WHERE 条件使用该数据行进行过滤,AND 操作符用于排除“黄忠”自己。
行子查询可以使用以下比较运算符:=、>、<、>=、<=、<>、!=、<=>。如果行子查询产生多行记录将会返回错误,因为这些运算符只能和单个记录进行比较。
表子查询
当子查询返回的结果包含多行数据时,称为表子查询。表子查询通常用于 FROM 子句或者查询条件中。
派生表
当子查询出现在 FROM 子句中时,相当于创建了一个语句级别的临时表或者视图,也被称为派生表(derived table)。例如:
select d.dept_name as "部门名称",
coalesce(de.emp_number,0) as "员工数量"
from department d
left join (select dept_id,
count(*) as emp_number
from employee
group by dept_id) de
on (d.dept_id = de.dept_id);
部门名称 |员工数量|
----------|-------|
行政管理部| 3|
人力资源部| 3|
财务部 | 2|
研发部 | 9|
销售部 | 8|
保卫部 | 0|其中,left join 后面是一个派生表(必须指定别名,这里是 de),它包含了各个部门的编号和员工数量;然后将 department 与 de 进行左外连接查询,返回了部门信息和对应的员工数量。
IN操作符
当 WHERE 条件中的子查询返回多行数据时,不能再使用普通的比较运算符,因为它们不支持单个值和多个值的比较;如果想要判断某个字段是否在子查询返回的数据列表中,可以使用 IN 操作符。例如:
select emp_name
from employee
where job_id in (select job_id from job);子查询返回了所有的职位编号,in 操作符用于返回 job_id 等于其中任何一个编号的员工,因此结果会返回所有的员工。该语句等价于以下语句:
select emp_name
from employee
where job_id = 1
or job_id = 2
...
or job_id = 10;NOT IN 操作符执行和 IN 相反的操作,也就是当表达式不等于任何子查询返回结果时为 True。
ALL、ANY/SOME 操作符
除了 IN 运算符之外,ALL、ANY/SOME 运算符与比较运算符的结合也可以用于判断子查询的返回结果:
operand comparison_operator ALL (subquery)
operand comparison_operator ANY (subquery)
operand comparison_operator SOME (subquery)其中,comparison_operator 是比较运算符,包括 =、>、<、>=、<=、<>、!=。
ALL 和比较运算符一起使用表示将表达式和子查询的结果进行比较,如果比较的结果都为 True 时最终结果就为 True。例如:
select emp_name, salary
from employee
where salary > all (select e.salary
from employee e
join department d on (d.dept_id = e.dept_id)
where d.dept_name = '研发部');
emp_name|salary |
--------|--------|
刘备 |30000.00|
关羽 |26000.00|
张飞 |24000.00|
诸葛亮 |25000.00|其中,子查询返回了研发部所有员工的月薪;“> all”表示大于子查询结果中的所有值,也就是大于子查询结果中的最大值(15000)。
对于 ALL 操作符,有两个需要注意的情况,就是子查询结果为空或者存在 NULL 值。例如:
select emp_name, salary
from employee
where salary > all (select 999999 from dual where 1=0);以上查询会返回所有的员工,因为子查询返回结果为空集,外查询相当于没有 where 条件。
以下查询不会返回任何结果:
select emp_name, salary
from employee
where salary > all (select max(999999) from dual where 1=0);由于子查询返回一行数据 NULL,任何数值和 NULL 比较的结果都是未知(unknown ),所以外查询返回空集。
ANY/SOME 和比较运算符一起使用表示将表达式和子查询的结果进行比较,如果任何比较的结果为 True,最终结果就为 True。例如:
select emp_name
from employee
where job_id = any (select job_id from job);该语句等价于上面的 IN 操作符示例,也就是说 = ANY 和 IN 操作符等价。
另外,需要注意的是 NOT IN 等价于 <> ALL,而不是 <> ANY。因为“a not in (1,2,3)”和“a <> all (1,2,3)”等价于:
a <> 1 and a <> 2 and a <>3“a <> any (1,2,3)”等价于:
a <> 1 or a <> 2 or a <>3关联子查询
在上面的示例中,子查询和外查询之间没有联系,可以单独运行。这种子查询也称为非关联子查询(Non-correlated Subquery)。另一类子查询会引用外查询中的字段,从而与外部查询产生关联,也称为关联子查询(Correlated Subquery)。
以下示例通过使用关联子查询获得各个部门的员工数量:
select d.dept_name as "部门名称",
(select count(*)
from employee
where dept_id = d.dept_id) as "员工数量"
from department d;
部门名称 |员工数量|
----------|-------|
行政管理部| 3|
人力资源部| 3|
财务部 | 2|
研发部 | 9|
销售部 | 8|
保卫部 | 0|其中,子查询的 where 条件中使用了外查询的部门编号(d.dept_id),从而与外查询产生关联。该语句执行时,外查询先检索出所有的部门数据,针对每条记录再将 d.dept_id 传递给子查询;子查询返回每个部门的员工数量。
EXISTS 操作符
EXISTS 操作符用于判断子查询结果的存在性。如果子查询存在任何结果,EXISTS 返回 True;否则,返回 False。
例如,以下语句返回了存在女性员工的部门:
select d.dept_name
from department d
where exists ( select 1
from employee e
where e.sex = '女'
and e.dept_id = d.dept_id
);
dept_name|
---------|
财务部 |
研发部 |其中,exists 之后是一个关联子查询,先执行外查询找到 d.dept_id;然后依次将 d.dept_id 传递给子查询,判断该部门是否存在女性员工,如果存在则返回部门信息。
EXISTS 只判断结果的存在性,因此子查询的 SELECT 列表中的内容无所谓,通常使用一个常量值。EXISTS 只要找到任何数据,立即终止子查询的执行,因此可以提高查询的性能。
NOT EXISTS 执行相反的操作。如果想要查找不存在女性员工的部门,可以将上例中的 EXISTS 替换成 NOT EXISTS。
[NOT] EXISTS 和 [NOT] IN 都可以用于判断子查询返回的结果,但是它们之间存在一个重要的区别:[NOT] EXISTS 只检查存在性,[NOT] IN 需要比较实际的值是否相等。因此,当子查询的结果包含 NULL 值时,EXISTS 仍然返回结果,NOT EXISTS 不返回结果;但是此时 IN 和 NOT IN 都不会返回结果,因为 (X = NULL) 和 NOT (X = NULL) 的结果都是未知。
以下示例演示了这两者之间的区别:
select d.dept_name
from department d
where not exists ( select null
from employee e
where e.dept_id = d.dept_id
);
dept_name|
---------|
保卫部 |
select d.dept_name
from department d
where d.dept_id not in ( select null
from employee e
);
dept_name|
---------|第一个查询使用了 NOT EXISTS,子查询中除了“保卫部”之外的部门都有返回结果(NULL 也是结果),所以外查询只返回“保卫部”。第二个查询使用了 NOT IN,子查询中返回的都是 NULL 值;d.dept_id = NULL 的结果是未知,加上 NOT 之后仍然未知,所以查询没有返回任何结果。
EXISTS 和 IN 操作符返回左表(外查询)中与右表(子查询)至少匹配一次的数据行,实际上是一种半连接(Semi-join);NOT EXISTS 或者 NOT IN 操作符返回左表(外查询)中与右表(子查询)不匹配的数据行,实际上是一种反连接(Anti-join)。
横向派生表
对于派生表而言,它必须能够单独运行,而不能依赖其他表。例如,以下语句想要返回每个部门内月薪最高的员工:
select d.dept_name, t.emp_name, t.salary
from department d
left join (select e.dept_id, e.emp_name, e.salary
from employee e
where e.dept_id = d.dept_id
order by e.salary desc
limit 1
) t on d.dept_id = t.dept_id;
RROR 1054 (42S22): Unknown column 'd.dept_id' in 'where clause'该语句失败的原因在于子查询 t 不能引用外查询中的 department 表。
从 MySQL 8.0.14 开始,派生表支持 LATERAL 关键字前缀,表示允许派生表引用它所在的 FROM 子句中的其他表。这种派生表被称为横向派生表(Lateral Derived Table)。
对于上面的问题,可以使用 LATERAL 派生表实现:
select d.dept_name, t.emp_name, t.salary
from department d
left join lateral (select e.dept_id, e.emp_name, e.salary
from employee e
where e.dept_id = d.dept_id
order by e.salary desc
limit 1
) t on d.dept_id = t.dept_id;
dept_name |emp_name|salary |
------------|--------|--------|
行政管理部 |刘备 |30000.00|
人力资源部 |诸葛亮 |25000.00|
财务部 |孙尚香 |12000.00|
研发部 |赵云 |15000.00|
销售部 |法正 |10000.00|
保卫部 | | |该语句在 left join 之后加上了一个 lateral 关键字,使得子查询 t 能够引用前面的 department 表中的字段。
如果你使用的是 MySQL 5.7 以及之前的版本,可以利用 MySQL 中的自定义变量实现相同的效果:
select d.dept_name, w.emp_name, w.salary
from department d
left join (
select *
from (
select a.*, if(@did = a.dept_id, @rn := @rn+1, @rn := 1) as rn, @did := a.dept_id as did
from (select * from employee e order by dept_id, salary desc) a
cross join (select @rn := 0 rn, @did := 0) b
) as t
where t.rn <= 1
) as w on d.dept_id = w.dept_id;通用表表达式
通用表表达式(Common Table Expression)是一个在语句级别定义的临时结果集,定义之后可以在该语句中多次进行引用。MySQL 8.0 开始支持 CTE,包括简单形式的 CTE 和递归形式的 CTE。
select version() from dual 可查看mysql的版本
简单CTE
CTE 也称为 WITH 子句,它的基本语法如下:
WITH cte_name (col1, col2, ...) AS (
subquery
)
SELECT * FROM cte_name;其中,WITH 关键字表明这是一个通用表表达式;cte_name 是它的名字,括号内是可选的字段名;AS 之后是它的定义语句;最后在主查询语句中通过名字引用了前面定义的 CTE。
以下语句用于查找部门信息和对应的员工数量:
select d.dept_name as "部门名称",
coalesce(de.emp_number,0) as "员工数量"
from department d
left join (select dept_id,
count(*) as emp_number
from employee
group by dept_id) de
on (d.dept_id = de.dept_id);我们可以使用 CTE 将其改写如下:
with de(dept_id, emp_number) AS (
select dept_id,
count(*) as emp_number
from employee
group by dept_id)
select d.dept_name as "部门名称",
coalesce(de.emp_number,0) as "员工数量"
from department d
left join de on (d.dept_id = de.dept_id);其中,WITH 子句定义了一个临时结果集,名称为 de;AS 关键字指定了 de 的结构和数据,包含了每个部门的编号和员工数量;最后在连接查询的 JOIN 中使用了临时表 de。该语句的结果与上面的示例相同,但是在逻辑上更加清晰。
WITH 子句相当于定义了一个变量表达式,表达式的值是一个表,因此称为通用表表达式。CTE 和子查询类似,可以用于 SELECT、INSERT、UPDATE、DELETE 以及 CREATE VIEW 等语句。
一个语句中可以定义多个 CTE,一个 CTE 被定义之后可以多次引用,而且可以被后面定义的其他 CTE 引用。例如:
with t1(n) as (
select 2
),
t2(m) as (
select n + 1
from t1
)
select t1.n, t2.m, t1.n * t2.m
from t1, t2;
n|m|t1.n * t2.m|
-|-|-----------|
2|3| 6|以上示例中定义了 2 个 CTE;第一个 CTE 名称为 t1,包含了一条记录;第二个 CTE 名称为 t2,引用 t1 生成了一条记录;每个 CTE 之间使用逗号进行分隔;最后的 SELECT 语句使用前面定义的 2 个 CTE 进行连接查询。
在编程语言中,通常会定义一些变量和函数(方法);变量可以被重复使用,函数可以将代码模块化并且提高程序的可读性与可维护性。与此类似,MySQL 中的通用表表达式能够简化复杂的连接查询和子查询,同时实现查询结果的重复利用,从而提高复杂查询语句的可读性和性能。
递归CTE
简单 CTE 可以将 SQL 语句进行模块化,便于阅读和理解;而递归形式的 CTE 可以对自己进行引用,从而非常方便地遍历具有层次结构或者树状结构的数据,例如组织结构和航班中转信息查询。
例如,以下语句使用递归 CTE 生成了一个 1 到 10 的数字序列:
with recursive t(n) as
(
select 1
union all
select n + 1 from t where n < 10
)
select n from t;
n |
--|
1|
2|
3|
4|
5|
6|
7|
8|
9|
10|其中,RECURSIVE 关键字表示递归;递归 CTE 包含两部分,UNION ALL 中的第一个查询语句用于生成初始化数据,第二个查询语句引用了 CTE 自身。该语句的执行过程如下:
- 运行初始化语句,生成数字 1;
- 第 1 次运行递归部分,此时 n 等于 1,满足查询条件 n < 10,返回数字 2( n+1 );
- 第 2 次运行递归部分,此时 n 等于 2,满足查询条件 n < 10,返回数字 3( n+1 );
- 第 9 次运行递归部分,此时 n 等于 9,满足查询条件 n < 10,返回数字 10( n+1 );
- 第 10 次运行递归部分,此时 n 等于 10;由于不满足查询条件 n < 10,不返回任何结果并且结束递归;
- 最后的查询语句返回 t 中的全部数据,也就是一个 1 到 10 的数字序列。
员工表中存储了员工的各种信息,包括员工编号、姓名以及员工经理的编号。公司的老板“刘备”没有上级,对应的经理为空。该公司的组织结构图如下:
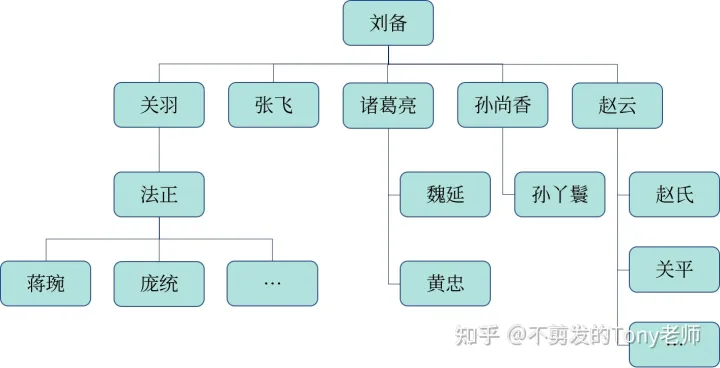
以下语句利用递归 CTE 生成了一个组织结构图,显示每个员工的从上到下的管理路径:
with recursive employee_path (emp_id, emp_name, path) as
(
select emp_id, emp_name, cast(emp_name as char(1000)) as path
from employee
where manager is null
union all
select e.emp_id, e.emp_name, cast(concat(ep.path, '->', e.emp_name) as char(1000))
from employee_path ep
join employee e on ep.emp_id = e.manager
)
select *
from employee_path
order by emp_id;其中,employee_path 是一个递归 CTE;其中的初始化部分用于查找上级经理为空的员工,也就是公司的老板:
select emp_id, emp_name, cast(emp_name as char(1000)) as path
from employee
where manager is null;
emp_id|emp_name|path|
------|--------|----|
1|刘备 |刘备 |“刘备”是公司的老板。然后第一次执行递归部分,将初始化的结果(employee_path)与员工表进行连接查询,找出“刘备”的所有直接下属员工。返回的结果如下:
emp_id|emp_name |path |
------|---------|-----------|
1|刘备 |刘备 |
2|关羽 |刘备->关羽 |
3|张飞 |刘备->张飞 |
4|诸葛亮 |刘备->诸葛亮|
7|孙尚香 |刘备->孙尚香|
9|赵云 |刘备->赵云 |其中 CONCAT 连接函数用于将之前的管理路径加上当前员工的姓名,生成新的管理路径。不断执行该过程继续返回其他的员工,直到不再返回新的员工为止,最终的返回结果如下:
emp_id|emp_name |path |
------|---------|-------------------|
1|刘备 |刘备 |
2|关羽 |刘备->关羽 |
3|张飞 |刘备->张飞 |
4|诸葛亮 |刘备->诸葛亮 |
5|黄忠 |刘备->诸葛亮->黄忠 |
6|魏延 |刘备->诸葛亮->魏延 |
...
25|孙乾 |刘备->关羽->法正->孙乾|递归限制
通常来说,递归 CTE 的定义中需要包含一个终止递归的条件;否则的话,递归将会进入死循环。递归终止的条件可以是遍历完表中的所有数据,不再返回结果;或者是一个 WHERE 终止条件。
以下语句删除了上文生成数字序列的示例中的 WHERE 终止条件:
with recursive t(n) as
(
select 1
union all
select n + 1 from t -- where n < 10
)
select n from t;
ERROR 3636 (HY000): Recursive query aborted after 1001 iterations. Try increasing @@cte_max_recursion_depth to a larger value.默认情况下,MySQL 递归 1000 次后返回错误。这一次数限制由系统变量 cte_max_recursion_depth 进行控制;如果 CTE 递归的次数超过了该变量的值,服务器将会强制终止语句的执行。
cte_max_recursion_depth 可以在会话级别或者全局级别进行设置。例如:
set session cte_max_recursion_depth = 1000000;
set global cte_max_recursion_depth = 1000000;另外,也可以在 CTE 语句中使用优化器提示:
with recursive t(n) as
(
select 1
union all
select n + 1 from t where n < 10000
)
select /*+ SET_VAR(cte_max_recursion_depth = 1M) */ n from t;除了递归次数的限制之外,递归 CTE 的递归部分(UNION 之后的 SELECT 语句)不允许出现以下内容:
- 聚合函数,例如 SUM 等;
- 窗口函数;
- GROUP BY;
- ORDER BY;
- DISTINCT。
另外,递归部分只能引用 CTE 名称一次,而且只能在 FROM 子句中(不能在子查询中)引用;如果在递归部分使用其他表和 CTE 进行连接查询, CTE 不能出现在 LEFT JOIN 的右侧。
集合操作符
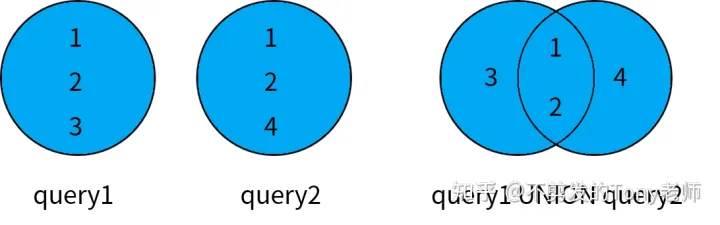
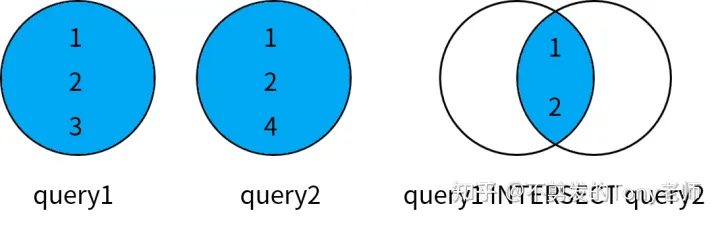
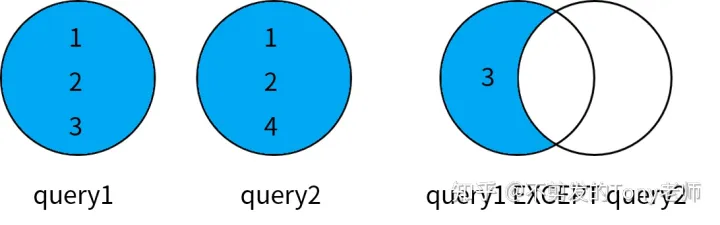
数据表与集合理论中的集合非常类似,表是由行组成的集合。SQL 标准定义了基于行的各种集合操作:并集运算(UNION)、交集运算(INTERSECT)和差集运算(EXCEPT)。
- UNION,用于将两个查询结果合并成一个结果集,返回第一个查询或者第二个查询中的数据;
- INTERSECT,用于返回两个查询结果中的共同部分,即同时属于第一个查询结果和第二个查询结果的数据;
- EXCEPT,用于返回出现在第一个查询结果中,但不在第二个查询结果中的数据。
这些操作符都可以将两个查询的结果集合并成一个结果集,但是合并的规则各不相同,如下图所示:
对于集合操作符,参与运算的两个查询结果需要满足以下条件:
- 结果集中字段的数量和顺序必须相同;
- 结果集中对应字段的类型必须匹配或兼容。
也就是说,两个查询结果的字段结构必须相同。如果一个查询返回 2 个字段,另一个查询返回 3 个字段,肯定无法合并。如果一个查询返回数字类型的字段,另一个查询返回字符类型的字段,通常也无法合并;不过 MySQL 可能会执行隐式的类型转换。
并集(UNION)
UNION 操作符用于将两个查询结果合并成一个结果集,返回第一个查询或者第二个查询中的数据:
SELECT column1, column2, ...
FROM table1
UNION [DISTINCT | ALL]
SELECT col1, col2, ...
FROM table2;其中,DISTINCT 表示将合并后的结果集进行去重;ALL 表示保留结果集中的重复记录;如果省略,默认为 DISTINCT。例如:
CREATE TABLE t1(id int);
INSERT INTO t1 VALUES (1), (2);
CREATE TABLE t2(id int);
INSERT INTO t2 VALUES (1), (3);
SELECT id AS n FROM t1
UNION
SELECT id AS m FROM t2;
n|
-|
1|
2|
3|
SELECT id AS n FROM t1
UNION ALL
SELECT id AS m FROM t2;
n|
-|
1|
2|
1|
3|第一个查询结果中只返回了一个数字 1;第二个查询结果中保留了重复的数字 1。另外,UNION 操作返回的字段名由第一个 SELECT 语句决定。
以下语句由于两个 SELECT 返回的字段数量不同而产生错误:
SELECT 1 AS n, 'a' AS s
UNION ALL
SELECT 1 AS m;
ERROR 1222 (21000): The used SELECT statements have a different number of columns以下语句通过隐式类型转换返回了合并之后的结果:
SELECT 1 AS n, 'a' AS s
UNION ALL
SELECT 1, 2;
n|s|
-|-|
1|a|
1|2|返回结果中的第二个字段类型为字符串。
对于多个表的 UNION 操作,按照从前到后的自然顺序执行。例如:
SELECT 1 AS n
UNION ALL
SELECT 1
UNION
SELECT 1;
n|
-|
1|由于第二个 UNION 操作没有 ALL 选项,最终返回了去重之后的结果,也就是一个 1。
ORDER BY 和 LIMIT
如果要对整个 UNION 操作的结果进行排序和数量限定,可以将 ORDER BY 和 LIMIT 子句加到语句的最后。例如:
SELECT id AS n FROM t1
UNION ALL
SELECT id AS m FROM t2
ORDER BY n;
n|
-|
1|
1|
2|
3|如果要对参与 UNION 的 SELECT 语句进行排序和数量限定,需要使用括号包含。例如:
(SELECT id AS n FROM t1 ORDER BY id DESC LIMIT 1)
UNION ALL
(SELECT id AS m FROM t2 ORDER BY id LIMIT 1);
n|
-|
2|
1|这种排序操作不会影响到最终的结果顺序,如果要对最终结果进行排序,还需要在查询语句的最后再加上一个 ORDER BY 子句。
交集(INTERSECT)
MySQL 没有实现 SQL 标准中的 INTERSECT 操作符。按照定义,它可以返回两个查询结果中的共同部分,即同时出现在第一个查询结果和第二个查询结果中的数据,我们可以通过 JOIN 查询实现相同的结果:
SELECT DISTINCT table1.column1, table1.column2, ...
FROM table1
JOIN table2
ON (table1.column1 = table2.col1 AND table1.column2 = table2.col2 ...);其中,DISTINCT 用于去除查询结果中的重复记录,实现和 INTERSECT 相同的效果。例如:
SELECT DISTINCT t1.id
FROM t1
JOIN t2 ON (t1.id = t2.id);
id|
--|
1|以上查询返回了 t1 和 t2 的交集。
还有一种方法也可以实现相同的结果,就是使用 IN 或者 EXISTS 子查询语句。例如:
SELECT DISTINCT id
FROM t1
WHERE id IN (SELECT id FROM t2);
id|
--|
1|差集(EXCEPT)
MySQL 没有实现 SQL 标准中的 EXCEPT 操作符。按照定义,它可以返回出现在第一个查询结果中,但不在第二个查询结果中的数据。我们同样可以通过 JOIN 查询实现相同的结果:
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2
ON (table1.column1 = table2.col1 AND table1.column2 = table2.col2 ...)
WHERE table2.col1 IS NULL;左外连接返回了 table1 中的所有数据,WHERE 条件排除了其中属于 table2 的数据,从而实现了 EXCEPT 操作符的效果。例如:
SELECT t1.id
FROM t1
LEFT JOIN t2 ON (t2.id = t1.id)
WHERE t2.id IS NULL;
id|
--|
2|还有一种方法也可以实现相同的结果,就是使用 NOT IN 或者 NOT EXISTS 子查询语句。例如:
SELECT DISTINCT id
FROM t1
WHERE id NOT IN (SELECT id FROM t2);
id|
--|
2|
|
参考: |
