【大道Spring】Spring整合组件_Sharding-JDBC
Sharding-JDBC分库分表技术框架(这一点与MyCat不同,MyCat本质上是一种数据库代理)。Sharding-JDBC定位为轻量级数据库驱动,由客户端直连数据库,以jar包形式提供服务,未使用中间层,无需额外部署,无其他依赖,业务系统开发人员与数据库运维人员无需改变原有的开发与运维方式。因此Sharding-JDBC即为增强版的JDBC驱动,可以实现旧代码迁移零成本的目标。 目前社区较为活跃。目前已广泛应用于现各大互联网公司。
Sharding-JDBC可以通过Java,YAML,Spring命名空间和Spring Boot Starter四种方式配置,开发者可根据场景选择适合的配置方式。
本文以Java配置为例进行说明。核心内容有:
- 数据分片
- 读写分离
- 强制路由
- 编排治理
- 分布式事务
- 数据脱敏
官网:https://shardingsphere.apache.org/index_zh.html
快速入门
1、pom依赖

<!--mysql驱动包--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.35</version> </dependency> <!-- HikariCP --> <dependency> <groupId>com.zaxxer</groupId> <artifactId>HikariCP</artifactId> <version>3.4.5</version> </dependency> <!-- sharding-jdbc-core --> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-core</artifactId> <version>4.1.1</version> </dependency>
2、Sharding-Jdbc配置
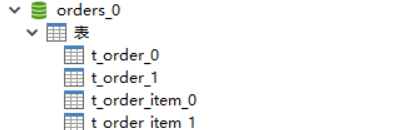
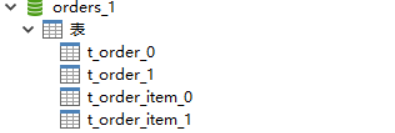
import org.apache.shardingsphere.api.config.sharding.KeyGeneratorConfiguration; import org.apache.shardingsphere.api.config.sharding.ShardingRuleConfiguration; import org.apache.shardingsphere.api.config.sharding.TableRuleConfiguration; import org.apache.shardingsphere.api.config.sharding.strategy.InlineShardingStrategyConfiguration; import org.apache.shardingsphere.api.config.sharding.strategy.StandardShardingStrategyConfiguration; import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm; import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue; import org.apache.shardingsphere.shardingjdbc.api.ShardingDataSourceFactory; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; import javax.sql.DataSource; import java.sql.SQLException; import java.util.Collection; import java.util.HashMap; import java.util.Map; import java.util.Properties; @Configuration public class ShardingDBConfig { @Bean public DataSource shardingDataSource() throws SQLException { ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getTableRuleConfigs().add(getOrderTableRuleConfiguration()); shardingRuleConfig.getTableRuleConfigs().add(getOrderItemTableRuleConfiguration()); shardingRuleConfig.getBindingTableGroups().add("t_order, t_order_item"); //采用user_id进行分库 shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "orders_${user_id % 2}")); //采用order_id进行分表 shardingRuleConfig.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("order_id", new PreciseShardingAlgorithm<Long>() { @Override public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) { for (String each : collection) { System.out.println("each:" + each + ", shardingValue:" + preciseShardingValue.getValue()); if (each.endsWith(preciseShardingValue.getValue() % 2 + "")) { return each; } } throw new UnsupportedOperationException(); } })); //获取数据源对象 Properties properties = new Properties(); properties.setProperty("sql.show", "true"); return ShardingDataSourceFactory.createDataSource(createDataSourceMap(), shardingRuleConfig, properties); } private KeyGeneratorConfiguration getKeyGeneratorConfiguration() { //主键的生成策略 KeyGeneratorConfiguration keyGeneratorConfiguration = new KeyGeneratorConfiguration("SNOWFLAKE", "order_id"); return keyGeneratorConfiguration; } private TableRuleConfiguration getOrderTableRuleConfiguration() { //逻辑表和真实表(物理表) TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_order", "orders_${0..1}.t_order_${0..1}"); orderTableRuleConfig.setKeyGeneratorConfig(getKeyGeneratorConfiguration()); return orderTableRuleConfig; } private TableRuleConfiguration getOrderItemTableRuleConfiguration() { //逻辑表和真实表(物理表) TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration("t_order_item", "orders_${0..1}.t_order_item_${0..1}"); return orderItemTableRuleConfig; } private Map<String, DataSource> createDataSourceMap() { Map<String, DataSource> result = new HashMap<>(); result.put("orders_0", DataSourceUtil.createDataSource("orders_0")); result.put("orders_1", DataSourceUtil.createDataSource("orders_1")); return result; } }
数据库操作类
import com.zaxxer.hikari.HikariDataSource; import javax.sql.DataSource; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; public final class DataSourceUtil { private static final String HOST = "localhost"; private static final int PORT = 3306; private static final String USER_NAME = "root"; private static final String PASSWORD = "root"; public static DataSource createDataSource(final String dataSourceName) { HikariDataSource dataSource = new HikariDataSource(); dataSource.setDriverClassName(com.mysql.jdbc.Driver.class.getName()); dataSource.setJdbcUrl(String.format("jdbc:mysql://%s:%s/%s?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8", HOST, PORT, dataSourceName)); dataSource.setUsername(USER_NAME); dataSource.setPassword(PASSWORD); dataSource.setConnectionTimeout(30000L); //用于测试,这里的数量要大点 dataSource.setMaximumPoolSize(50); dataSource.setPoolName("hikariPool"); dataSource.setMaxLifetime(1800000L); return dataSource; } public static void createTable(DataSource dataSource) throws SQLException { execute(dataSource, "create table if not exists t_order(order_id bigint AUTO_INCREMENT, user_id int not null, status varchar(10), primary key (order_id))"); execute(dataSource, "create table if not exists t_order_item(order_item_id bigint AUTO_INCREMENT, order_id bigint, user_id int not null, primary key (order_item_id))"); } public static void dropTable(DataSource dataSource) throws SQLException { execute(dataSource, "drop table if exists t_order"); execute(dataSource, "drop table if exists t_order_item"); } public static void insertData(DataSource dataSource) throws SQLException { for (int i = 1; i < 10; i++) { long orderId = executeAndGetGenerateKey(dataSource, "insert into t_order(user_id, status) values(10, 'INIT')"); execute(dataSource, String.format("insert into t_order_item(order_id, user_id) values(%d, 10)", orderId)); orderId = executeAndGetGenerateKey(dataSource, "insert into t_order(user_id, status) value(11, 'INIT')"); execute(dataSource, String.format("insert into t_order_item(order_id, user_id) values(%d, 11)", orderId)); } } public static void select(DataSource dataSource,String sql) throws SQLException { executeQuery(dataSource,sql); } private static void execute(DataSource dataSource, String sql) throws SQLException { Connection conn = dataSource.getConnection(); PreparedStatement pst = conn.prepareStatement(sql); pst.execute(); } private static void executeQuery(DataSource dataSource, String sql) throws SQLException { Connection conn = dataSource.getConnection(); PreparedStatement pst = conn.prepareStatement(sql); ResultSet rs = pst.executeQuery(); Long orderId = null; Long userId = null; String status = null; while (rs.next()) { orderId = rs.getLong("order_id"); userId = rs.getLong("user_id"); status = rs.getString("status"); System.out.println(String.format("data: orderId=%s, userId=%s, status=%s", orderId, userId, status)); } } private static long executeAndGetGenerateKey(DataSource dataSource, String sql) throws SQLException { Connection conn = dataSource.getConnection(); Statement statement = conn.createStatement(); statement.executeUpdate(sql, Statement.RETURN_GENERATED_KEYS); ResultSet rs = statement.getGeneratedKeys(); rs.next(); return rs.getLong("order_id"); } }
3、测试
@RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration(classes = {RootConfig.class, WebConfig.class}) @WebAppConfiguration public class ShardingDbTest { @Resource(name = "shardingDataSource") private DataSource dataSource; @Test public void test() throws SQLException { DataSourceUtil.dropTable(dataSource); DataSourceUtil.createTable(dataSource); DataSourceUtil.insertData(dataSource); } }
Groovy语法入门
教程:https://www.w3cschool.cn/groovy/
Groovy是一种基于JVM(Java虚拟机)的敏捷开发语言,它结合了Python、Ruby和Smalltalk的许多强大的特性,Groovy 代码能够与 Java 代码很好地结合,也能用于扩展现有代码。由于其运行在 JVM 上的特性,Groovy 可以使用其他 Java 语言编写的库。
orders_${0..1},等同于orders_$->{0..1},我们可以简单理解为orders_$中$是一个占位符,指向{0..1}表达式的值。
1、Groovy 范围
- 1..10 - 包含范围的示例
- 1 .. <10 - 独占范围的示例
- 'a'..'x' - 范围也可以由字符组成
- 10..1 - 范围也可以按降序排列
- 'x'..'a' - 范围也可以由字符组成并按降序排列。
2、Groovy 列表
groovy 列表使用索引操作符 [] 索引。列表索引从 0 开始,指第一个元素。
groovy 中的一个列表中的数据可以是任意类型。
groovy 列表可以嵌套列表。如 [1,2,[3,4,5],“aaa”] 。
空列表表示为 [] 声明一个空集合。
3、Groovy 映射
映射(也称为关联数组,字典,表和散列)是对象引用的无序集合。Map集合中的元素由键值访问。 Map中使用的键可以是任何类。当我们插入到Map集合中时,需要两个值:键和值。
['TopicName':'Lists','TopicName':'Maps'] - 具有TopicName作为键的键值对的集合及其相应的值。
[:] - 空映射。
4、字符串
Groovy中的字符串允许使用双引号和单引号。
当使用双引号时,可以在字符串内嵌入一些运算式,Groovy允许您使用 与 bash 类似的 ${expression} 语法进行替换。可以在字符串中包含任意的Groovy表达式。
当使用双引号时,可以在字符串内嵌入一些运算式,Groovy允许您使用 与 bash 类似的 ${expression} 语法进行替换。可以在字符串中包含任意的Groovy表达式。
name="James" println "My name is ${name},'00${6+1}'" //prints My name is James,'007'
Groovy还支持"uXXXX" 引用(其中X是16进制数),用来表示特殊字符,例如 "u0040" 与"@"字符相同。
数据分片
背景
传统的将数据集中存储至单一数据节点的解决方案,在性能、可用性和运维成本这三方面已经难于满足互联网的海量数据场景。
- 性能方面:由于关系型数据库大多采用B+树类型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查询性能的下降;同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。
- 可用性方面:服务化的无状态型,能够达到较小成本的随意扩容,这必然导致系统的最终压力都落在数据库之上。而单一的数据节点,或者简单的主从架构,已经越来越难以承担。数据库的可用性,已成为整个系统的关键。
- 运维成本方面:当一个数据库实例中的数据达到阈值以上,对于DBA的运维压力就会增大。数据备份和恢复的时间成本都将随着数据量的大小而愈发不可控。一般来讲,单一数据库实例的数据的阈值在1TB之内,是比较合理的范围。
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。分库和分表均可以有效的避免由数据量超过可承受阈值而产生的查询瓶颈。 除此之外,分库还能够用于有效的分散对数据库单点的访问量;分表虽然无法缓解数据库压力,但却能够提供尽量将分布式事务转化为本地事务的可能,一旦涉及到跨库的更新操作,分布式事务往往会使问题变得复杂。 使用多主多从的分片方式,可以有效的避免数据单点,从而提升数据架构的可用性。
通过分库和分表进行数据的拆分来使得各个表的数据量保持在阈值以下,以及对流量进行疏导应对高访问量,是应对高并发和海量数据系统的有效手段。 数据分片的拆分方式又分为垂直分片和水平分片。
1、垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
2、水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表)。
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
3、面临的挑战
虽然数据分片解决了性能、可用性以及单点备份恢复等问题,但分布式的架构在获得了收益的同时,也引入了新的问题。
- 分库分表之后的数据变的散乱,开发人员对数据库的操作变得异常繁重。
- 能够正确的运行在单节点数据库中的SQL,在分片之后的数据库中并不一定能够正确运行。例如,分表导致表名称的修改,或者分页、排序、聚合分组等操作的不正确处理。
- 跨库事务也是分布式的数据库集群要面对的棘手事情。 合理采用分表,可以在降低单表数据量的情况下,尽量使用本地事务,善于使用同库不同表可有效避免分布式事务带来的麻烦。 在不能避免跨库事务的场景,有些业务仍然需要保持事务的一致性。 而基于XA的分布式事务由于在并发度高的场景中性能无法满足需要,并未被互联网巨头大规模使用,他们大多采用最终一致性的柔性事务代替强一致事务。
尽量透明化分库分表所带来的影响,让使用方尽量像使用一个数据库一样使用水平分片之后的数据库集群。
核心概念
| 概念 | 描述 |
| 逻辑表 | 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:订单数据根据主键尾数拆分为10张表,分别是t_order_0到t_order_9,他们的逻辑表名为t_order。 |
| 真实表(物理表) | 在分片的数据库中真实存在的物理表。即上个示例中的t_order_0到t_order_9。 |
| 数据节点 | 数据分片的最小单元。由数据源名称和数据表组成,例:ds_0.t_order_0。 |
| 绑定表 | 指分片规则一致的主表和子表。例如:t_order表和t_order_item表,均按照order_id分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。 |
| 广播表 | 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。 |
分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订单主键为分片字段。 SQL中如果无分片字段,将执行全路由,性能较差。 除了对单分片字段的支持,ShardingSphere也支持根据多个字段进行分片。
分片算法
通过分片算法将数据分片,支持通过=、>=、<=、>、<、BETWEEN和IN分片。分片算法需要应用方开发者自行实现,可实现的灵活度非常高。
目前提供4种分片算法。由于分片算法和业务实现紧密相关,因此并未提供内置分片算法,而是通过分片策略将各种场景提炼出来,提供更高层级的抽象,并提供接口让应用开发者自行实现分片算法。
- 精确分片算法:对应PreciseShardingAlgorithm,用于处理使用单一键作为分片键的=与IN进行分片的场景。需要配合StandardShardingStrategy使用。
- 范围分片算法:对应RangeShardingAlgorithm,用于处理使用单一键作为分片键的BETWEEN AND、>、<、>=、<=进行分片的场景。需要配合StandardShardingStrategy使用。
- 复合分片算法:对应ComplexKeysShardingAlgorithm,用于处理使用多键作为分片键进行分片的场景,包含多个分片键的逻辑较复杂,需要应用开发者自行处理其中的复杂度。需要配合ComplexShardingStrategy使用。
- Hint分片算法:对应HintShardingAlgorithm,用于处理使用Hint行分片的场景。需要配合HintShardingStrategy使用。
分片策略


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现