浅析@Configuration注解的处理器:ConfigurationClassPostProcessor(ConfigurationClassParser)
在Spring3.0以后,官方推荐我们使用注解去驱动Spring应用。那么很多人就一下子懵了,不需要xml配置文件了,那我的那些配置项怎么办呢?
@Configuration是Spring3.0推出来的注解,用来代替xml配置文件。若一个Class类被标注了这个注解,我们就认为这个类就是一个配置类,然后在这个类里面就可以写相应的其它配置了,比如@Bean等等。既然@Configuration这么重要,它也作为管理其它配置、读取其它配置的入口,大多数小伙伴却并不知道它加载的时机以及解析的方式,这就造成了遇到一些稍微复杂点的问题时,无法入手去定位问题。
本文旨在介绍一下Spring是怎么解析@Configuration注解驱动的配置文件的,这里ConfigurationClassPostProcessor处理器就闪亮登场了~
@Configuration源码:
@Target(ElementType.TYPE) // 它只能标注在类上
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component // 它也是个Spring的组件,会被扫描
public @interface Configuration {
@AliasFor(annotation = Component.class)
String value() default ""; //也可以自定义Bean的名称
}ConfigurationClassPostProcessor初识
public class ConfigurationClassPostProcessor implements BeanDefinitionRegistryPostProcessor,
PriorityOrdered, ResourceLoaderAware, BeanClassLoaderAware, EnvironmentAware { ... }可以看出它是一个BeanFactoryPostProcessor,并且它是个功能更强大些的BeanDefinitionRegistryPostProcessor,有能力去处理一些Bean的定义信息~
需要知道的是,ConfigurationClassPostProcessor是Spring内部对BeanDefinitionRegistryPostProcessor接口的唯一实现。BeanFactoryPostProcessor顶级接口的实现类如下:

ConfigurationClassPostProcessor#postProcessBeanDefinitionRegistry处理逻辑
为了更好的理解它的运行过程,我们需要知道它在什么时候调用:AbstractApplicationContext#refresh 中的第5步时(AbstractApplicationContext#refresh() 第5步 invokeBeanFactoryPostProcessors)进行调用postProcessBeanDefinitionRegistry:
@Override
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {
//根据BeanDefinitionRegistry,生成registryId 是全局唯一的。
int registryId = System.identityHashCode(registry);
// 判断,如果这个registryId 已经被执行过了,就不能够再执行了,否则抛出异常
if (this.registriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);
}
if (this.factoriesPostProcessed.contains(registryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + registry);
}
// 已经执行过的registry 防止重复执行
this.registriesPostProcessed.add(registryId);
// 调用processConfigBeanDefinitions 进行Bean定义的加载.代码如下
processConfigBeanDefinitions(registry);
}
// 解释一下:我们配置类是什么时候注册进去的呢???(此处只讲注解驱动的Spring和SpringBoot)
// 注解驱动的Spring为:自己在`MyWebAppInitializer`里面自己手动指定进去的
// SpringBoot为它自己的main引导类里去加载进来的,后面详说SpringBoot部分
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();
// 获取已经注册的bean名称(此处有7个 6个Bean+rootConfig)
String[] candidateNames = registry.getBeanDefinitionNames();
for (String beanName : candidateNames) {
BeanDefinition beanDef = registry.getBeanDefinition(beanName);
// 这个判断很有意思~~~ 如果你的beanDef现在就已经确定了是full或者lite,说明你肯定已经被解析过了,,所以再来的话输出个debug即可(其实我觉得输出warn也行~~~)
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef) || ConfigurationClassUtils.isLiteConfigurationClass(beanDef)) {
if (logger.isDebugEnabled()) {
logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);
}
}
// 检查是否是@Configuration的Class,如果是就标记下属性:full 或者lite。beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL)
// 加入到configCandidates里保存配置文件类的定义
// 显然此处,仅仅只有rootConfig一个类符合条件
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {
configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));
}
}
// Return immediately if no @Configuration classes were found
// 如果一个配置文件类都没找到,现在就不需要再继续下去了
if (configCandidates.isEmpty()) {
return;
}
// Sort by previously determined @Order value, if applicable
// 把配置文件们:按照@Order注解进行排序 这个意思是,我们@Configuration注解的配置文件是支持order排序的。(备注:普通bean不行的~~~)
configCandidates.sort((bd1, bd2) -> {
int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());
int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());
return Integer.compare(i1, i2);
});
// Detect any custom bean name generation strategy supplied through the enclosing application context
// 此处registry是DefaultListableBeanFactory 这里会进去
// 尝试着给Bean扫描方式,以及import方法的BeanNameGenerator赋值(若我们都没指定,那就是默认的AnnotationBeanNameGenerator:扫描为首字母小写,import为全类名)
SingletonBeanRegistry sbr = null;
if (registry instanceof SingletonBeanRegistry) {
sbr = (SingletonBeanRegistry) registry;
if (!this.localBeanNameGeneratorSet) {
BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(CONFIGURATION_BEAN_NAME_GENERATOR);
if (generator != null) {
this.componentScanBeanNameGenerator = generator;
this.importBeanNameGenerator = generator;
}
}
}
// web环境,这里都设置了StandardServletEnvironment
// 一般来说到此处,env环境不可能为null了~~~ 此处做一个容错处理~~~
if (this.environment == null) {
this.environment = new StandardEnvironment();
}
// Parse each @Configuration class
// 这是重点:真正解析@Configuration类的,其实是ConfigurationClassParser 这个解析器来做的
// parser 后面用于解析每一个配置类~~~~
ConfigurationClassParser parser = new ConfigurationClassParser(
this.metadataReaderFactory, this.problemReporter, this.environment,
this.resourceLoader, this.componentScanBeanNameGenerator, registry);
Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);
// 装载已经处理过的配置类,最大长度为:configCandidates.size()
Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());
do {
// 核心方法:具体详解如下
parser.parse(candidates);
// 校验 配置类不能使final的,因为需要使用CGLIB生成代理对象,见postProcessBeanFactory方法
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
// 如果Reader为null,那就实例化ConfigurationClassBeanDefinitionReader来加载Bean,并加入到alreadyParsed中,用于去重(避免譬如@ComponentScan直接互扫)
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
// 此处注意:调用了ConfigurationClassBeanDefinitionReader的loadBeanDefinitionsd的加载配置文件里面的@Bean/@Import们,具体讲解请参见下面
// 这个方法是非常重要的,因为它决定了向容器注册Bean定义信息的顺序问题~~~
this.reader.loadBeanDefinitions(configClasses);
alreadyParsed.addAll(configClasses);
candidates.clear();
// 如果registry中注册的bean的数量 大于 之前获得的数量,则意味着在解析过程中又新加入了很多,那么就需要对其进行解继续析
if (registry.getBeanDefinitionCount() > candidateNames.length) {
String[] newCandidateNames = registry.getBeanDefinitionNames();
Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));
Set<String> alreadyParsedClasses = new HashSet<>();
for (ConfigurationClass configurationClass : alreadyParsed) {
alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());
}
for (String candidateName : newCandidateNames) {
// 这一步挺有意思:若老的oldCandidateNames不包含。也就是说你是新进来的候选的Bean定义们,那就进一步的进行一个处理
// 比如这里的DelegatingWebMvcConfiguration,他就是新进的,因此它继续往下走
// 这个@Import进来的配置类最终会被ConfigurationClassPostProcessor这个后置处理器的postProcessBeanFactory 方法,进行处理和cglib增强
if (!oldCandidateNames.contains(candidateName)) {
BeanDefinition bd = registry.getBeanDefinition(candidateName);
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&
!alreadyParsedClasses.contains(bd.getBeanClassName())) {
candidates.add(new BeanDefinitionHolder(bd, candidateName));
}
}
}
candidateNames = newCandidateNames;
}
}
while (!candidates.isEmpty());
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
//如果SingletonBeanRegistry 不包含org.springframework.context.annotation.ConfigurationClassPostProcessor.importRegistry,
//则注册一个,bean 为 ImportRegistry. 一般都会进行注册的
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
//清楚缓存 元数据缓存
if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) {
// Clear cache in externally provided MetadataReaderFactory; this is a no-op
// for a shared cache since it'll be cleared by the ApplicationContext.
((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache();
}
}需要注意下面两个核心方法,是如何判断某个类是否为配置类的(判断是full模式,还是lite模式的配置文件):
//如果类上有@Configuration注解说明是一个完全(Full)的配置类
public static boolean isFullConfigurationCandidate(AnnotationMetadata metadata) {
return metadata.isAnnotated(Configuration.class.getName());
}
public static boolean isLiteConfigurationCandidate(AnnotationMetadata metadata) {
// Do not consider an interface or an annotation...
if (metadata.isInterface()) {
return false;
}
// Any of the typical annotations found?
for (String indicator : candidateIndicators) {
if (metadata.isAnnotated(indicator)) {
return true;
}
}
// Finally, let's look for @Bean methods...
try {
return metadata.hasAnnotatedMethods(Bean.class.getName());
} catch (Throwable ex) {
return false;
}
}
candidateIndicators内容如下:
private static final Set<String> candidateIndicators = new HashSet<>(8);
static {
candidateIndicators.add(Component.class.getName());
candidateIndicators.add(ComponentScan.class.getName());
candidateIndicators.add(Import.class.getName());
candidateIndicators.add(ImportResource.class.getName());
}- 如果类上有@Configuration注解说明是一个完全(Full)的配置类
- 如果类上面有@Component,@ComponentScan,@Import,@ImportResource这些注解,那么就是一个简化配置类。如果不是上面两种情况,那么有@Bean注解修饰的方法也是简化配置类。
判断是配置类了,将配置类放入到configCandidates这个BeanDefinitionHolder的集合中存储,进行下一步的操作。
完整@Configuration和Lite @Bean模式(Full模式和Lite模式的区别)?
首先看看Spring对此的定义:在ConfigurationClassUtils里:
// 只要这个类标注了:@Configuration注解就行 哪怕是接口、抽象类都木有问题
public static boolean isFullConfigurationCandidate(AnnotationMetadata metadata) {
return metadata.isAnnotated(Configuration.class.getName());
}
// 判断是Lite模式:(首先肯定没有@Configuration注解)
// 1、不能是接口
// 2、但凡只有标注了一个下面注解,都算lite模式:@Component @ComponentScan @Import @ImportResource
// 3、只有存在有一个方法标注了@Bean注解,那就是lite模式
public static boolean isLiteConfigurationCandidate(AnnotationMetadata metadata) {
// 不能是接口
if (metadata.isInterface()) {
return false;
}
// 但凡只有标注了一个下面注解,都算lite模式:@Component @ComponentScan @Import @ImportResource
for (String indicator : candidateIndicators) {
if (metadata.isAnnotated(indicator)) {
return true;
}
}
// 只有存在有一个方法标注了@Bean注解,那就是lite模式
try {
return metadata.hasAnnotatedMethods(Bean.class.getName());
}
}
// 不管是Full模式还是Lite模式,都被认为是候选的配置类 是上面两个方法的结合
public static boolean isConfigurationCandidate(AnnotationMetadata metadata) {
return (isFullConfigurationCandidate(metadata) || isLiteConfigurationCandidate(metadata));
}
// 下面两个方法是直接判断Bean定义信息,是否是配置类,至于Bean定义里这个属性啥时候放进去的,请参考
//ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)方法,它会对每个Bean定义信息进行检测(毕竟刚开始Bean定义信息是非常少的,所以速度也很快)
public static boolean isFullConfigurationClass(BeanDefinition beanDef) {
return CONFIGURATION_CLASS_FULL.equals(beanDef.getAttribute(CONFIGURATION_CLASS_ATTRIBUTE));
}
public static boolean isLiteConfigurationClass(BeanDefinition beanDef) {
return CONFIGURATION_CLASS_LITE.equals(beanDef.getAttribute(CONFIGURATION_CLASS_ATTRIBUTE));
}Full模式和Lite模式的唯一区别:Full模式的配置组件会被enhance(加强/代理),而Liter模式不会。其余使用方式都一样,比如@Bean、@Import等等。
和full模式不同的是,Lite模式不能声明Bean之间的依赖关系。也就是说入参、Java方法调用,都不能达到直接注入的效果。特别是Java方法调用,就直接进方法体了。
在常见的场景中,@Bean方法将在@Configuration类中声明,确保始终使用“完整”模式,并因此将交叉方法引用重定向到容器的生命周期管理。这可以防止@Bean通过常规Java调用意外地调用相同的方法(这也就是为什么我们用方法调用,其实还是去容器里找Bean的原因,并不是新建了一个Bean),这有助于减少在“精简”模式下操作时难以跟踪的细微错误。
例子:
@Configuration
public class AppConfig {
@Bean
public Foo foo() {
return new Foo(bar()); // 这里调用的bar()方法
}
@Bean
public Bar bar() {
return new Bar();
}
}Foo 接受一个bar的引用来进行构造器注入:这种方法声明的bean的依赖关系只有在@Configuration类的@Bean方法中有效。但是,如果换成@Component(Lite模式),则foo()方法中new Foo(bar())传入的bar()方法会每次产生一个新的Bar对象。
ConfigurationClassParser#parse
public void parse(Set<BeanDefinitionHolder> configCandidates) {
this.deferredImportSelectors = new LinkedList<>();
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
// 我们使用的注解驱动,所以会到这个parse进来处理。其实内部调用都是processConfigurationClass进行解析的
if (bd instanceof AnnotatedBeanDefinition) {
//单反有注解标注的,都会走这里来解析
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
} else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
} else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
// 最最最后面才处理实现了DeferredImportSelector接口的类,最最后哦~~
processDeferredImportSelectors();
}该方法做了三件事如下:
- 实例化deferredImportSelectors
- 遍历configCandidates进行处理。根据BeanDefinition 的类型做不同的处理,一般都会调用ConfigurationClassParser#parse 进行解析
- 处理ImportSelector
下面看看处理的核心方法processConfigurationClass:
protected void processConfigurationClass(ConfigurationClass configClass) throws IOException {
//ConfigurationCondition继承自Condition接口
// ConfigurationPhase枚举类型的作用:ConfigurationPhase的作用就是根据条件来判断是否加载这个配置类
// 两个值:PARSE_CONFIGURATION 若条件不匹配就不加载此@Configuration
// REGISTER_BEAN:无论如何,所有@Configurations都将被解析。
if (this.conditionEvaluator.shouldSkip(configClass.getMetadata(), ConfigurationPhase.PARSE_CONFIGURATION)) {
return;
}
// 如果这个配置类已经存在了,后面又被@Import进来了~~~会走这里 然后做属性合并~
ConfigurationClass existingClass = this.configurationClasses.get(configClass);
if (existingClass != null) {
if (configClass.isImported()) {
if (existingClass.isImported()) {
existingClass.mergeImportedBy(configClass);
}
// Otherwise ignore new imported config class; existing non-imported class overrides it.
return;
}
else {
// Explicit bean definition found, probably replacing an import.
// Let's remove the old one and go with the new one.
this.configurationClasses.remove(configClass);
this.knownSuperclasses.values().removeIf(configClass::equals);
}
}
// Recursively process the configuration class and its superclass hierarchy.
// 请注意此处:while递归,只要方法不返回null,就会一直do下去~~~~~~~~
SourceClass sourceClass = asSourceClass(configClass);
do {
// doProcessConfigurationClassz这个方法是解析配置文件的核心方法,此处不做详细分析
sourceClass = doProcessConfigurationClass(configClass, sourceClass);
} while (sourceClass != null);
// 保存我们所有的配置类 注意:它是一个LinkedHashMap,所以是有序的 这点还比较重要~~~~和bean定义信息息息相关
this.configurationClasses.put(configClass, configClass);
}
// 解析@Configuration配置文件,然后加载进Bean的定义信息们
// 这个方法非常的重要,可以看到它加载Bean定义信息的一个顺序~~~~
@Nullable
protected final SourceClass doProcessConfigurationClass(ConfigurationClass configClass, SourceClass sourceClass)
throws IOException {
// 先去看看内部类 这个if判断是Spring5.x加上去的,这个我认为还是很有必要的。
// 因为@Import、@ImportResource这种属于lite模式的配置类,但是我们却不让他支持内部类了
if (configClass.getMetadata().isAnnotated(Component.class.getName())) {
// Recursively process any member (nested) classes first
// 基本逻辑:内部类也可以有多个(支持lite模式和full模式,也支持order排序)
// 若不是被import过的,那就顺便直接解析它(processConfigurationClass())
// 另外:该内部class可以是private 也可以是static~~~(建议用private)
// 所以可以看到,把@Bean等定义在内部类里面,是有助于提升Bean的优先级的~~~~~
processMemberClasses(configClass, sourceClass);
}
// Process any @PropertySource annotations
for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), PropertySources.class,
org.springframework.context.annotation.PropertySource.class)) {
if (this.environment instanceof ConfigurableEnvironment) {
processPropertySource(propertySource);
}
else {
logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() +
"]. Reason: Environment must implement ConfigurableEnvironment");
}
}
// Process any @ComponentScan annotations
Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable(
sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class);
if (!componentScans.isEmpty() &&
!this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) {
for (AnnotationAttributes componentScan : componentScans) {
// The config class is annotated with @ComponentScan -> perform the scan immediately
Set<BeanDefinitionHolder> scannedBeanDefinitions =
this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName());
// Check the set of scanned definitions for any further config classes and parse recursively if needed
for (BeanDefinitionHolder holder : scannedBeanDefinitions) {
BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition();
if (bdCand == null) {
bdCand = holder.getBeanDefinition();
}
if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) {
parse(bdCand.getBeanClassName(), holder.getBeanName());
}
}
}
}
// Process any @Import annotations
//getImports方法的实现 很有意思
processImports(configClass, sourceClass, getImports(sourceClass), true);
// Process any @ImportResource annotations
AnnotationAttributes importResource =
AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class);
if (importResource != null) {
String[] resources = importResource.getStringArray("locations");
Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader");
for (String resource : resources) {
String resolvedResource = this.environment.resolveRequiredPlaceholders(resource);
configClass.addImportedResource(resolvedResource, readerClass);
}
}
// Process individual @Bean methods
Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass);
for (MethodMetadata methodMetadata : beanMethods) {
configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass));
}
// Process default methods on interfaces
processInterfaces(configClass, sourceClass);
// Process superclass, if any
if (sourceClass.getMetadata().hasSuperClass()) {
String superclass = sourceClass.getMetadata().getSuperClassName();
if (superclass != null && !superclass.startsWith("java") &&
!this.knownSuperclasses.containsKey(superclass)) {
this.knownSuperclasses.put(superclass, configClass);
// Superclass found, return its annotation metadata and recurse
return sourceClass.getSuperClass();
}
}
// No superclass -> processing is complete
return null;
}有关this.conditionEvaluator.shouldSkip()实际判断逻辑大概为:和@Conditional注解以及TypeFilter相关,具体处理逻辑这里省略。
ConfigurationClass代表一个配置类,它内部维护了一些已经解析好的但是还没有被加入进Bean定义信息的原始信息,有必要做如下解释:
// @since 3.0 它就是普通的类,基本只有get set方法
final class ConfigurationClass {
private final AnnotationMetadata metadata;
private final Resource resource;
@Nullable
private String beanName;
private final Set<ConfigurationClass> importedBy = new LinkedHashSet<>(1);
// 存储该配置类里所有标注@Bean注解的方法~~~~
private final Set<BeanMethod> beanMethods = new LinkedHashSet<>();
// 用Map保存着@ImportResource 导入进来的资源们~
private final Map<String, Class<? extends BeanDefinitionReader>> importedResources = new LinkedHashMap<>();
// 用Map保存着@Import中实现了`ImportBeanDefinitionRegistrar`接口的内容~
private final Map<ImportBeanDefinitionRegistrar, AnnotationMetadata> importBeanDefinitionRegistrars = new LinkedHashMap<>();
final Set<String> skippedBeanMethods = new HashSet<>();
}最终我归纳出一个扫描Bean的顺序(注意并不是Bean定义真正注册的顺序),解析@Configuration配置文件的顺序:
1)内部配置类:它里面还可以有普通配置类一模一样的功能,但优先级最高,最终会放在configurationClasses这个map的第一位
2)@PropertySource:这个和Bean定义没有什么关系,属于Spring配置PropertySource的范畴。这个属性优先级相对较低
3)@ComponentScan:特别的,这里扫描到的Bean定义,就直接register注册了,所以它的时机是非常早的。(另外:如果注册进去的Bean定义信息还是配置类,这里会继续parse(),能被扫描到的组件,都会被当作一个配置类来处理,最终都会放进configurationClasses这个Map里面去)
4)@Import:相对复杂点
- 若就是一个普通类(标注@Configuration与否都无所谓,反正会当作一个配置类来处理,也会放进configurationClasses缓存进去)
- 实现了ImportSelector:递归最后都成为第一步的类。若实现的是DeferredImportSelector接口,它会放在deferredImportSelectors属性里先保存着,等着外部的所有的configCandidates配置类全部解析完成后,统一processDeferredImportSelectors()。它的处理方式一样的,最终也是转为第一步的类。
- 实现了ImportBeanDefinitionRegistrar:放在ConfigurationClass.importBeanDefinitionRegistrars属性里保存着
5)@ImportResource:一般用来导入xml文件。它是先放在ConfigurationClass.importedResources属性里放着
6)@Bean:找到所有@Bean的方法,然后保存到ConfigurationClass.beanMethods属性里
7)processInterfaces:处理该类实现的接口们的default方法(标注@Bean的有效)
8)处理父类:拿到父类,每个父类都是一个配置文件来处理(比如要有任何注解)。备注:!superclass.startsWith("java")全类名不以java打头,且没有被处理过(因为一个父类可议N个子类,但只能被处理一次)
9)return null:若全部处理完成后就返回null,停止递归。
由上可见,这九步中,唯独只有@ComponentScan扫描到的Bean这个时候的Bean定义信息是已经注册上去了的,其余的都还没有真正注册到注册中心。
注意:bean的注册的先后顺序,将直接影响到Bean的覆盖(默认就是Map,后注册的肯定先注册的,当然还和scope有关)
Bean定义信息的注册顺序:
由上面步骤可知,已经解析好的所有配置类(包含内部类、扫描到的组件等等)都已经全部放进了本类的configurationClasses这个属性Map里面。因此只需要知道它在什么时候被解析的就可以知道顺序了。
解析代码:ConfigurationClassPostProcessor#processConfigBeanDefinitions方法里:
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
...
do {
parser.parse(candidates);
parser.validate();
...
// 此处就拿出了我们已经处理好的所有配置类们(该配置文件下的所有组件们~~~~)
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
...
// reader:ConfigurationClassBeanDefinitionReader最终真正实现的Bean的注册
// 关于它的原始代码 下面有着重分析,因此此处只说一个结论,顺序
this.reader.loadBeanDefinitions(configClasses);
}此处结合我的一个案例说明,此时configClasses值如下:
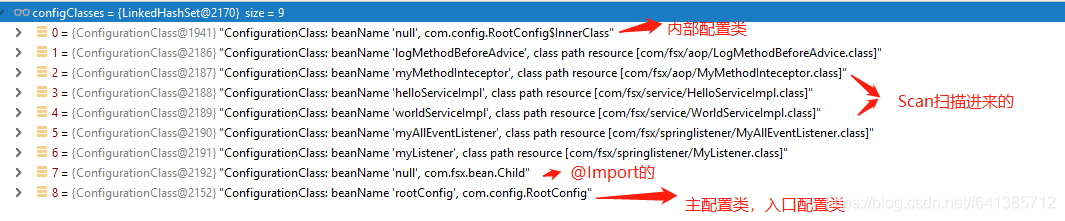
而此时Bean注册中心里已经存在的Bean定义信息如下图:(我们发现只有Scan的才真正进入注册中心,其余比如@Import的都还不在里面~)

this.reader.loadBeanDefinitions(configClasses)开始处理,参阅ConfigurationClassBeanDefinitionReader.loadBeanDefinitions()方法:
class ConfigurationClassBeanDefinitionReader {
// 对每个@Configuration 类文件做遍历(所以 Config配置文件的顺序还是挺重要的)
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
// private 方法来解析每一个已经解析好的@Configuration配置文件~~~
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
}1)最先处理注册@Import进来的Bean定义,判断依据是:configClass.isImported()。官方解释为:
Return whether this configuration class was registered via @{@link Import} or automatically registered due to being nested within another configuration class
这句话的意思是说@Import或者内部类或者通过别的配置类放进来的都是被导入进来的。
2)第二步开始注册@Bean进来的:若是static方法,beanDef.setBeanClassName(configClass.getMetadata().getClassName()) + beanDef.setFactoryMethodName(methodName);若是实例方法:beanDef.setFactoryBeanName(configClass.getBeanName())+ beanDef.setUniqueFactoryMethodName(methodName) 总之对使用者来说 没有太大的区别
3)注册importedResources进来的bean。就是@ImportResource这里来的Bean定义
4)执行ImportBeanDefinitionRegistrar#registerBeanDefinitions()注册Bean定义信息~(也就是此处执行ImportBeanDefinitionRegistrar的接口方法)
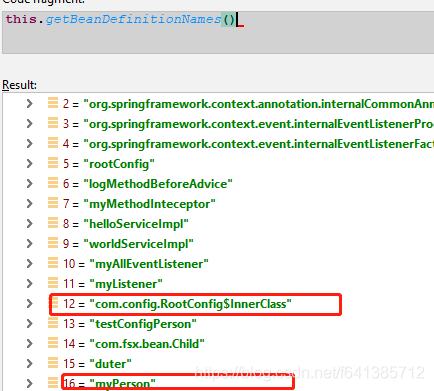
this.reader.loadBeanDefinitions(configClasses)执行完成后,拥有的bean定义截图如下:(导入的最终也都作为独立的Bean注册进来了~)
postProcessBeanDefinitionRegistry()处理过程总结
- 使用工具ConfigurationClassParser尝试发现所有的配置(@Configuration)类
- 使用工具ConfigurationClassBeanDefinitionReader注册所发现的配置类中所有的bean定义
- 结束执行的条件是所有配置类都被发现和处理,相应的bean定义注册到容器(内部有递归)
ConfigurationClassPostProcessor#postProcessBeanFactory处理逻辑
这里就是增强配置类,添加一个ImportAwareBeanPostProcessor,这个类用来处理 ImportAware 接口实现
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
int factoryId = System.identityHashCode(beanFactory);
if (this.factoriesPostProcessed.contains(factoryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + beanFactory);
}
this.factoriesPostProcessed.add(factoryId);\
// 这一步的意思是:如果processConfigBeanDefinitions没被执行过(不支持hook的时候不会执行)
// 这里会补充去执行processConfigBeanDefinitions这个方法
if (!this.registriesPostProcessed.contains(factoryId)) {
// BeanDefinitionRegistryPostProcessor hook apparently not supported...
// Simply call processConfigurationClasses lazily at this point then.
processConfigBeanDefinitions((BeanDefinitionRegistry) beanFactory);
}
// 这个是核心方法~~~~~~~~~~~~~~
enhanceConfigurationClasses(beanFactory);
// 添加一个后置处理器。ImportAwareBeanPostProcessor它是一个静态内部类
// 记住:它实现了SmartInstantiationAwareBeanPostProcessor这个接口就可以了。后面会有作用的
//InstantiationAwareBeanPostProcessor是BeanPostProcessor的子接口,可以在Bean生命周期的另外两个时期提供扩展的回调接口
//即实例化Bean之前(调用postProcessBeforeInstantiation方法)和实例化Bean之后(调用postProcessAfterInstantiation方法)
beanFactory.addBeanPostProcessor(new ImportAwareBeanPostProcessor(beanFactory));
}enhanceConfigurationClasses如下:
public void enhanceConfigurationClasses(ConfigurableListableBeanFactory beanFactory) {
Map<String, AbstractBeanDefinition> configBeanDefs = new LinkedHashMap<>();
// 拿到所有的Bean名称,当前环境一共9个(6个基础Bean+rootConfig+helloServiceImpl+parent视图类)
for (String beanName : beanFactory.getBeanDefinitionNames()) {
BeanDefinition beanDef = beanFactory.getBeanDefinition(beanName);
// 显然,能进来这个条件的,就只剩rootConfig这个类定义了
// 从此处也可以看出,如果是lite版的@Configuration,是不会增强的
if (ConfigurationClassUtils.isFullConfigurationClass(beanDef)) {
if (!(beanDef instanceof AbstractBeanDefinition)) {
throw new BeanDefinitionStoreException("Cannot enhance @Configuration bean definition '" +
beanName + "' since it is not stored in an AbstractBeanDefinition subclass");
}
else if (logger.isWarnEnabled() && beanFactory.containsSingleton(beanName)) {
logger.warn("Cannot enhance @Configuration bean definition '" + beanName +
"' since its singleton instance has been created too early. The typical cause " +
"is a non-static @Bean method with a BeanDefinitionRegistryPostProcessor " +
"return type: Consider declaring such methods as 'static'.");
}
configBeanDefs.put(beanName, (AbstractBeanDefinition) beanDef);
}
}
// 装载着等待被加强的一些配置类们
if (configBeanDefs.isEmpty()) {
// nothing to enhance -> return immediately
return;
}
ConfigurationClassEnhancer enhancer = new ConfigurationClassEnhancer();
for (Map.Entry<String, AbstractBeanDefinition> entry : configBeanDefs.entrySet()) {
AbstractBeanDefinition beanDef = entry.getValue();
// If a @Configuration class gets proxied, always proxy the target class
beanDef.setAttribute(AutoProxyUtils.PRESERVE_TARGET_CLASS_ATTRIBUTE, Boolean.TRUE);
try {
// Set enhanced subclass of the user-specified bean class
// 拿到原始的rootConfig类
Class<?> configClass = beanDef.resolveBeanClass(this.beanClassLoader);
if (configClass != null) {
// 对此类进行cglib增强
// 注意增强后的类为:class com.fsx.config.RootConfig$$EnhancerBySpringCGLIB$$13993c97
Class<?> enhancedClass = enhancer.enhance(configClass, this.beanClassLoader);
if (configClass != enhancedClass) {
if (logger.isDebugEnabled()) {
logger.debug(String.format("Replacing bean definition '%s' existing class '%s' with " +
"enhanced class '%s'", entry.getKey(), configClass.getName(), enhancedClass.getName()));
}
// 把增强后的类配置类set进去。
// 所以我们getBean()配置类,拿出来的是配置类的代理对象 是被CGLIB代理过的
beanDef.setBeanClass(enhancedClass);
}
}
} catch (Throwable ex) {
throw new IllegalStateException("Cannot load configuration class: " + beanDef.getBeanClassName(), ex);
}
}
}可能有人会问,Spring为何要用cglib增强配置文件@Configuration呢?
其实上面提到的Full和Lite的区别已经知道答案了:
我们通过源码发现:只有full模式的才会去增强,然后增强带来的好处是:Spring可以更好的管理Bean的依赖关系了。比如@Bean之间方法之间的调用,我们发现,其实是去Spring容器里去找Bean了,而并不是再生成了一个实例。(它的缺点是使用了代理,带来的性能影响完全可以忽略)
其实这些可以通过我们自己书写代码来避免,但是Spring为了让它的自动化识别来得更加强大,所以采用代理技术来接管这些配置Bean的依赖,可谓对开发者十分的友好。
上面源码也指出了:Liter模式是不会采用代理的,因此它的Bean依赖关系程序员自己去把控吧。建议:不要使用Lite模式,会带来不少莫名其妙的坑。
@Configuration注解的配置类有如下要求
- @Configuration不可以是final类型
- @Configuration不可以是匿名类
- 嵌套的@Configuration必须是静态类
ConfigurationClassBeanDefinitionReader使用详解
功能:读取一组已经被完整解析的配置类ConfigurationClass,基于它们所携带的信息向给定bean容器BeanDefinitionRegistry注册其中所有的bean定义。
该工具由BeanDefinitionRegistryPostProcessor来使用。Spring中的责任分工是非常明确的:
- ConfigurationClassParser负责去找到所有的配置类。(包括做加强操作)
- 然后交给ConfigurationClassBeanDefinitionReader将这些配置类中的bean定义注册到容器
该类只提供了一个public方法供外面调用:这个方法是根据传的配置们,去解析每个配置文件所标注的@Bean们,其余细节~
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
//TrackedConditionEvaluator是个内部类:是去解析@Conditional相关注解的。借助了conditionEvaluator去计算处理 主要是看看要不要shouldSkip()
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
// 遍历处理参数configurationModel中的每个配置类
// 这里需要特别注意的是,此环境下,这里size不是1,而是2(rootConfig和helloServiceImpl)
// 因为对于parser来说,只要是@Component都是一个组件(配置文件),只是是Lite模式而已
// 因此我们也是可以在任意一个@Component标注的类上使用@Bean向里面注册Bean的,相当于采用的Lite模式。只是,只是我们一般不会去这么干而已,毕竟要职责单一
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
//从指定的一个配置类ConfigurationClass中提取bean定义信息并注册bean定义到bean容器 :
//1. 配置类本身要注册为bean定义 2. 配置类中的@Bean注解方法要注册为配置类
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
// 判断是否需要跳过,与之前解析@Configuration判断是否跳过的逻辑是相同的 借助了conditionEvaluator。如果需要
// 显然这里,哪怕是helloServiceImpl都不会被跳过
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
// 如果这个类是@Import进来的 那就注册为一个BeanDefinition 比如这种@Import(Child.class) 这里就会是true
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
// 这里处理的是所有标注有@Bean注解的方法们,然后注册成BeanDefinition
// 同时会解析一些列的@Bean内的属性,以及可以标注的其余注解
// 备注:方法访问权限无所谓,private都行。然后static的也行
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
//加载@ImportResource注解配置的资源需要生成的BeanDefinition
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
// 调用自定义的ImportBeanDefinitionRegistrar的registerBeanDefinitions方法注册BeanDefinition
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}就这样通过这个Reader,把所有的Bean定义都加进容器了,后面就可以很方便的获取到了。
ConfigurationClassParser 总结
Spring的工具类ConfigurationClassParser用于分析@Configuration注解的配置类,产生一组ConfigurationClass对象。
分析过程主要是递归分析配置类的注解@Import(比如我们的@EnableWebMvc注解,就@Import(DelegatingWebMvcConfiguration.class),然后它就是一个@Configuration),配置类内部嵌套类,找出其中所有的配置类,然后返回这组配置类
该工具主要由ConfigurationClassPostProcessor使用,而ConfigurationClassPostProcessor是一个BeanDefinitionRegistryPostProcessor/BeanFactoryPostProcessor,它会在容器启动过程中,应用上下文上执行各个BeanFactoryPostProcessor时被执行。
ConfigurationClassParser 所在包 : org.springframework.context.annotation。由此可知,Spring给这个处理器的定位,就是去处理解析相关注解的。
getImports、collectImports
这里面特别的说一下比较有意思的getImports()(collectImports):这个方法目的是递归去搜集到所有的@Import注解
private Set<SourceClass> getImports(SourceClass sourceClass) throws IOException {
// 装载所有的搜集到的import
Set<SourceClass> imports = new LinkedHashSet<>();
// 这个集合很有意思:就是去看看所有的内嵌类、以及注解是否有@Import注解
// 比如看下面这个截图,会把所有的注解都给翻出来,哪怕是注解的注解
Set<SourceClass> visited = new LinkedHashSet<>();
collectImports(sourceClass, imports, visited);
return imports;
}
private void collectImports(SourceClass sourceClass, Set<SourceClass> imports, Set<SourceClass> visited)
throws IOException {
// 此处什么时候返回true,什么时候返回false,请操作HashMap的put方法的返回值,看什么时候返回null
// 答案:put一个新key,返回null。put一个已经存在的key,返回老的value值
// 因此此处把add放在if条件里,是比较有技巧性的(若放置的是新的,返回null,若已经存在,就返回的false,不需要用contains()进一步判断了)
if (visited.add(sourceClass)) {
for (SourceClass annotation : sourceClass.getAnnotations()) {
String annName = annotation.getMetadata().getClassName();
// 此处不能以java打头,是为了过滤源注解:比如java.lang.annotation.Target这种
// 并且这个注解如果已经是Import注解了,那也就停止递归了
if (!annName.startsWith("java") && !annName.equals(Import.class.getName())) {
collectImports(annotation, imports, visited);
}
}
imports.addAll(sourceClass.getAnnotationAttributes(Import.class.getName(), "value"));
}
}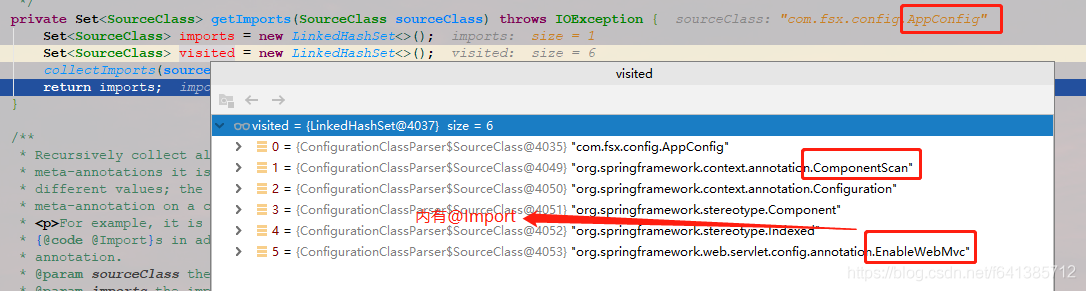

我们可以看到在解析到@EnableWebMvc的时候,拿到了它的@Import,拿到DelegatingWebMvcConfiguration,但是我们发现它也还是个@Configuration
@Configuration
public class DelegatingWebMvcConfiguration extends WebMvcConfigurationSupport { ... }需要注意的是:它的父类WebMvcConfigurationSupport,里面有非常多的@Bean注解的方法,比如RequestMappingHandlerMapping、BeanNameUrlHandlerMapping等等共18个类都会被注册到容器里(Spring非常强大,配置文件都会解析父类的@Bean标签),理解了这里,到时候后面讲解为何SpringBoot环境下,若我们写了@EnableWebMvc这个注解,就脱离Spring的管理了就非常好理解其中的原因了~~~~~~~~~~~~~~
然后把这些@Import交给processImports()去处理。进而又会递归式的处理@Configuration文件一样进行处理(内部也就可以写@Bean之类隐式的给容器注册Bean)。
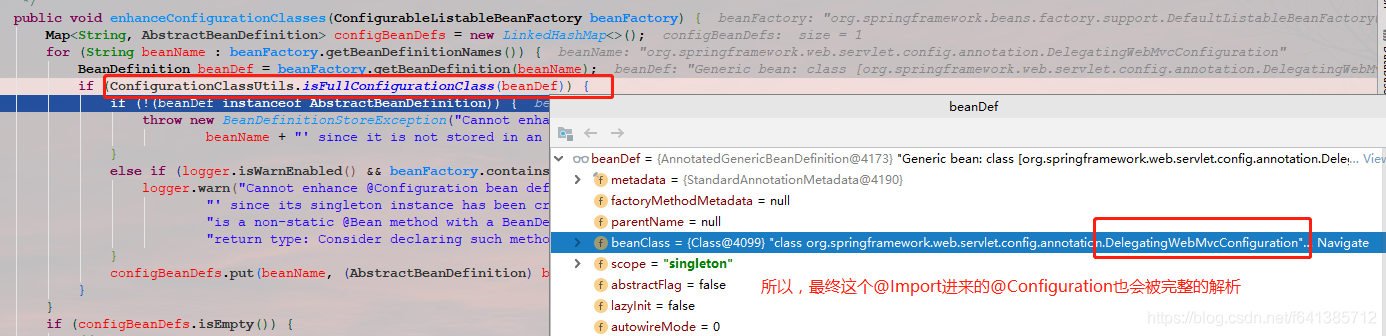
总结
Spring设计了很多的后置处理器,让调用者可以在Bean定义时、Bean生成前后等等时机参与进来。而我们此处的ConfigurationClassPostProcessor就是Spring自己为我们实现的,来解析@Confiuration以及相关配置注解的处理器。
了解了此处理器的解析过程,在我们自己去处理配置文件的时候,也能够更加的得心应手。比如知其然,知其所以然后,我们就能更加熟练的运用@Import这种高级注解实现特定的设计模式。这些在Spring Boot的整体框架设计中,得到了大量的运用。
|
参考: |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现