你知道Redis的字符串是怎么实现的吗?
Redis字符串的实现
Redis虽然是用C语言写的,但却没有直接用C语言的字符串,而是自己实现了一套字符串。目的就是为了提升速度,提升性能,可以看出Redis为了高性能也是煞费苦心。
Redis构建了一个叫做简单动态字符串(Simple Dynamic String),简称SDS。
SDS 代码结构
struct sdshdr{
// 记录已使用长度
int len;
// 记录空闲未使用的长度
int free;
// 字符数组
char[] buf;
};SDS ?下面画个图来说明,一目了然。
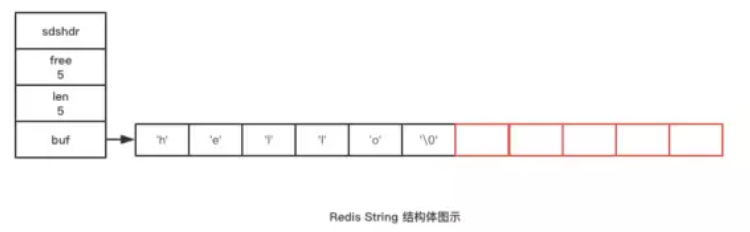
Redis的字符串也会遵守C语言的字符串的实现规则,即最后一个字符为空字符。然而这个空字符不会被计算在len里头。
SDS 动态扩展特点
SDS的最厉害最奇妙之处在于它的Dynamic。动态变化长度。举个例子:
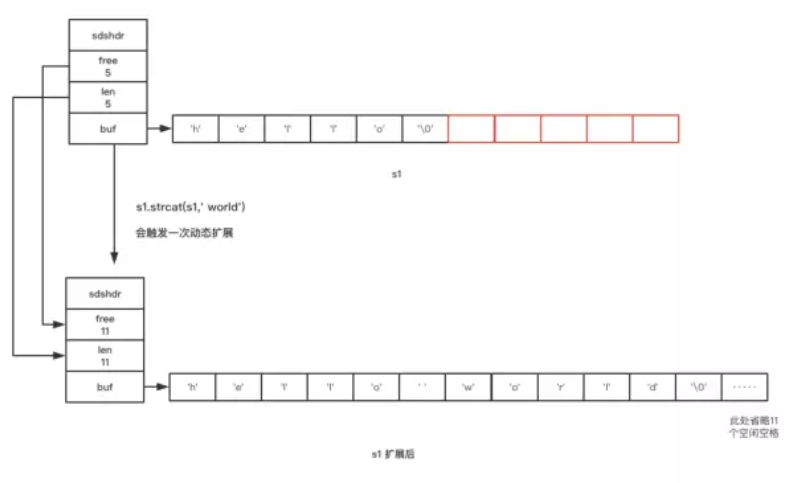
如上图所示刚开始s1 只有5个空闲位子,后面需要追加' world' 6个字符,很明显是不够的。那咋办?Redis会做以下三个操作:
- 计算出大小是否足够
- 开辟空间至满足所需大小
- 开辟与已使用大小len相同长度的空闲free空间(如果len < 1M)开辟1M长度的空闲free空间(如果len >= 1M)
看到这儿为止有没有朋友觉得这个实现跟Java的列表List实现有点类似呢?看完后面的会觉得更像了。
Redis字符串的性能优势
- 快速获取字符串长度
- 避免缓冲区溢出
- 降低空间分配次数提升内存使用效率
快速获取字符串长度
再看下上面的SDS结构体:
struct sdshdr{
// 记录已使用长度
int len;
// 记录空闲未使用的长度
int free;
// 字符数组
char[] buf;
};由于在SDS里存了已使用字符长度len,所以当想获取字符串长度时直接返回len即可,时间复杂度为O(1)。如果使用C语言的字符串的话它的字符串长度获取函数时间复杂度为O(n),n为字符个数,因为它是从头到尾(到空字符'\0')遍历相加。
避免缓冲区溢出
对一个C语言字符串进行strcat追加字符串的时候需要提前开辟需要的空间,如果不开辟空间的话可能会造成缓冲区溢出,而影响程序其他代码。如下图,有一个字符串s1="hello" 和 字符串s2="baby",现在要执行strcat(s1,"world"),并且执行前未给s1开辟空间,所以造成了缓冲区溢出。
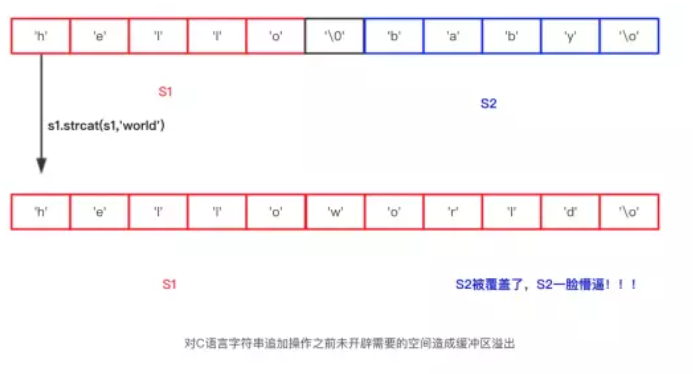
而对于Redis而言由于每次追加字符串时都会检查空间是否够用,所以不会存在缓冲区溢出问题。每次追加操作前都会做如下操作:
- 计算出大小是否足够
- 开辟空间至满足所需大小
降低空间分配次数提升内存使用效率
字符串的追加操作会涉及到内存分配问题,然而内存分配问题会牵扯内存划分算法以及系统调用所以如果频繁发生的话影响性能,所以对于性能至上的Redis来说这是万万不能忍受的。所以采取了以下两种优化措施
- 空间与分配
- 惰性空间回收
空间预分配
- 对于追加操作来说,Redis不仅会开辟空间至够用而且还会预分配未使用的空间(free)来用于下一次操作。至于未使用的空间(free)的大小则由修改后的字符串长度决定。
- 当修改后的字符串长度len < 1M,则会分配与len相同长度的未使用的空间(free)
- 当修改后的字符串长度len >= 1M,则会分配1M长度的未使用的空间(free)
- 有了这个预分配策略之后会减少内存分配次数,因为分配之前会检查已有的free空间是否够,如果够则不开辟了。
惰性空间回收
与上面情况相反,惰性空间回收适用于字符串缩减操作。比如有个字符串s1="hello world",对s1进行sdstrim(s1," world")操作,执行完该操作之后Redis不会立即回收减少的部分,而是会分配给下一个需要内存的程序。当然,Redis也提供了回收内存的api,可以自己手动调用来回收缩减部分的内存。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类