Linux下查看日志用到的常用命令
作为一名后端程序员,和Linux打交道的地方很多,不会看Linux日志,非常容易受到来自同事和面试官的嘲讽,所以掌握一种或者几种查看日志的方法非常重要。
Linux查看日志的命令有多种:tail、cat、tac、head、echo等,本文只介绍几种常用的方法。
grep命令
Linux 文本操作的三大神器:grep、sed、awk。
各自的最佳应用场景:
- grep:使用正则表达式搜索文本,并把匹配的行打印出来,是强大的文本搜索工具;
- sed:用于编辑匹配到的文本,是一种流编辑器;
- awk:能够对文本进行复杂的格式处理,是一种处理文本的语言。
我们首先要学习grep命令。
命令功能
grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。主要功能是在文件中查找/过滤所需要的内容。
比如查看 ip 地址的命令:
ifconfig | grep inet
命令格式
格式:grep [option] pattern file
其中,option 是 grep 命令的参数,pattern 是所需查找/过滤的内容,file 是指定的文件。
命令参数
- -A<显示行数>:除了显示匹配 pattern 的那一行外,显示该行之后的内容
- -B<显示行数>:除了显示匹配 pattern 的那一行外,显示该行之前的内容
- -C<显示行数>:除了显示匹配 pattern 的那一行外,显示该行前、后的内容
- -c:统计匹配的行数
- -e:同时匹配多个pattern
- -i:忽略字符的大小写
- -n:显示匹配的行号
- -o:只显示匹配的字符串
- -v:显示没有匹配pattern的那一行,相当于反向匹配
- -w:匹配整个单词
grep应用示例
比如有一个hello.txt,内容如下:
aaa
bbb
ccc
aaaAAA
bbbBBB
cccCCC
helloworld
hello world通过设定不同命令参数的示例如下:

同时匹配多个pattern(-e)和忽略大小写(-i)很方便查找:

显示行号(-n)可以快速定位:

反向匹配(-v)也经常用到:

常用的正则表达式
常用的正则表达式:
- .:任意单个字符
- *:任意字符多次
- []:指定范围,如[0-9]、[a-z]、[A-Z]、[0-9a-zA-Z]
- ^:行首
- $:行尾
- ^$:空行
比如有一个hello.txt,内容如下:

使用正则表达式的匹配示例:

常用语法总结
过滤以“abc”开头的行:grep "^abc"
过滤不包含"abc"的行:grep -v "abc"
过滤包含"abc"的行并查看最后两行:grep "adb" | tail -n 2
过滤包含"abc"的行并查看最前面一行:grep -m 1 "adb"
过滤包含"abc"的行并查看第一项(和上面的区别是,如果如果第一行有多个匹配项,上面会显示整行,这里只会显示第一行的第一项):grep -m 1 "adb" | head 1
过滤包含"abc"的行并显示前面两行和后面三行:grep -B2 -A3 "adb"
过滤包含"abc"的行并显示前面两行和后面两行:grep -C2 "adb"tail命令
命令格式:
tail [参数] [文件]参数:
- -f 循环读取
- -q 不显示处理信息
- -v 显示详细的处理信息
- -c<数目> 显示的字节数
- -n<行数> 显示行数
- -q, --quiet, --silent 从不输出给出文件名的首部
- -s, --sleep-interval=S 与-f合用,表示在每次反复的间隔休眠S秒
用法如下:
tail -n 10 test.log 查询日志尾部最后10行的日志;
tail -n +10 test.log 查询10行之后的所有日志;
tail -fn 1000 test.log 循环实时查看最后1000行记录(最常用的)一般还会配合着grep用,例如:
tail -fn 1000 test.log | grep '关键字'如果一次性查询的数据量太大,可以进行翻页查看,例如:
tail -n 4700 aa.log |more -1000 可以进行多屏显示(ctrl + f 或者 空格键可以快捷键)head命令
跟tail是相反的head是看前多少行日志。
head -n 10 test.log 查询日志文件中的头10行日志;
head -n -10 test.log 查询日志文件除了最后10行的其他所有日志;head其他参数参考tail。
cat命令
cat 是由第一行到最后一行连续显示在屏幕上。
一次显示整个文件:
cat -n filename从键盘创建一个文件:
cat > filename将几个文件合并为一个文件:
cat file1 file2 > file 只能创建新文件,不能编辑已有文件将一个日志文件的内容追加到另外一个:
cat -n textfile1 > textfile2清空一个日志文件:
cat : >textfile2注意:> 意思是创建,>>是追加。千万不要弄混了。
cat也可以跟tail一样使用grep进行关键字的过滤。
如果需要实现多个关键字同时包含,可以进行“与”操作,例如:
cat test.log| grep "abc" | grep "123"如果需要打印出文件test.log中匹配包含“abc"或者包含"123"的行,可以用如下方式:
cat test.log | grep "abc|123"more命令
more命令是一个基于vi编辑器文本过滤器,它以全屏幕的方式按页显示文本文件的内容,支持vi中的关键字定位操作。more名单中内置了若干快捷键,常用的有H(获得帮助信息),Enter(向下翻滚一行),空格(向下滚动一屏),Q(退出命令)。more命令从前向后读取文件,因此在启动时就加载整个文件。
该命令一次显示一屏文本,满屏后停下来,并且在屏幕的底部出现一个提示信息,给出至今己显示的该文件的百分比:–More–(XX%)
- more的语法:more 文件名
- Enter 向下n行,需要定义,默认为1行
- Ctrl f 向下滚动一屏
- 空格键 向下滚动一屏
- Ctrl b 返回上一屏
- = 输出当前行的行号
- :f 输出文件名和当前行的行号
- v 调用vi编辑器
- !命令 调用Shell,并执行命令
- q退出more
sed命令
这个命令可以查找日志文件特定的一段 , 根据时间的一个范围查询,可以按照行号和时间范围查询。
按照行号:
sed -n '5,10p' filename 这样你就可以只查看文件的第5行到第10行。按照时间段:
sed -n '/2014-12-17 16:17:20/,/2014-12-17 16:17:36/p' test.logless命令
命令格式:
less [参数] 文件 less命令在查询日志时,一般流程是这样的:
- 进入到日志所在目录;
- 命令行输入less cas.logs;
- 从键盘输入/,进入编辑模式;
- 输入想要在日志中查找的东西,如:/20220715;
- 回车,查出所有相关信息;
- 按n键,查看下一条被搜索出的内容,按b,查看上一条内容;
- q退出编辑模式;
- Ctrl+Z退出日志;
常用的命令参数:
-b <缓冲区大小> 设置缓冲区的大小
-e 当文件显示结束后,自动离开
-f 强迫打开特殊文件,例如外围设备代号、目录和二进制文件
-g 只标志最后搜索的关键词
-i 忽略搜索时的大小写
-m 显示类似more命令的百分比
-N 显示每行的行号
-o <文件名> 将less 输出的内容在指定文件中保存起来
-Q 不使用警告音
-s 显示连续空行为一行
-S 行过长时间将超出部分舍弃
-x <数字> 将“tab”键显示为规定的数字空格按键操作:
/字符串:向下搜索“字符串”的功能
?字符串:向上搜索“字符串”的功能
n:重复前一个搜索(与 / 或 ? 有关)
N:反向重复前一个搜索(与 / 或 ? 有关)
b 向后翻一页
d 向后翻半页
h 显示帮助界面
Q 退出less 命令
u 向前滚动半页
y 向前滚动一行
空格键 滚动一行
回车键 滚动一页
[pagedown]: 向下翻动一页
[pageup]: 向上翻动一页Linux日志文件说明:
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一
/var/log/secure 与安全相关的日志信息
/var/log/maillog 与邮件相关的日志信息
/var/log/cron 与定时任务相关的日志信息
/var/log/spooler 与UUCP和news设备相关的日志信息
/var/log/boot.log 守护进程启动和停止相关的日志消息
/var/log/wtmp 该日志文件永久记录每个用户登录、注销及系统的启动、停机的事件指定日志时间段
测试过程中,经常会出现一闪而过的错误信息提示,没来得及截图, 要想复现,有些许困难。留给开发去定位问题的,只能是提供当时错误信息提示的大概时间, 如2020-07-20 13:00 -13:10 这个时间段,去后台找日志。
以下是2种查看指定时间段日志的命令,比较常用。
日志文件如下-仅供测试:
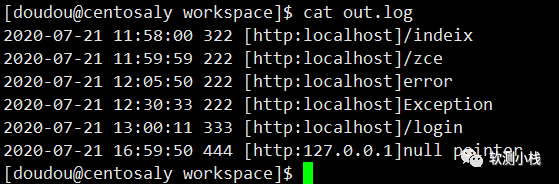
要求:查询2020-07-21 11:58:00~ 12:05:50 这个时间段的日志
1、方法一:使用grep命令
grep -E '2020-07-21 1[1-2]:[5-0][8-5]:[0-5]0' out.log执行结果:Invalid range end
正则表达式匹配的数字 为:[0-9] 等价于 [[:digit:]] 因此以上命令不可用。
换种思路:11:58:00 ~ 12:05:50 这个时间段 拆分为 11:58:00~11:59:59 和12:00:00~12.05:50,命令如下:
grep -E '2020-07-21 11:5[8-9]:[0-5][0-9]|2020-07-21 12:0[0-5]:[0-5]0' out.loggrep -E 选项可以用来扩展选项为正则表达式。如果使用了grep 命令的选项-E,则应该使用 | 来分割多个pattern,以此实现OR操作。
2、方法二:使用sed 命令
sed -n '/2020-07-21 11:58:00/,/2020-07-21 12:05:50/p' out.logsed 选项说明:
- -n选项:只显示匹配处理的行(不加会输出所有)
- -p选项:打印
-n 和-p 经常一起使用。
在日志文件中查找关键字前后多少行
1、方式一:
(1)cat -n pom.xml | grep abc
上面的命令是打开pom.xml文件,并显示行号,查找关键字abc,这个-n就是显示pom.xml这个文件的行号。
(2)cat -n pom.xml | tail -n +13 | head -n 6
tail -n +13意思是从文件的第13行往后显示,head -n 6 的意思是显示13行后的6行
总结:先求得关键字的行号,比如求得关键字的行号是100行。
2、方式二:
cat filename |grep 关键字 -C10 上面显示关键字的前后10行 -C显示前后多少行
cat filename |grep 关键字 -A10 上面显示关键字的后10行 -A显示后多少行
cat filename |grep 关键字 -B10 上面显示关键字的前10行 -B显示前多少行
