谈谈MySQL 索引,B+树原理,以及建索引的几大原则
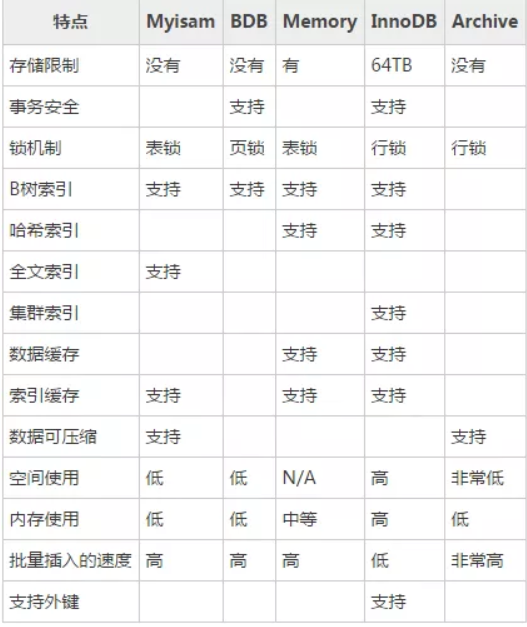
存储引擎的比较
注:上面提到的B树索引并没有指出是B-Tree和B+Tree索引,但是B-树和B+树的定义是有区别的。
在 MySQL 中,主要有四种类型的索引,分别为:B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。
当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面除了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM)
B-树、B+树概念
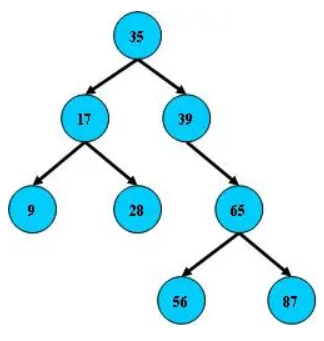
B树
即二叉搜索树:
- 所有非叶子结点至多拥有两个儿子(Left和Right);
- 所有结点存储一个关键字;
- 非叶子结点的左指针指向小于其关键字的子树,右指针指向大于其关键字的子树;
B-树
是一种多路搜索树(并不是二叉的):
- 定义任意非叶子结点最多只有M个儿子;且M>2;
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];
- 每个结点存放至少M/2-1(取上整)和至多M-1个关键字;(至少2个关键字)
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];其中P[1]指向关键字小于K[1]的子树,P[M]指向关键字大于K[M-1]的子树,其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层;
如:(M=3)
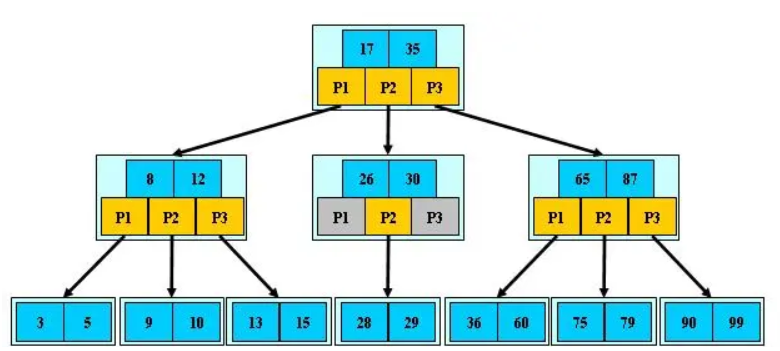
B-树的搜索,从根结点开始,对结点内的关键字(有序)序列进行二分查找,如果命中则结束,否则进入查询关键字所属范围的儿子结点;重复,直到所对应的儿子指针为空,或已经是叶子结点;
B-树的特性:
- 关键字集合分布在整棵树中;
- 任何一个关键字出现且只出现在一个结点中;
- 搜索有可能在非叶子结点结束;
- 其搜索性能等价于在关键字全集内做一次二分查找;
- 自动层次控制;
由于限制了除根结点以外的非叶子结点,至少含有M/2个儿子,确保了结点的至少利用率。
所以B-树的性能总是等价于二分查找(与M值无关),也就没有B树平衡的问题;
由于M/2的限制,在插入结点时,如果结点已满,需要将结点分裂为两个各占M/2的结点;删除结点时,需将两个不足M/2的兄弟结点合并;
B+树
B+树是B-树的变体,也是一种多路搜索树:
其定义基本与B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
如:(M=3)
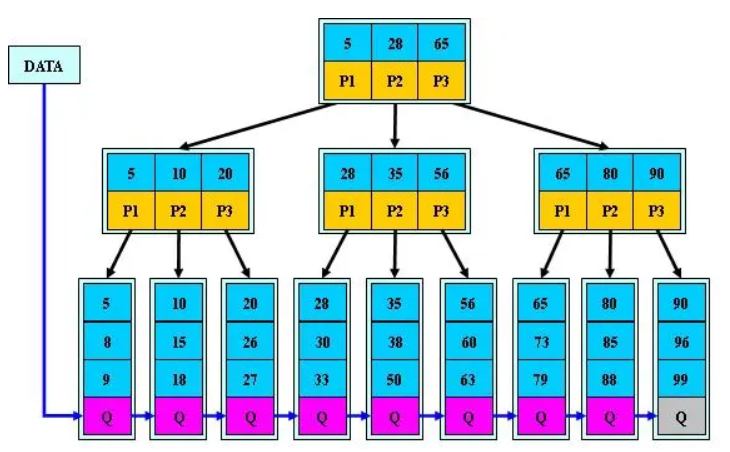
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找;
B+的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
建索引的几大原则
1、最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2、=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式。
3、尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。
4、索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = '2014-05-29'就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp('2014-05-29');
5、尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类