Linux服务器性能查看分析调优
服务器性能查看
CPU性能查看
查看物理CPU个数:
cat /proc/cpuinfo |grep "physical id"|sort|uniq|wc -l查看每个物理CPU中的core个数:
cat /proc/cpuinfo |grep "cpu cores"|wc -l逻辑CPU的个数:
cat /proc/cpuinfo |grep "processor"|wc -l物理cpu个数*核数=逻辑cpu个数(不支持超线程技术的情况下)
内存查看
查看内存使用情况:
#free -m
total used free shared buffers cached
Mem: 3949 2519 1430 0 189 1619
-/+ buffers/cache: 710 3239
Swap: 3576 0 3576-m 参数就是用 M显示内容使用情况。
total:内存总数
used:已经使用的内存数
free:空闲内存数
shared:多个进程共享的内存总额
- buffers/cache:(已用)的内存数,即used-buffers-cached
+ buffers/cache:(可用)的内存数,即free+buffers+cached Buffer
Cache用于针对磁盘块的读写;
Page Cache用于针对文件inode的读写,这些Cache能有效地缩短I/O系统调用的时间。
对操作系统来说free/used是系统可用/占用的内存;
对应用程序来说-/+ buffers/cache是可用/占用内存,因为buffers/cache很快就会被使用。
硬盘查看
查看硬盘及分区信息
fdisk -l查看文件系统的磁盘空间占用情况
df -h查看硬盘的I/O性能(每隔一秒显示一次,显示5次)
iostat -x 1 5iostat是含在套装systat中的,可以用yum -y install systat(yum install systat)来安装。
常关注的参数:
如%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
如idle小于70%,I/O的压力就比较大了,说明读取进程中有较多的wait。
查看linux系统中某目录的大小:
du -sh /root如发现某个分区空间接近用完,可以进入该分区的挂载点,用以下命令找出占用空间最多的文件或目录,然后按照从大到小的顺序,找出系统中占用最多空间的前10个文件或目录:
du -cksh *|sort -rn|head -n 10查看平均负载
有时候系统响应很慢,但又找不到原因,这时就要查看平均负载了,看它是否有大量的进程在排队等待。
uptime命令
以下显示输入uptime的信息:
[root@localhost ~]# uptime
04:03:58 up 10 days, 13:19, 1 user, load average: 0.54, 0.40, 0.20- 当前时间 04:03:58
- 系统已运行的时间 10 days, 13:19
- 当前在线用户 1 user
- 平均负载:0.54, 0.40, 0.20,最近1分钟、5分钟、15分钟系统的负载
查看系统平均负载:
[root@localhost ~]# cat /proc/loadavg
0.00 0.01 0.05 1/135 2280除了前3个数字表示平均进程数量外,后面的1个分数,分母表示系统进程总数,分子表示正在运行的进程数;最后一个数字表示最近运行的进程ID。
系统平均负载被定义为在特定时间间隔内运行队列中的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果
- 它没有主动进入等待状态(也就是没有调用'wait')
- 没有被停止(例如:等待终止)
一般来说,每个CPU内核当前活动进程数不大于3,则系统运行表现良好!当然这里说的是每个cpu内核,也就是如果你的主机是四核cpu的话,那么只要uptime最后输出的一串字符数值小于12即表示系统负载不是很严重,当然如果达到20,那就表示当前系统负载非常严重,估计打开执行web脚本非常缓慢。
top命令
top命令经常用来监控linux的系统状况,是常用的性能分析工具,能够实时显示系统中各个进程的资源占用情况。
使用方式:
top [-d number]
top [-bnp]参数解释:
- -d :number代表秒数,表示top命令显示的页面更新一次的间隔。默认是5秒。
- -b:以批次的方式执行top。
- -n:与-b配合使用,表示需要进行几次top命令的输出结果。
- -p:指定特定的pid进程号进行观察。
top各输出参数含义:(以下是centos的图示)
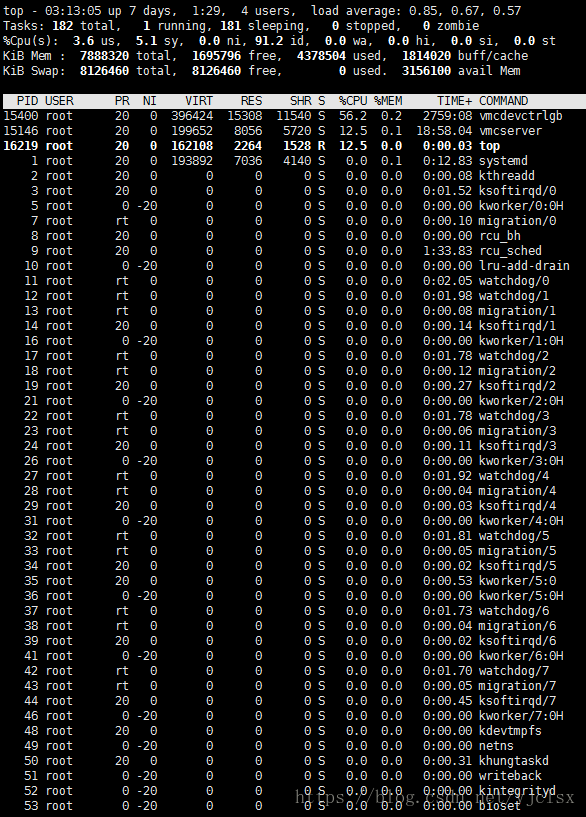
1、top前5行统计信息
第1行:top - 05:43:27 up 4:52, 2 users, load average: 0.58, 0.41, 0.30
第1行是任务队列信息,其参数如下:
| 内容 | 含义 |
|---|---|
| 05:43:27 | 表示当前时间 |
| up 4:52 | 系统运行时间 格式为时:分 |
| 2 users | 当前登录用户数 |
| load average: 0.58, 0.41, 0.30 | 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。 |
load average:如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第2行:Tasks: 159 total, 1 running, 158 sleeping, 0 stopped, 0 zombie
第3行:%Cpu(s): 37.0 us, 3.7 sy, 0.0 ni, 59.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
第2、3行为进程和CPU的信息 ,当有多个CPU时,这些内容可能会超过两行,其参数如下:
| 内容 | 含义 |
| 159 total | 进程总数 |
| 1 running | 正在运行的进程数 |
| 158 sleeping | 睡眠的进程数 |
| 0 stopped | 停止的进程数 |
| 0 zombie | 僵尸进程数 |
| 37.0 us | 用户空间占用CPU百分比 |
| 3.7 sy | 内核空间占用CPU百分比 |
| 0.0 ni | 用户进程空间内改变过优先级的进程占用CPU百分比 |
| 59.3 id | 空闲CPU百分比 |
| 0.0 wa | 等待输入输出的CPU时间百分比 |
| 0.0 hi | 硬中断(Hardware IRQ)占用CPU的百分比 |
| 0.0 si | 软中断(Software Interrupts)占用CPU的百分比 |
| 0.0 st | 虚拟机占用物理机的百分比 |
第4行:KiB Mem: 1530752 total, 1481968 used, 48784 free, 70988 buffers
第5行:KiB Swap: 3905532 total, 267544 used, 3637988 free. 617312 cached Mem
第4、5行为内存信息 ,其参数如下:
| 内容 | 含义 |
| KiB Mem: 1530752 total | 物理内存总量 |
| 1481968 used | 使用的物理内存总量 |
| 48784 free | 空闲内存总量 |
| 70988 buffers(buff/cache) | 用作内核缓存的内存量 |
| KiB Swap: 3905532 total | 交换区总量 |
| 267544 used | 使用的交换区总量 |
| 3637988 free | 空闲交换区总量 |
| 617312 cached Mem | 缓冲的交换区总量。 |
| 3156100 avail Mem | 代表可用于进程下一次分配的物理内存数量 |
上述最后提到的缓冲的交换区总量,这里解释一下,所谓缓冲的交换区总量,即内存中的内容被换出到交换区,而后又被换入到内存,但使用过的交换区尚未被覆盖,该数值即为这些内容已存在于内存中的交换区的大小。相应的内存再次被换出时可不必再对交换区写入。
内存空间还剩多少空闲呢?
totalfree = free 541676 + buffer 64316 + cached 224884 (即:空闲内存 = 空闲内存总量 + 内核缓存的内存量 + 缓冲的交换区总量)
2、进程信息
| 列名 | 含义 |
| PID | 进程id |
| PPID | 父进程id |
| RUSER | Real user name |
| UID | 进程所有者的用户id |
| USER | 进程所有者的用户名 |
| GROUP | 进程所有者的组名 |
| TTY | 启动进程的终端名。不是从终端启动的进程则显示为 ? |
| PR | 优先级 |
| NI | nice值。负值表示高优先级,正值表示低优先级 |
| P | 最后使用的CPU,仅在多CPU环境下有意义 |
| %CPU | 上次更新到现在的CPU时间占用百分比 |
| TIME | 程使用的CPU时间总计,单位秒 |
| TIME+ | 进程使用的CPU时间总计,单位1/100秒 |
| %MEM | 进程使用的物理内存百分比 |
| VIRT | 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES |
| SWAP | 进程使用的虚拟内存中,被换出的大小,单位kb |
| RES | 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA |
| CODE | 可执行代码占用的物理内存大小,单位kb |
| DATA | 可执行代码以外的部分(数据段+栈)占用的物理内存大小,单位kb |
| SHR | 共享内存大小,单位kb |
| nFLT | 页面错误次数 |
| nDRT | 最后一次写入到现在,被修改过的页面数。 |
| S | 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程 |
| COMMAND | 命令名/命令行 |
| WCHAN | 若该进程在睡眠,则显示睡眠中的系统函数名 |
| Flags | 任务标志 |
【备注:默认情况下仅显示比较重要的 PID、USER、PR、NI、VIRT、RES、SHR、S、%CPU、%MEM、TIME+、COMMAND 列。可以通过下面的快捷键来更改显示内容】
3、其他
默认进入top时,各进程是按照CPU的占用量来排序的。
(1)在top基本视图中,按键盘数字“1”可以监控每个逻辑CPU的状况
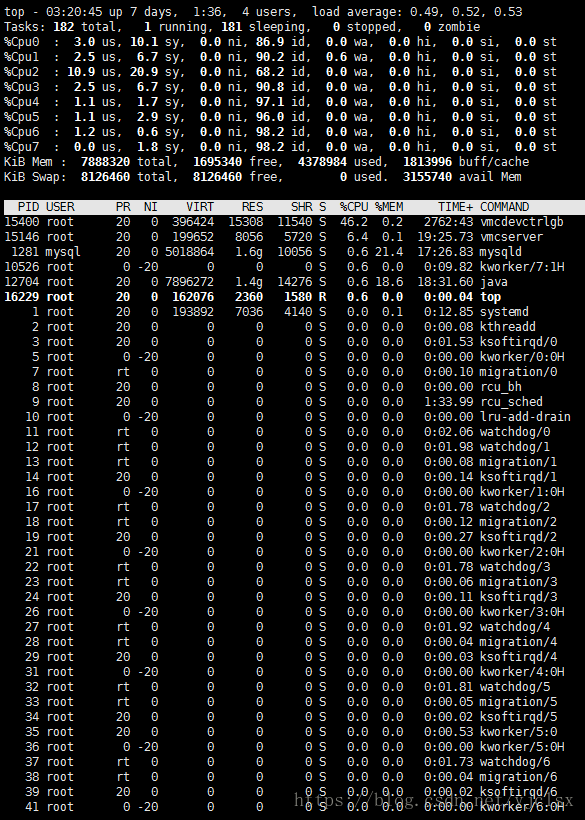
(2)敲击键盘‘b’(打开关闭加亮效果)top视图变换如下:
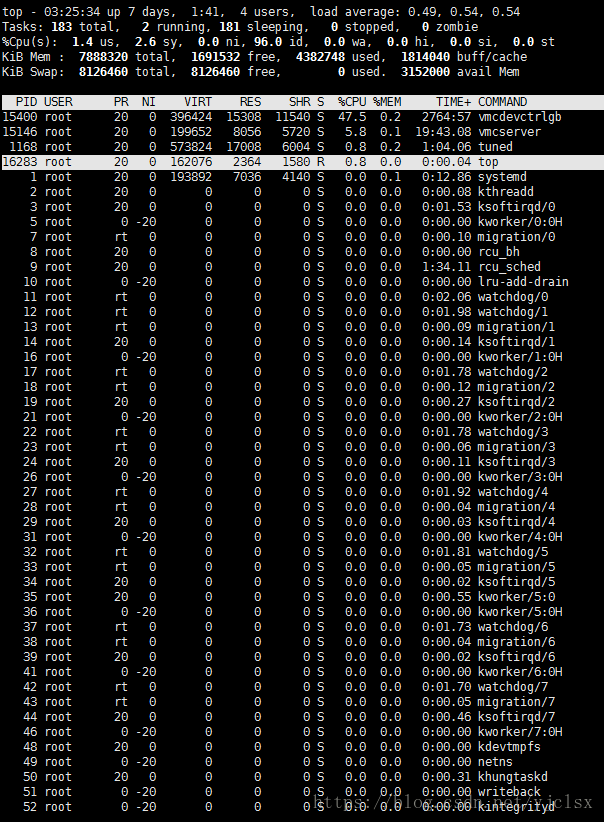
PID为16283为当前top视图中唯一的运行态进程。也可以敲击键盘‘y’来打开或者关闭运行态进程的加亮效果。
(3)敲击键盘‘x’(打开/关闭排序列的加亮效果),top视图变换如下:

可以看到现在是按"%CPU"进行排序的,可以按”shift+>”或者”shift+<”左右改变排序序列。
(4)改变进程显示字段
在top基本视图中,敲击“f”进入另一个视图,在这里可以编辑基本视图中的显示字段:
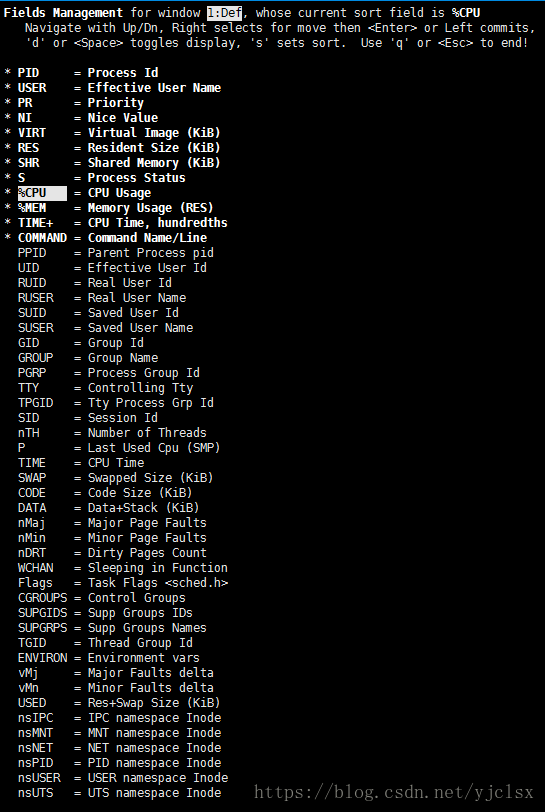
用上下键选择选项,按下空格键可以决定是否在基本视图中显示这个选项。
top命令是一个非常强大的功能,但是它监控的最小单位是进程,如果想监控更小单位时,就需要用到ps或者netstate命令来满足我们的要求。
vmstat命令
vmstat命令是最常见的Linux/Unix监控工具,属于sysstat包。可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况。这个命令是我查看Linux/Unix最喜爱的命令,一个是Linux/Unix都支持,二是相比top,我可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
安装:yum install -y sysstat
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数是采样的时间间隔数,单位是秒,第二个参数是采样的次数,如:
[root@localhost ~]# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1328732 2112 346816 0 0 6 2 15 24 0 0 100 0 02表示每个两秒采集一次服务器状态,1表示只采集一次。
实际上,在应用过程中,我们会在一段时间内一直监控,不想监控直接结束vmstat就行了,例如:
[root@localhost ~]# vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1328336 2112 346848 0 0 6 2 15 24 0 0 100 0 0
0 0 0 1328344 2112 346848 0 0 0 0 53 89 0 0 100 0 0
0 0 0 1328344 2112 346848 0 0 0 0 48 77 0 0 100 0 0
0 0 0 1328344 2112 346848 0 0 0 0 47 84 0 0 100 0 0
0 0 0 1328344 2112 346848 0 0 0 0 43 77 0 0 100 0 0
2 0 0 1328344 2112 346848 0 0 0 0 47 82 0 0 100 0 0这表示vmstat每2秒采集数据,一直采集,直到我结束程序。
1、字段含义说明
- procs(进程)
- r:等待执行的任务数。展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。
- b:表示阻塞的进程。
- memory(内存)
- swpd:正在使用虚拟的内存大小,单位k。虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free:空闲的物理内存大小。
- buff:已用的buff大小,对块设备的读写进行缓冲。Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存。
- cache:已用的cache大小,文件系统的cache。为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。
- inact:非活跃内存大小,即被标明可回收的内存,区别于free和active。
- active:活跃的内存大小。
- swap
- si:每秒从交换区写入内存的大小(单位:kb/s)。每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so:每秒从内存写到交换区的大小。每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- io
- bi:每秒读取的块数(读磁盘)。块设备每秒接收的块数量,单位是block,这里的块设备是指系统上所有的磁盘和其他块设备,现在的Linux版本块的大小为1024bytes。
- bo:每秒写入的块数(写磁盘)。块设备每秒发送的块数量,单位是block。
- system
- in:每秒中断数,包括时钟中断。这两个值越大,会看到由内核消耗的cpu时间sy会越多。
- cs:每秒上下文切换数。每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- cpu(以百分比表示)
- us:用户进程执行消耗cpu时间(user time)。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了。
- sy:系统进程消耗cpu时间(system time)。sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
- id:空闲时间(包括IO等待时间)。一般来说 us+sy+id=100。
- wa:等待IO时间。wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。
2、常见问题及解决方法
如果 r 经常大于4,且id经常少于40,表示cpu的负荷很重。
如果pi,po长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
如果 r 的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。
当发生以上问题的时候请先调整应用程序对CPU的占用情况,使得应用程序能够更有效的使用CPU,同时可以考虑增加更多的CPU。关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间。一般情况下,应用程序的问题会比较大一些,比如一些sql语句不合理等等都会造成这样的现象。
服务器性能评估
影响Linux服务器性能的因素
操作系统级
CPU
内存
磁盘I/O带宽
网络I/O带宽程序应用级
系统性能评估标准
| 影响性能因素 | 好 | 坏 | 糟糕 |
| CPU | user% + sys%< 70% | user% + sys%= 85% | user% + sys% >=90% |
| 内存 | Swap In(si)=0 Swap Out(so)=0 | Per CPU with 10 page/s | More Swap In & Swap Out |
| 磁盘 | iowait % < 20% | iowait % =35% | iowait % >= 50% |
其中:
%user:表示CPU处在用户模式下的时间百分比。
%sys:表示CPU处在系统模式下的时间百分比。
%iowait:表示CPU等待输入输出完成时间的百分比。
swap in:即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM
swap out:即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK系统性能分析工具
常用系统命令:vmstat、sar、iostat、netstat、free、ps、top等。
常用组合方式:
vmstat、sar、iostat检测是否是CPU瓶颈
free、vmstat检测是否是内存瓶颈
iostat检测是否是磁盘I/O瓶颈
netstat检测是否是网络带宽瓶颈Linux性能评估与优化
系统整体性能评估(uptime命令)
使用uptime对系统进行整体性能的评估。
16:38:00 up 118 days, 3:01, 5 users,load average: 1.22, 1.02, 0.91注意:
- load average三值大小一般不能大于系统CPU的个数,但偶尔大于8,一般不会影响系统性能。(系统有8个CPU,如load average三值长期大于8,说明CPU很繁忙,负载很高,可能会影响系统性能。)
- 如load average输出值小于CPU个数,则表示CPU有空闲时间片,比如本例中的输出,CPU是非常空闲的
CPU性能评估
1、利用vmstat命令监控系统CPU
显示系统各种资源之间相关性能简要信息,主要看CPU负载情况。
[root@localhost ~]# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1328336 2112 346848 0 0 6 2 15 24 0 0 100 0 0
0 0 0 1328344 2112 346848 0 0 0 0 53 89 0 0 100 0 0- r:运行和等待cpu时间片的进程数,这个值如果长期大于系统CPU的个数,说明CPU不足,需要增加CPU。
- b:在等待资源的进程数,比如正在等待I/O、或者内存交换等。
- us:用户进程消耗的CPU 时间百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
- sy:内核进程消耗的CPU时间百分比。sy的值较高时,说明内核消耗的CPU资源很多。根据经验,us+sy的参考值为80%,如果us+sy大于 80%说明可能存在CPU资源不足。
2、利用sar命令监控系统CPU
sar对系统每方面进行单独统计,但会增加系统开销,不过开销可以评估,对系统的统计结果不会有很大影响。
下面是sar命令对某个系统的CPU统计输出:
[root@localhost ~]# sar -u 3 5
Linux 3.10.0-1160.15.2.el7.x86_64 (localhost) 08/07/2021 _x86_64_ (4 CPU)
09:13:33 PM CPU %user %nice %system %iowait %steal %idle
09:13:36 PM all 0.00 0.00 0.08 0.00 0.00 99.92
09:13:39 PM all 0.00 0.00 0.08 0.00 0.00 99.92输出解释如下:
- %user列显示了用户进程消耗的CPU 时间百分比。
- %nice列显示了运行正常进程所消耗的CPU 时间百分比。
- %system列显示了系统进程消耗的CPU时间百分比。
- %iowait列显示了IO等待所占用的CPU时间百分比。
- %steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的steal操作 。
- %idle列显示了CPU处在空闲状态的时间百分比。
问题:你是否遇到过系统CPU整体利用率不高,而应用缓慢的现象?
在一个多CPU的系统中,如果程序使用了单线程,会出现这么一个现象,CPU的整体使用率不高,但是系统应用却响应缓慢,这可能是由于程序使用单线程的原因,单线程只使用一个CPU,导致这个CPU占用率为100%,无法处理其它请求,而其它的CPU却闲置,这就导致了整体CPU使用率不高,而应用缓慢现象的发生。
内存性能评估
1、利用free指令监控内存
free是监控Linux内存使用状况最常用的指令,看下面的一个输出:
#free -m
total used free shared buffers cached
Mem: 3949 2519 1430 0 189 1619
-/+ buffers/cache: 710 3239
Swap: 3576 0 3576经验公式:
应用程序可用内存/系统物理内存>70%,表示系统内存资源非常充足,不影响系统性能;
应用程序可用内存/系统物理内存<20%,表示系统内存资源紧缺,需要增加系统内存;
20%<应用程序可用内存/系统物理内存<70%,表示系统内存资源基本能满足应用需求,暂时不影响系统性能
2、利用vmstat命令监控内存
[root@localhost ~]# vmstat 2 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1328732 2112 346816 0 0 6 2 15 24 0 0 100 0 0memory
swpd:切换到内存交换区的内存数量(k为单位)。如swpd值偶尔非0,不影响系统性能
free:当前空闲的物理内存数量(k为单位)
buff:buffers cache的内存数量,一般对块设备的读写才需要缓冲
cache:page cached的内存数量
一般作为文件系统cached,频繁访问的文件都会被cached,如cache值较大,说明cached的文件数较多,如果此时IO中bi比较小,说明文件系统效率比较好。
swap
si:由磁盘调入内存,也就是内存进入内存交换区的数量。
so:由内存调入磁盘,也就是内存交换区进入内存的数量。
si、so的值长期不为0,表示系统内存不足。需增加系统内存。
磁盘I/O性能评估
频繁访问的文件或数据尽可能用内存读写代替直接磁盘I/O,效率高千倍。
将经常进行读写的文件与长期不变的文件独立出来,分别放置到不同的磁盘设备上。
对于写操作频繁的数据,可以考虑使用裸设备代替文件系统。
裸设备优点:
- 数据可直接读写,不需经过操作系统级缓存,节省内存资源,避免内存资源争用;
- 避免文件系统级维护开销,如文件系统需维护超级块、I-node等;
- 避免了操作系统cache预读功能,减少了I/O请求
裸设备的缺点:
- 数据管理、空间管理不灵活,需要很专业的人来操作。
1、利用iostat评估磁盘性能
[root@localhost ~]# iostat -x 1 1
Linux 3.10.0-1160.15.2.el7.x86_64 (localhost) 08/07/2021 _x86_64_ (4 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.02 0.00 0.06 0.00 0.00 99.91
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
fd0 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 50.00 50.00 0.00 50.00 0.00
sda 0.00 0.02 0.38 0.16 13.66 4.97 68.78 0.00 2.85 1.04 7.04 1.26 0.07
scd0 0.00 0.00 0.00 0.00 0.05 0.00 114.22 0.00 26.06 26.06 0.00 24.94 0.00
dm-0 0.00 0.00 0.32 0.18 12.04 4.87 68.05 0.00 3.21 1.20 6.79 1.35 0.07
dm-1 0.00 0.00 0.00 0.00 0.11 0.00 49.62 0.00 0.45 0.45 0.00 0.36 0.00rrqm/s: 每秒合并读操作的次数
wrqm/s: 每秒合并写操作的次数
r/s: 每秒读操作的次数 (IOPS)
w/s: 每秒写操作的次数 (IOPS)
rMB/s: 每秒读带宽
wMB/s: 每秒写带宽
avgrq-sz: I/O请求的平均大小(扇区数)
avgqu-sz: I/O请求队列的平均长度
await: 每个I/O平均耗时,单位是ms,这个时间包括I/O在队列中等待耗时,以及最终被磁盘设备处理的时间
r_await: 每个读操作的平均耗时
w_await: 每个写操作的平均耗时
svctm: 这个指标其实已经废弃了,没意义,不管这个指标
%util: 该磁盘设备的繁忙度,该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。
(1)%util与硬盘设备饱和度
%util表示该设备有I/O(即非空闲)的时间比率,不考虑I/O有多少,只考虑有没有。由于现代硬盘设备都有并行处理多个I/O请求的能力,所以%util即使达到100%也不意味着设备饱和了。
举个简化的例子:某硬盘处理单个I/O需要0.1秒,有能力同时处理10个I/O请求,那么当10个I/O请求依次顺序提交的时候,需要1秒才能全部完成,在1秒的采样周期里%util达到100%;
而如果10个I/O请求一次性提交的话,0.1秒就全部完成,在1秒的采样周期里%util只有10%。可见,即使%util高达100%,硬盘也仍然有可能还有余力处理更多的I/O请求,即没有达到饱和状态。
(2)await多大才算有问题
await是单个I/O所消耗的时间,包括硬盘设备处理I/O的时间和I/O请求在kernel队列中等待的时间,正常情况下队列等待时间可以忽略不计,姑且把await当作衡量硬盘速度的指标吧,那么多大算是正常呢?
对于SSD,从0.0x毫秒到1.x毫秒不等,具体看产品手册;
对于机械硬盘,一般来说一万转的机械硬盘是8.38毫秒,包括寻道时间、旋转延迟、传输时间。
在实践中,要根据应用场景来判断await是否正常,如果I/O模式很随机、I/O负载比较高,会导致磁头乱跑,寻道时间长,那么相应地await要估算得大一些;
如果I/O模式是顺序读写,只有单一进程产生I/O负载,那么寻道时间和旋转延迟都可以忽略不计,主要考虑传输时间,相应地await就应该很小,甚至不到1毫秒。
对磁盘阵列来说,因为有硬件缓存,写操作不等落盘就算完成,所以写操作的service time大大加快了,如果磁盘阵列的写操作不在一两个毫秒以内就算慢的了;
读操作则未必,不在缓存中的数据仍然需要读取物理硬盘,单个小数据块的读取速度跟单盘差不多。
2、利用sar评估磁盘性能
通过“sar –d”组合,可以对系统的磁盘IO做一个基本的统计,请看下面的一个输出:
[root@localhost ~]# sar -d
Linux 3.10.0-1160.15.2.el7.x86_64 (localhost) 08/07/2021 _x86_64_ (4 CPU)
02:50:01 PM DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
03:00:01 PM dev2-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:00:01 PM dev8-0 0.08 0.00 0.77 10.00 0.00 10.87 8.61 0.07
03:00:01 PM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:00:01 PM dev253-0 0.08 0.00 0.77 9.79 0.00 10.79 8.45 0.07
03:00:01 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:10:01 PM dev2-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:10:01 PM dev8-0 0.12 0.31 1.16 12.25 0.00 7.86 5.71 0.07
03:10:01 PM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
03:10:01 PM dev253-0 0.12 0.31 1.16 11.76 0.00 7.68 5.49 0.07
03:10:01 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:40:01 PM dev2-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:40:01 PM dev8-0 0.08 0.00 0.73 8.72 0.00 21.73 19.42 0.16
05:40:01 PM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:40:01 PM dev253-0 0.09 0.00 0.73 8.30 0.00 21.03 18.49 0.16
05:40:01 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:50:01 PM dev2-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:50:01 PM dev8-0 0.07 0.00 0.51 7.41 0.00 6.83 5.44 0.04
05:50:01 PM dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
05:50:01 PM dev253-0 0.07 0.00 0.51 7.24 0.00 6.81 5.31 0.04
05:50:01 PM dev253-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00输出参数含义:
await--平均每次设备I/O操作等待时间(毫秒)
svctm--平均每次设备I/O操作的服务时间(毫秒)
%util--一秒中有百分之几的时间用于I/O操作
对磁盘IO性能评判标准:正常svctm应小于await值,而svctm和磁盘性能有关,CPU、内存负荷也会对svctm值造成影响,过多的请求也会间接的导致svctm值的增加。
await值取决svctm和I/O队列长度以及I/O请求模式, 如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好, 如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢, 此时可以通过更换更快的硬盘来解决问题。
%util:衡量磁盘I/O重要指标,如%util接近100%,表示磁盘产生的I/O请求太多,I/O系统已经满负荷工作,该磁盘可能存在瓶颈。可优化程序或者 通过更换 更高、更快的磁盘。
网络性能评估
- 通过ping命令检测网络的连通性
- 通过netstat –i组合检测网络接口状况
- 通过netstat –r组合检测系统的路由表信息
- 通过sar –n组合显示系统的网络运行状态
1、ping
ping 发送 ICMP echo 数据包来探测网络的连通性,除了能直观地看出网络的连通状况外,还能获得本次连接的往返时间(RTT 时间),丢包情况,以及访问的域名所对应的 IP 地址(使用 DNS 域名解析),比如:

我们 ping baidu.com,-c参数指定发包数。可以看到,解析到了 baidu 的一台服务器 IP 地址为 39.156.69.79。RTT (本次连接的往返时间)时间的最小、平均、最大和算术平均差分别是37.001ms、38.029ms、39.089ms 和 0.764。
2、ifconfig
ifconfig 命令被用于配置和显示 Linux 内核中网络接口的统计信息。通过这些统计信息,我们也能够进行一定的网络性能调优。
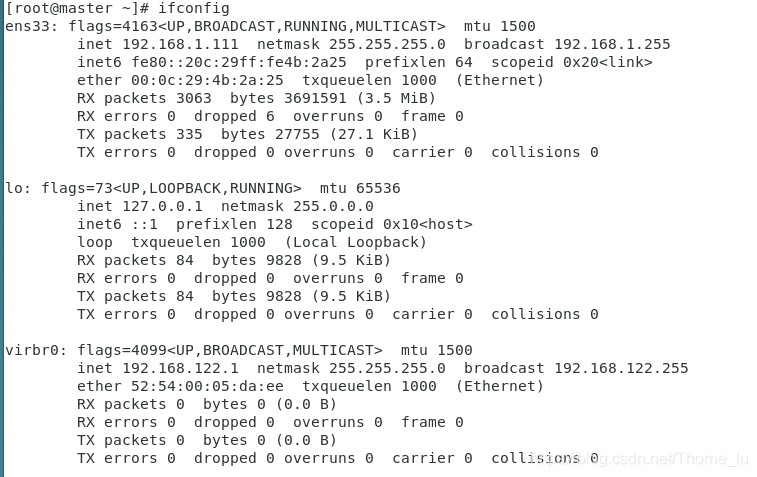
其中,RX/TX packets 是对接收/发送数据包的情况统计,包括错误的包,丢掉多少包等。RX/TX bytes 是接收/发送数据字节数统计。其余还有很多参数,就不一一述说了,性能调优时可以重点关注 MTU(最大传输单元) 和txqueuelen(发送队列长度),比如可以用下面的命令来对这两个参数进行微调:

3、netstat
netstat 可以查看整个 Linux 系统关于网络的情况,是一个集多种网络工具于一身的组合工具。
常用选项包括以下几个:
- 默认:列出连接的套接字
- -a:列出所有套接字的信息
- -s:各种网络协议栈统计信息
- -i:网络接口信息
- -r:列出路由表
- -l:仅列出有在 Listen 的服务状态
- -p:显示 PID 和进程名称
各参数组合使用实例如下:
- netstat -at 列出所有 TCP 端口
- netstat -au 列出所有 UDP 端口
- netstat -lt 列出所有监听 TCP 端口的 socket
- netstat -lu 列出所有监听 UDP 端口的 socket
- netstat -lx 列出所有监听 UNIX 端口的 socket
- netstat -ap | grep ssh 找出程序运行的端口
- netstat -an | grep ‘:80’ 找出运行在指定端口的进程
(1)netstat 默认显示连接的套接字数据

整体上来看,输出结果包括两个部分:
- Active Internet connections :有源 TCP 连接,其中 Recv-Q 和 SendQ 指的是接收队列和发送队列,这些数字一般都是 0,如果不是,说明请求包和回包正在队列中堆积。
- Active UNIX domain sockets:有源 UNIX 域套接口,其中 proto 显示连接使用的协议,RefCnt 表示连接到本套接口上的进程号,Types 是套接口的类型,State 是套接口当前的状态,Path 是连接到套接口的进程使用的路径名。
(2)netstat -i 显示网络接口信息

接口信息包括网络接口名称(Iface)、MTU,以及一系列接收(RX-)和传输(TX-)的指标。其中 OK 表示传输成功的包,ERR 是错误包,DRP 是丢包,OVR 是超限包。
这些参数有助于我们对网络收包情况进行分析,从而判断瓶颈所在。
4、ifstat
ifstat 主要用来监测主机网口的网络流量,常用的选项包括:
- -a:监测主机所有网口
- -i:指定要监测的网口
- -t:在每行输出信息前加上时间戳
- -b:以 Kbit/s 显示流量数据,而不是默认的 KB/s
- delay:采样间隔(单位是 s),即每隔 delay 的时间输出一次统计信息
- count:采样次数,即共输出 count 次统计信息
比如,通过以下命令统计主机所有网口某一段时间内的流量数据:

可以看出,分别统计了三个网口的流量数据,前面输出的时间戳,有助于我们统计一段时间内各网口总的输入、输出流量。
5、netcat
netcat,简称 nc,命令简单,但功能强大,在排查网络故障时非常有用,因此它也在众多网络工具中有着“瑞士军刀”的美誉。
它主要被用来构建网络连接。可以以客户端和服务端的方式运行,当以服务端方式运行时,它负责监听某个端口并接受客户端的连接,因此可以用它来调试客户端程序;当以客户端方式运行时,它负责向服务端发起连接并收发数据,因此也可以用它来调试服务端程序,此时它有点像 Telnet 程序。
常用的选项包括以下几种:
- -l:以服务端的方式运行,监听指定的端口。默认是以客户端方式运行。
- -k:重复接受并处理某个端口上的所有连接,必须与 -l 一起使用。
- -n:使用 IP 地址表示主机,而不是主机名,使用数字表示端口号,而不是服务名称。
- -p:当以客户端运行时,指定端口号。
- -s:设置本地主机发出的数据包的 IP 地址。
- -C:将 CR 和 LF 两个字符作为结束符。
- -U:使用 UNIX 本地域套接字通信。
- -u:使用 UDP 协议通信,默认使用的是 TCP 协议。
- -w:如果 nc 客户端在指定的时间内未检测到任何输入,则退出。
- -X:当 nc 客户端与代理服务器通信时,该选项指定它们之间的通信协议,目前支持的代理协议包括 “4”(SOCKS v.4),“5”(SOCKSv.5)和 “connect” (HTTPs Proxy),默认使用 SOCKS v.5。
- -x:指定目标代理服务器的 IP 地址和端口号。
一个简单的例子,使用 nc 命令发送消息: 首先,启动服务端,用 nc -l 0.0.0.0 12345 监听端口 12345 上的所有连接。
然后,启动客户端,用 nc -p 1234 127.0.0.1 12345 使用 1234 端口连接服务器127.0.0.1::12345。
6、tcpdump
tcpdump,强大的网络抓包工具。虽然有 wireshark 这样更易使用的图形化抓包工具,但 tcpdump 仍然是网络排错的必备利器。tcpdump 选项很多,我就不一一列举了,大家可以看文章末尾的引用来进一步了解。这里列举几种 tcpdump 常用的用法。
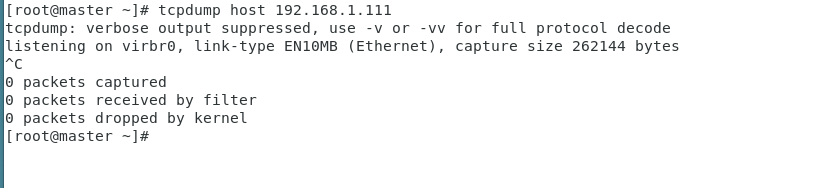
(1)捕获某主机的数据包
比如想要捕获主机192.168.1.111上所有收到和发出的所有数据包,使用:
(2)捕获多个主机的数据包
比如要捕获主机 200.200.200.1 和主机 200.200.200.2 或 200.200.200.3 的通信,使用:
tcpdump host 200.200.200.1 and \(200.200.200.2 or \)同样要捕获主机 200.200.200.1 除了和主机 200.200.200.2 之外所有主机通信的IP 包。使用:
tcpdump ip host 200.200.200.1 and ! 200.200.200.2(3)捕获某主机接收或发出的某种协议类型的包 比如要捕获主机200.200.200.1 接收或发出的 Telnet 包:
tcpdump tcp port 23 host 200.200.200.1(4)捕获某端口相关的数据包
比如捕获在端口 6666 上通过的包,使用:
tcpdump port 6666(5)捕获某网口的数据包 比如捕获在网口 eth0 上通过的包,使用:
tcpdump -i eth07、sar
sar 是一个系统历史数据统计工具。统计的信息非常全,包括 CPU、内存、磁盘I/O、网络、进程、系统调用等等信息,是一个集大成的工具,非常强大。在Linux 系统上 sar --help 一下,可以看到它的完整用法。
- -A:所有报告的总和
- -u:输出 CPU 使用情况的统计信息
- -v:输出 inode、文件和其他内核表的统计信息
- -d:输出每一个块设备的活动信息
- -r:输出内存和交换空间的统计信息
- -b:显示 I/O和传送速率的统计信息
- -a:文件读写情况
- -c:输出进程统计信息,每秒创建的进程数
- -R:输出内存页面的统计信息
- -y:终端设备活动情况
- -w:输出系统交换活动信息
- -n:输出网络设备统计信息
在平时使用中,我们常常用来分析网络状况,其他几项的通常有更好的工具来分析。所以,本文会重点介绍 sar 在网络方面的分析手法。
Linux 系统用以下几个选项提供网络统计信息:
- -n DEV:网络接口统计信息。
- -n EDEV:网络接口错误。
- -n IP:IP 数据报统计信息。
- -n EIP:IP 错误统计信息。
- -n TCP:TCP 统计信息。
- -n ETCP:TCP 错误统计信息。
- -n SOCK:套接字使用。
我们来看几个示例:
(1)每秒打印 TCP 的统计信息:
sar -n TCP 1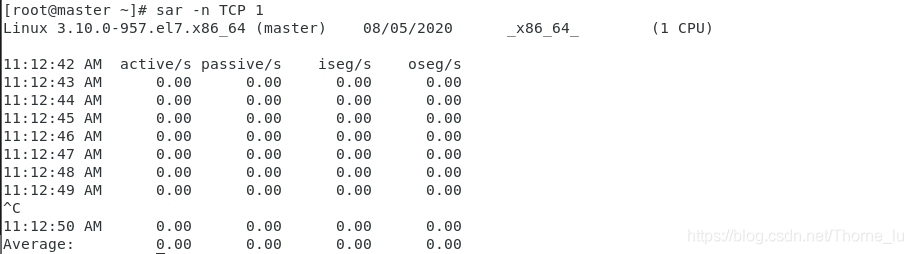
参数含义:
- active/s:新的 TCP 主动连接(也就是 socket 中的 connect() 事件),单位是:连接数/s。
- passive/s:新的 TCP 被动连接(也就是 socket 中的 listen() 事件)。
- iseg/s:接收的段(传输层以段为传输单位),单位是:段/s
- oseg/s:发送的段。 通过这几个参数,我们基本可以知道当前系统TCP 连接的负载情况。
(2)每秒打印感兴趣的网卡的统计信息:
sar -n DEV 1 | awk 'NR == 3 || $3 == "eth0"'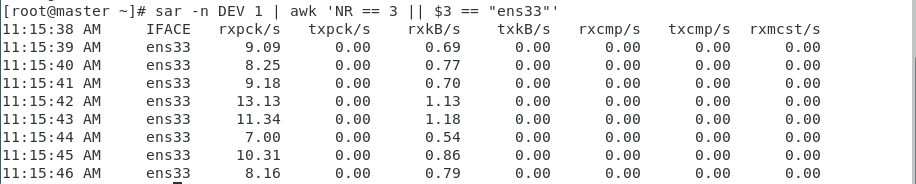
参数说明:
- rxpck/s / txpck/s:网卡接收/发送的数据包,单位是:数据包/s。
- rxkB/s / txkB/s:网卡接收/发送的千字节,单位是:千字节/s。
- rxcmp/s / txcmp/s:网卡每秒接受/发送的压缩数据包,单位是:数据包/s。
- rxmcst/s:每秒接收的多播数据包,单位是:数据包/s。
- %ifutil:网络接口的利用率。 这几个参数对于分析网卡接收和发送的网络吞吐量很有帮助。
(3)错误包和丢包情况分析:
sar -n EDEV 1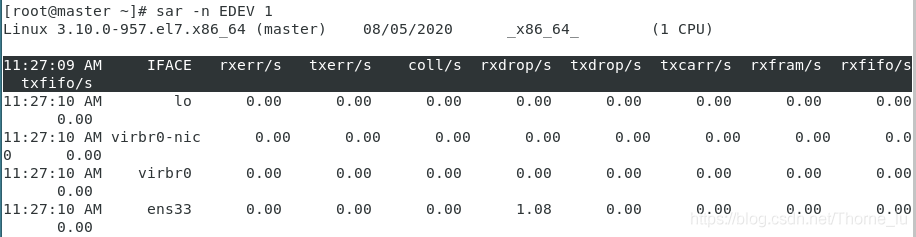
参数含义:
- rxerr/s / txerr/s:每秒钟接收/发送的坏数据包
- coll/s:每秒冲突数
- rxdrop/s:因为缓冲充满,每秒钟丢弃的已接收数据包数
- txdrop/s:因为缓冲充满,每秒钟丢弃的已发送数据包数
- txcarr/s:发送数据包时,每秒载波错误数
- rxfram/s:每秒接收数据包的帧对齐错误数
- rxfifo/s / txfifo/s:接收/发送的数据包每秒 FIFO 过速的错误数
当发现接口传输数据包有问题时,查看以上参数能够让我们快速判断具体是出的什么问题。
8、tranceroute
traceroute 也是一个排查网络问题的好工具,它能显示数据包到达目标主机所经过的路径(路由器或网关的 IP 地址)。如果发现网络不通,我们可以通过这个命令来进一步判断是主机的问题还是网关的问题。
它通过向源主机和目标主机之间的设备发送一系列的探测数据包(UDP 或者ICMP)来发现设备的存在,实现上利用了递增每一个包的 TTL 时间,来探测最终的目标主机。比如开始 TTL = 1,当到达第一个网关设备的时候,TTL - 1,当
TTL = 0 导致网关响应一个 ICMP 超时报文,这样,如果没有防火墙拦截的话,源主机就知道网关设备的地址。以此类推,逐步增加 TTL 时间,就可以探测到目标主机之间所经过的路径。
为了防止发送和响应过程出现问题导致丢包,traceroute 默认会发送 3 个探测包,我们可以用 -q x 来改变探测的数量。如果中间设备设置了防火墙限制,会导致源主机收不到响应包,就会显示 * 号。如下是 traceroute baidu 的结果:
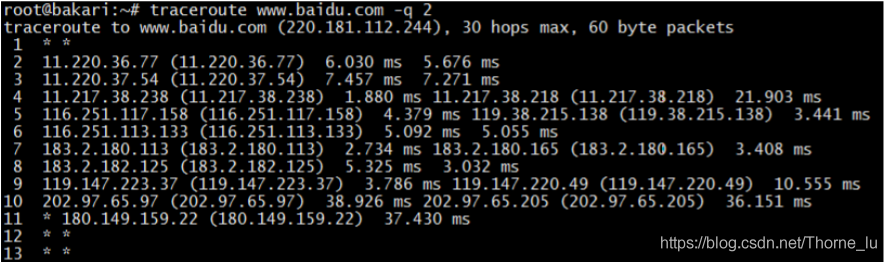
每一行默认会显示设备名称(IP 地址)和对应的响应时间。发送多少个探测包,就显示多少个。如果只想显示 IP 地址可以用 -n 参数,这个参数可以避免DNS 域名解析,加快响应时间。
Linux服务器性能调优
为磁盘I/O调整Linux内核电梯算法
选择文件系统后,该算法可以平衡低延迟需求,收集足够数据,有效组织对磁盘读写请求。
禁用不必要的守护进程,节省内存和CPU资源
许多守护进程或服务通常非必需,消耗宝贵内存和CPU时间。将服务器置于险地。
禁用可加快启动时间,释放内存。
减少CPU要处理的进程数。
一些应被禁用的Linux守护进程,默认自动运行:
- Apmd:高级电源管理守护进程。
- Nfslock:用于NFS文件锁定。
- Isdn:ISDN Moderm支持
- Autofs:在后台自动挂载文件系统(如自动挂载CD-ROM)
- Sendmail:邮件传输代理
- Xfs:X Window的字体服务器
关掉GUI
清理不必要的的模块或功能
服务器软件包中太多被启动的功能或模块实际上是不需要的(如Apache中的许多功能模块),禁用掉有助于提高系统内存可用量,腾出资源给那些真正需要的软件,让它们运行得更快。
禁用控制面板
在Linux中,有许多流行的控制面板,如Cpanel,Plesk,Webmin和phpMyAdmin等,禁用释放出大约120MB内存,内存使用量大约下降30-40%。
改善Linux Exim服务器性能
使用DNS缓存守护进程,可降低解析DNS记录需要的带宽和CPU时间,DNS缓存通过消除每次都从根节点开始查找DNS记录的需求,从而改善网络性能。
Djbdns是一个非常强大的DNS服务器,它具有DNS缓存功能,Djbdns比BIND DNS服务器更安全,性能更好,可以直接通过http://cr.yp.to/下载,或通过Red Hat提供的软件包获得。
使用AES256增强gpg文件加密安全
为提高备份文件或敏感信息安全,许多Linux系统管理员都使用gpg进行加密,在使用gpg时,最好指定gpg使用AES256加密算法,AES256使用256位密钥,它是一个开放的加密算法,美国国家安全局(NSA)使用它保护绝密信息。
远程备份服务安全
安全是选择远程备份服务最重要的因素,大多数系统管理员都害怕两件事:(黑客)可以删除备份文件,不能从备份恢复系统。
为了保证备份文件100%的安全,备份服务公司提供远程备份服务器,使用scp脚本或RSYNC通过SSH传输数据,这样,没有人可以直接进入和访问远程系统,因此,也没有人可以从备份服务删除数据。在选择远程备份服务提供商时,最好从多个方面了解其服务强壮性,如果可以,可以亲自测试一下。
更新默认内核参数设置
为了顺利和成功运行企业应用程序,如数据库服务器,可能需要更新一些默认的内核参数设置,例如,2.4.x系列内核消息队列参数msgmni有一个默认值(例如,共享内存,或shmmax在Red Hat系统上默认只有33554432字节),它只允许有限的数据库并发连接,下面为数据库服务器更好地运行提供了一些建议值(来自IBM DB2支持网站):
kernel.shmmax=268435456 (32位)
kernel.shmmax=1073741824 (64位)
kernel.msgmni=1024
fs.file-max=8192
kernel.sem="250 32000 32 1024"
优化TCP
优化TCP协议有助于提高网络吞吐量,跨广域网的通信使用的带宽越大,延迟时间越长时,建议使用越大的TCP Linux大小,以提高数据传输速率,TCP Linux大小决定了发送主机在没有收到数据传输确认时,可以向接收主机发送多少数据。
选择正确的文件系统
使用ext4文件系统取代ext3。
- Ext4是ext3文件系统的增强版,扩展了存储限制。
- 具有日志功能,保证高水平的数据完整性(在非正常关闭事件中)。
- 非正常关闭和重启时,它不需要检查磁盘(这是一个非常耗时的动作)。
- 更快的写入速度,ext4日志优化了硬盘磁头动作。
使用noatime文件系统挂载选项
在文件系统启动配置文件fstab中使用noatime选项,如果使用了外部存储,这个挂载选项可以有效改善性能。
调整Linux文件描述符限制
Linux限制了任何进程可以打开的文件描述符数量,默认限制是每进程1024,这些限制可能会阻碍基准测试客户端(如httperf和apachebench)和Web服务器本身获得最佳性能,Apache每个连接使用一个进程,因此不会受到影响,但单进程Web服务器,如Zeus是每连接使用一个文件描述符,因此很容易受默认限制的影响。
打开文件限制一个可以用ulimit命令调整的限制,ulimit -aS命令显示当前的限制,ulimit -aH命令显示硬限制(在未调整/proc中的内核参数前,你不能增加限制)。
正确配置字MySQL
为了给MySQL分配更多的内存,可设置MySQL缓存大小,要是MySQL服务器实例使用了更多内存,就减少缓存大小,如果MySQL在请求增多时停滞不动,就增加MySQL缓存。
正确配置Apache
检查Apache使用了多少内存,再调整StartServers和MinSpareServers参数,以释放更多的内存,将有助于你节省30-40%的内存。
分析Linux服务器性能
提高系统效率最好的办法是找出导致整体速度下降的瓶颈并解决掉,下面是找出系统关键瓶颈的一些基本技巧:
- 当大型应用程序,如OpenOffice和Firefox同时运行时,计算机可能会开始变慢,内存不足的出现几率更高。
- 如果启动时真的很慢,可能是应用程序初次启动需要较长的加载时间,一旦启动好后运行就正常了,否则很可能是硬盘太慢了。
- CPU负载持续很高,内存也够用,但CPU利用率很低,可以使用CPU负载分析工具监控负载时间。
学习5个Linux性能命令
使用几个命令就可以管理Linux系统的性能了,下面列出了5个最常用的Linux性能命令,包括top、vmstat、iostat、free和sar,它们有助于系统管理员快速解决性能问题。
(1)top
当前内核服务的任务,还显示许多主机状态的统计数据,默认情况下,它每隔5秒自动更新一次。
如:当前正常运行时间,系统负载,进程数量和内存使用率,
此外,这个命令也显示了那些使用最多CPU时间的进程(包括每个进程的各种信息,如运行用户,执行的命令等)。
(2)vmstat
vmstat命令提供当前CPU、IO、进程和内存使用率的快照,它和top命令类似,自动更新数据,如:
$ vmstat 10(3)iostat
iostat提供三个报告:CPU利用率、设备利用率和网络文件系统利用率,使用-c,-d和-h参数可以分别独立显示这三个报告。
(4)free
显示主内存和交换空间内存统计数据,指定-t参数显示总内存,指定-b参数按字节为单位,使用-m则以兆为单位,默认情况下千字节为单位。
free命令也可以使用-s参数加一个延迟时间(单位:秒)连续运行,如:
$ free -s 5(5)sar
收集,查看和记录性能数据,这个命令比前面几个命令历史更悠久,它可以收集和显示较长周期的数据。
将日志文件转移到内存中
当一台机器处于运行中时,最好是将系统日志放在内存中,当系统关闭时再将其复制到硬盘,当你运行一台开启了syslog功能的笔记本电脑或移动设备时,ramlog可以帮助你提高系统电池或移动设备闪存驱动器的寿命,使用ramlog的一个好处是,不用再担心某个守护进程每隔30秒向syslog发送一条消息,放在以前,硬盘必须随时保持运转,这样对硬盘和电池都不好。
先打包后写入
在内存中划分出固定大小的空间保存日志文件,这意味着笔记本电脑硬盘不用一直保持运转,只有当某个守护进程需要写入日志时才运转,注意ramlog使用的内存空间大小是固定的,否则系统内存会很快被用光,如果笔记本使用固态硬盘,可以分配50-80MB内存给ramlog使用,ramlog可以减少许多写入周期,极大地提高固态硬盘的使用寿命。
一般调优技巧
尽可能使用静态内容替代动态内容,如果你在生成天气预告,或其它每隔1小时就必须更新的数据,最好是写一个程序,每隔1小时生成一个静态的文件,而不是让用户运行一个CGI动态地生成报告。
为动态应用程序选择最快最合适的API,CGI可能最容易编程,但它会为每个请求产生一个进程,通常,这是一个成本很高,且不必要的过程,FastCGI是更好的选择,和Apache的mod_perl一样,都可以极大地提高应用程序的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号