【Java并发编程篇】线程池的创建及工作原理 和 Executor 框架
什么是线程池
线程池主要是为了解决新任务执行时,应用程序为任务创建一个新线程以及任务执行完毕时,销毁线程所带来的开销。通过线程池,可以在项目初始化时就创建一个线程集合,然后在需要执行新任务时重用这些线程而不是每次都新建一个线程,一旦任务已经完成了,线程回到线程池中并等待下一次分配任务,达到资源复用的效果。
线程池主要优势有:
(1)降低资源消耗:通过池化技术重复利用已创建的线程,降低线程创建和销毁造成的损耗。
(2)提高响应速度:任务到达时,无需等待线程创建即可立即执行。
(3)提高线程的可管理性:线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会因为线程的不合理分布导致资源调度失衡,降低系统的稳定性。使用线程池可以进行统一的分配、调优和监控。
(4)提供更多更强大的功能:线程池具备可拓展性,允许开发人员向其中增加更多的功能。比如延时定时线程池ScheduledThreadPoolExecutor,就允许任务延期执行或定期执行。
创建线程池
通过Executors创建线程池
在JUC包中的Executors中,提供了一些静态方法,用于快速创建线程池,常见的线程池有:
(1)newSingleThreadExecutor:创建一个只有一个线程的线程池,串行执行所有任务,即使空闲时也不会被关闭。可以保证所有任务的执行顺序按照任务的提交顺序执行。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。
适用场景:需要保证顺序地执行各个任务;并且在任意时间点,不会有多个线程活动的应用场景。
(2)newFixedThreadPool:创建一个固定线程数量的线程池(corePoolSize == maximumPoolSize,使用LinkedBlockingQuene作为阻塞队列)。初始化时线程数量为零,之后每次提交一个任务就创建一个线程,直到线程达到线程池的最大容量。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
适用场景:为了满足资源管理的需求,而需要限制当前线程数量的应用场景,它适用于负载比较重的服务器。
(3)newCachedThreadPool:创建一个可缓存的线程池,线程的最大数量为Integer.MAX_VALUE。空闲线程会临时缓存下来,线程会等待60s还是没有任务加入的话就会被关闭。
适用场景:适用于执行很多的短时间异步任务的小程序,或者是负载较轻的服务器。
(4)newScheduledThreadPool:创建一个支持执行延迟任务或者周期性执行任务的线程池。
ThreadPoolExecutor构造函数参数的说明
使用Executors创建的线程池,其本质都是通过不同的参数构造一个ThreadPoolExecutor对象,主要包含以下7个参数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 省略...
}(1)corePoolSize:线程池中的核心线程数,当提交一个任务时,线程池创建一个新线程执行任务,直到当前线程数等于corePoolSize;如果当前线程数为corePoolSize,继续提交的任务被保存到阻塞队列workQueue中,等待被执行;如果执行了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有核心线程。
(2)maximumPoolSize:线程池中允许的最大线程数。如果当前workQueue满了之后可以创建的最大线程数。
(3)keepAliveTime:空闲线程(非核心线程)的存活时间。
(4)unit:keepAliveTime空闲线程存活时间的单位;
(5)workQueue:阻塞队列,用来存放等待被执行的任务,且任务必须实现Runnable接口,在JDK中提供了如下阻塞队列:
- ArrayBlockingQueue:基于数组结构的有界阻塞队列,按FIFO排序任务;
- LinkedBlockingQuene:基于链表结构的阻塞队列,按FIFO排序任务,吞吐量通常要高于ArrayBlockingQuene;
- SynchronousQuene:一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene
- PriorityBlockingQuene:具有优先级的无界阻塞队列;
- DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
- LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
(6)threadFactory:线程工厂,主要用来创建线程,默认为正常优先级、非守护线程。
(7)handler:线程池拒绝任务时的处理策略。
不要使用Executors创建线程池
阿里巴巴开发手册并发编程有一条规定:线程池不允许使用Executors去创建,而是通过ThreadPoolExecutor的方式,这是为什么呢?主要是因为这样的可以避免资源耗尽的风险,因为使用Executors返回线程池对象的弊端有:
(1)FixedThreadPool 和 SingleThreadPool 允许的阻塞队列长度为 Integer.MAX_VALUE,这样会导致堆积大量的请求,从而导致OOM;
(2)CachedThreadPool 允许创建的线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
所以创建线程池,最好是根据线程池的用途,然后自己创建线程池。
线程池执行策略
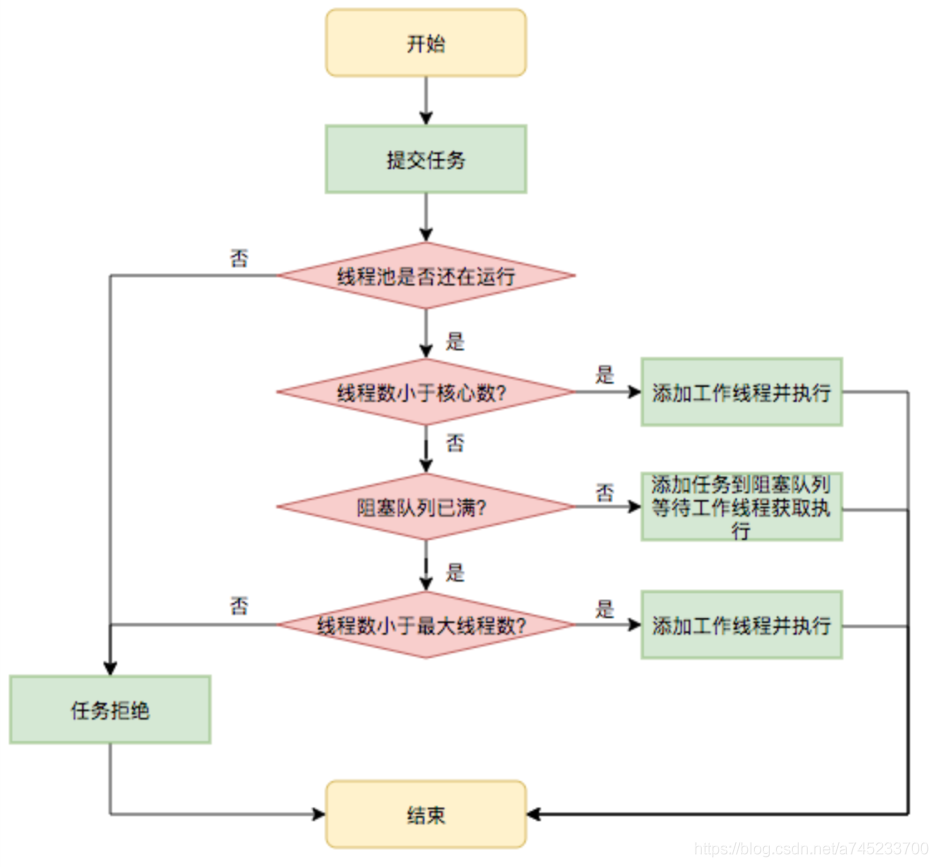
执行逻辑说明:
(1)当客户端提交任务时,线程池先判断核心线程数是否小于corePoolSize,如果是,则创建新的核心线程数运行这个任务;
(2)如果正在运行的线程数大于或等于corePoolSize,则判断workQueue队列是否已满,如果未满,则将任务放入workQueue中;
(3)如果workQueue队列已经满了,则判断当前线程池中的线程数量是否大于maximumPoolSize,如果小于maximumPoolSize,则启动一个非核心线程来执行任务;
(4)如果线程池中线程数量大于或等于maximumPoolSize,那么线程池会根据设定的拒绝策略,做出相应的措施。
- ThreadPoolExecutor.AbortPolic(默认):抛出RejectedExecutionException异常;
- ThereadPoolExecutor.CallerRunsPolicy:在当前正在执行的线程的execute方法中运行被拒绝的任务。
- ThreadPoolExecutor.DiscardOldestPoliy:丢弃workQueue中等待最长时间的任务,并将被拒绝的任务添加到队列之中。
- ThreadPoolExecutor.DiscardPolicy:将直接丢弃此线程。
(5)当一个线程完成任务时,它会从workQueue中获取下一个任务来执行。
(6)当一个线程空闲超过keepAliveTime设定的时间时,线程池会判断,如果当前线程数大于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
如何合理的配置线程池的大小
1、一般都是根据任务类型来配置线程池大小
- 如果是 CPU 密集型:那么就意味着 CPU 是稀缺资源,这个时候通常不能通过增加线程数来提高计算能力,因为线程数量太多,会导致频繁的上下文切换,一般这种情况下,建议合理的线程数值 = CPU数 + 1,减少线程上下文的切换;
- 如果是 IO 密集型:说明需要较多的等待,因为 IO 操作并不占用CPU,大部分线程都阻塞,所以可以多配置线程数,让CPU处理更多的业务,这个时候可以参考 Brain Goetz 的推荐方法,线程数 = CPU核数 × (1 + 平均等待时间/平均工作时间)。参考值可以是 N(CPU) 核数 * 2。
当然,这只是一个参考值,具体的设置还需要根据实际情况进行调整,比如可以先将线程池大小设置为参考值,再观察任务运行情况和系统负载、资源利用率来进行适当调整。
2、有界队列和无界队列的配置
一般情况下配置有界队列,在一些可能会有爆发性增长的情况下使用无界队列。任务非常多时,使用非阻塞队列并使用CAS操作替代锁可以获得好的吞吐量。
Executor 框架
什么是 Executor 框架
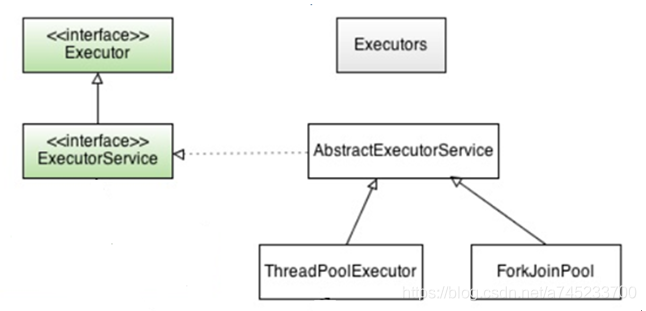
Executor 是一个用于任务执行和调度的框架,目的是将任务的提交过程与执行过程解耦,使得用户只需关注任务的定义和提交,而不需要关注具体如何执行以及何时执行;其中,最顶层是 Executor 接口,它只有一个用于执行任务的 execute() 方法。Executor框架主要由3大部分组成:
(1)任务:实现 Callable 接口或 Runnable 接口的类,其实例就可以成为一个任务提交给 ExecutorService 去执行。其中 Callable 任务可以返回执行结果,Runnable 任务无返回结果。
(2)任务的执行:包括任务执行机制的核心接口 Executor,以及继承自 Executor 的 ExecutorService 接口。Executor框架的关键类ThreadPoolExecutor 也实现了 ExecutorService 接口;
(3)任务的异步计算结果:包括 Future 接口和实现 Future 接口的 FutureTask 类、ForkJoinTask 类。
使用步骤
把任务,如 Runnable 接口或 Callable 接口的实现类提交(submit、execute)给线程池执行,如 ExecutorService、ThreadPoolExecutor 等。线程执行完毕之后,会返回一个异步计算结果 Future,然后调用 Future 的 get()方法等待执行结果即可,Future 的 get() 方法会导致主线程阻塞,直到任务执行完成。
其中 Runnable 任务无返回结果,Callable 任务可以返回执行结果,Callable 任务除了返回正常结果之外,如果发生异常,该异常也会被返回,即 Future 可以拿到异步执行任务各种结果;在实际业务场景中,Future 和 Callable 基本是成对出现的,Callable 负责产生结果,Future 负责获取结果。
另外,还有一个 Executors 类,它是一个工具类,提供了创建 ExecutorService、ScheduledExecutorService、ThreadFactory 和 Callable 对象的静态方法。
线程池中 submit() 和 execute() 方法有什么区别?
两个方法都可以向线程池提交任务,execute() 方法的返回类型是 void,它定义在 Executor 接口中, 而 submit() 方法可以返回持有计算结果的 Future 对象,它定义在 ExecutorService 接口中,它扩展自 Executor 接口,其它线程池类像 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 都有这些方法。
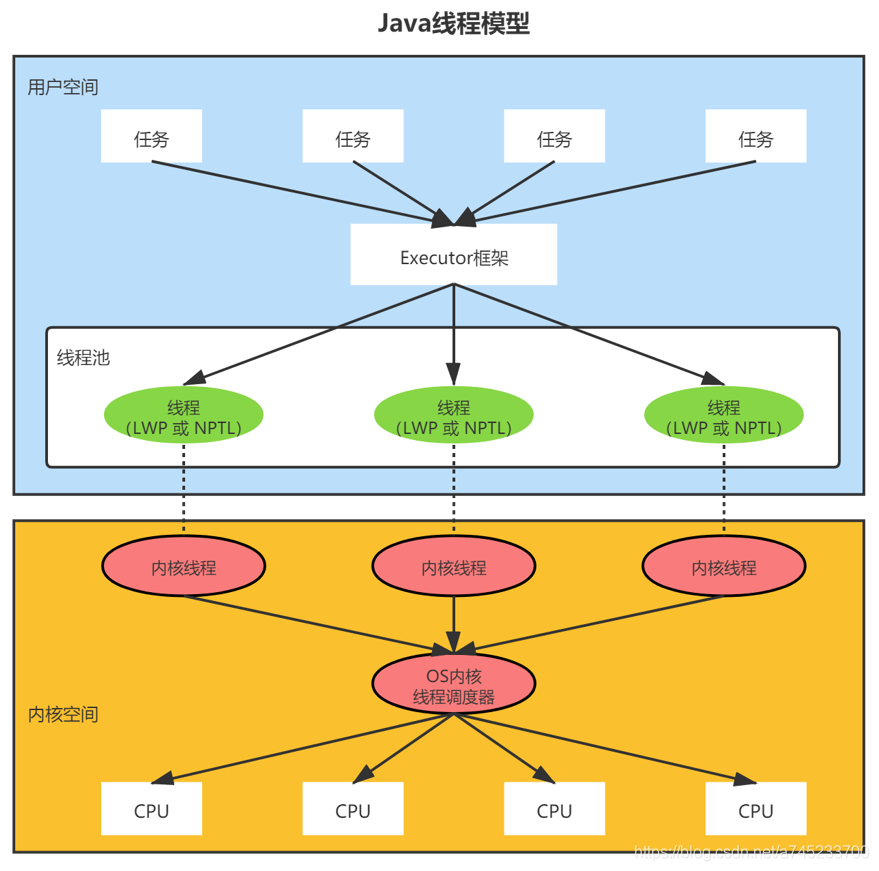
Java线程模型:Java线程与操作系统线程的关系
Java 线程的本质,其实就是操作系统中的线程,Java 线程的实现是基于一对一的线程模型,通过语言级别层面程序去间接调用系统内核的线程模型,即在使用 Java 线程时,JVM 是转而调用当前操作系统的内核线程来完成当前任务。内核线程就是由操作系统内核支持的线程,这种线程是由操作系统内核来完成线程切换,内核通过操作调度器进而对线程执行调度,并将线程的任务映射到各个处理器上。
由于我们编写的多线程程序属于语言层面的,程序不会直接去调用内核线程,取而代之的是一种轻量级的进程(Light Weight Process),也是通常意义上的线程,由于每个轻量级进程都会映射到一个内核线程,因此我们可以通过轻量级进程调用内核线程,进而由操作系统内核将任务映射到各个处理器,这种轻量级进程与内核线程间1对1的关系就称为一对一的线程模型。
Java 线程模型如下图所示,每个线程最终都会映射到CPU中进行处理,如果CPU存在多核,那么一个CPU将可以并行执行多个线程任务:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类