Spring事务_数据库连接和Java线程的关系
前言
Spring作为Java框架王者,当前已经是基础容器框架的实际标准。Spring 除了提供了 IoC、AOP特性外,还有一个极其核心和重要的特性:数据库事务。事务管理涉及到的技术点比较多,想完全理解需要花费一定的时间,本系列将通过如下几个方面熟悉Spring的数据库事务:
- 数据库连接java.sql.Connection的特性、事务表示、以及和Java线程之间的天然关系;
- 数据库的隔离级别和传播机制;
- Spring基于事务和连接池的的抽象和设计
- Spring事务的实现原理
将深入数据库连接(java.sql.Connection对象)的特性,事务表示,以及和Java线程之间的天然关系。懂得了底层的基本原理,在这些基础的概念之上再来理解Spring 事务,就会容易很多。
Java事务控制的基本单位
在Java中,使用了java.sql.Connection实例来表示和数据库的一个连接,通信的方式目前基本上采用的是TCP/IP 连接方式。通过对Connection进行一系列的事务控制。
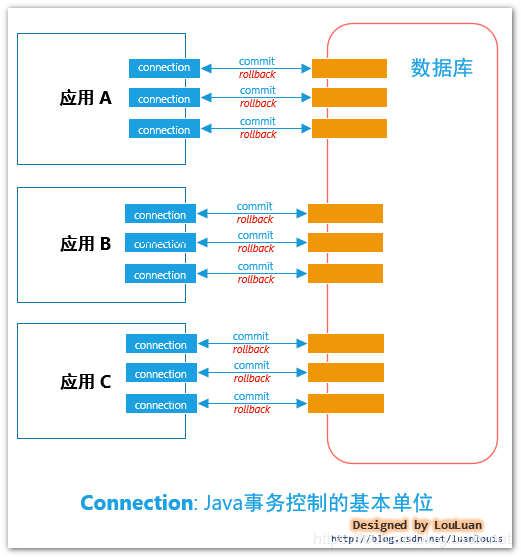
可能有人有如下的想法: 既然java.sql.Connection可以完成事务操作,那我在写代码的时候,直接创建一个然后使用不就行了? 然而在事实上,我们并不能这么做,这是因为,java.sql.Connection和数据库之间有非常紧密的关系,其数据库的资源是很有限的。
有限的系统资源java.sql.Connection
应用程序和数据库之间建立 Connection连接,则数据库机器会为之分配一定的线程资源来维护这种连接,连接数越多,消耗数据库的线程资源也就越多;另外不同的connection实例之间,可能会操作相同的表数据,也就是高并发,为了支持数据库对ACID特性的支持,数据库又会牺牲更多的资源。简单地来说,建立Connection连接,会消耗数据库系统的如下资源:
- 线程数:线程越多,线程的上下文切换会越频繁,会影响其处理能力;
- 创建Connection的开销:由于Connection负责和数据库之间的通信,在创建环节会做大量的初始化 ,创建过程所需时间和内存资源上都有一定的开销;
- 内存资源:为了维护Connection对象会消耗一定的内存;
- 锁占用:在高并发模式下,不同的Connection可能会操作相同的表数据,就会存在锁的情况,数据库为了维护这种锁会有不少的内存开销
上述的几种资源会限制数据库的链接数和处理性能。
结论: 数据库资源是比较宝贵的有限资源,当应用程序有数据库连接需求过大时,很容易会达到数据库的连接并发瓶颈。
数据库最多支持多少Connection连接
以 MySQL为例,可以通过如下语句查询数据库的最大支持情况:
-- 查看当前数据库最多支持多少数据库连接 show variables like '%max_connections%'; -- 设置当前运行时mysql的最大连接数,服务重启连接数将还原 set GLOBAL max_connections = 200; -- 修改 my.ini 或者my.cnf 配置文件 max_connections = 200;
数据库的连接数设置的越大越好吗? 肯定不是的,连接数越大,对使用大量的线程维护,伴随着大量的线程上下文切换,并且与此同时,连接数越多,表数据锁使用的概率会更大,反而会导致整体数据库的性能下降。具体的设置范围,应当具体的业务背景来调优。
java.sql.Connection对象本身的特性
1、线性操作和可以不限次数执行SQL事务操作
java.sql.Connection 本身有如下两个比较关键的特性:
- 线性操作:即在操作的时序上,事务和事务之间的执行是线性排开依次执行的
- 当建立了 java.sql.Connection 连接后,可以不限次数执行事务SQL请求。由于Connection对象的通信值基于TCP/IP协议的,当初始化后在手动关闭之前和数据库保持心跳存活连接,所以,可以使用Connection对象执行不限次数的SQL语句请求,包括事务请求 (注意: 这个看似比较简单的表述,在实际使用过程中非常重要,数据库连接池就是基于此特性建立的)。
如下图:
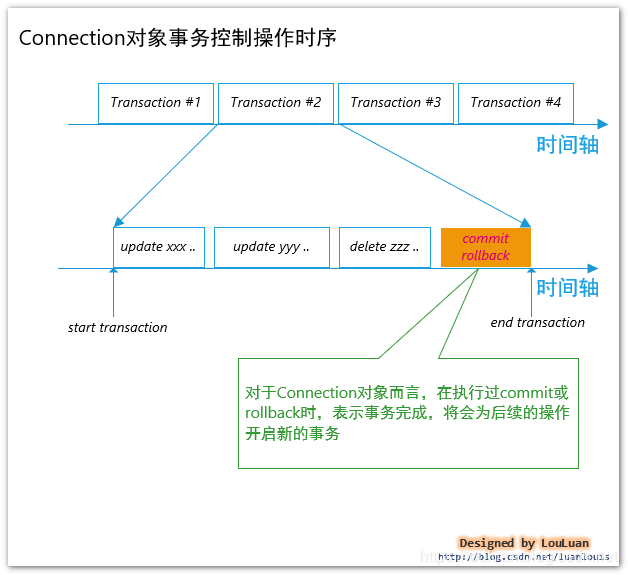
上图所示,对于java.sql.Connection对象的操作,一般会遵循序列化的事务操作模式,即:一个新事务的开启,必须在上一个事务完成之后(如果存在的话);换成另外一种表述方式就是:对connection的操作必须是线性的。
2、如何在Java中实现对java.sql.Connection对象的线性操作?
(1) 一个线程的整个生命周期中,可以独占一个java.sql.Connection 连接吗?
Java中,当然一个线程可以在整个生命周期独占一个java.sql.Connection,使用该对象完成各种数据库操作,因为一个线程内的所有操作都是同步的和线性的。然而,在实际的项目中,并不会这样做,原因有两个:
- Java中的线程数量可能远超数据库连接数量,会出现僧多粥少的情况。一个MySQL服务器的最大连接数量是有上限的,例子中提到的就是上限200;而在稍微大型一点的Java WEB项目中,光用户的HTTP请求线程数,就不止200个,这样就会出现部分线程无法获取到数据库连接,进而无法完成业务操作。
- Java线程在工作过程中,真正访问JDBC数据库连接所占用的时间比例很短。线程在接收到用户请求后,有很多业务逻辑需要处理:比如参数校验,权限验证,数值计算,然后持久化结果;其中可能只有持久化结果环节需要访问JDBC数据库连接,其余的时间范围内,JDBC数据库连接 都是空闲状态。换言之,如果线程整个生命周期中独占JDBC数据库连接,那么,真个连接池的空闲率很高,使用率很低。 综上所述,Java线程和JDBC数据库连接的关系如下:
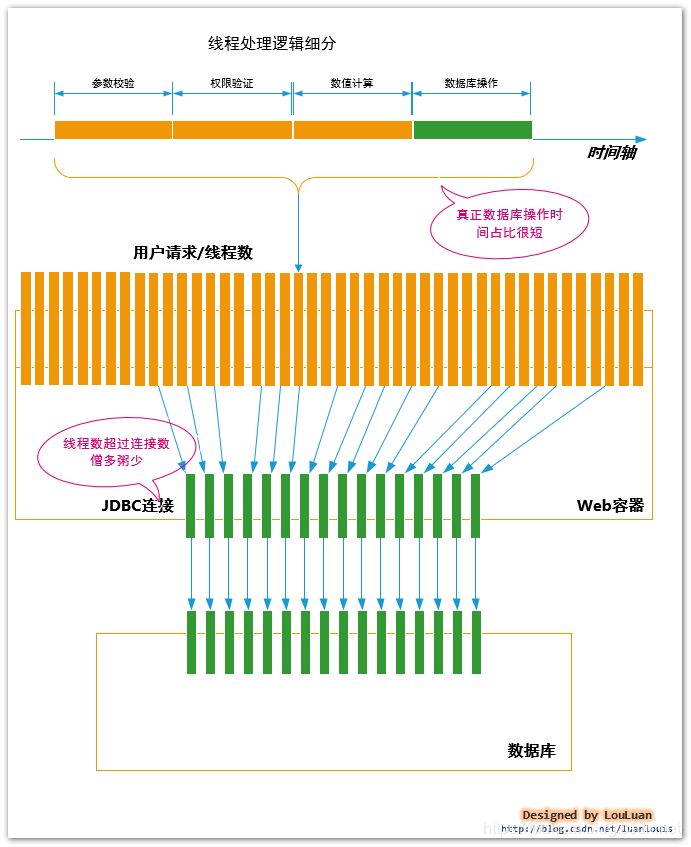
结论: 结合上述的两个症结,为了提高JDBC数据库连接的使用效率,目前普遍的解决方案是:当线程需要做数据库操作时,才会真正请求获取JDBC数据库连接,线程使用完了之后,立即释放,被释放的JDBC数据库连接等待下次分配使用。基于这个结论,会衍生两个问题需要解决:
- Java多线程访问同一个java.sql.Connection会有什么问题?如何解决?
- JDBC数据库连接如何管理和分配?(这个解决方案是:数据库连接池)
通过上述的图示中,可以看到,一个数据库连接对象在线程进行事务操作时,线程在此期间内是独占数据库连接对象的,也就是说,在事务进行期间,有一个非常重要的特性,就是:数据库连接对象可以吸附在线程上,我把这种特性称之为事务对象的线程吸附性 。正是由于这种特性,在Spring实现上,使用了基于线程的ThreadLocal来表示这种线程依附行为。
Java多线程访问同一个java.sql.Connection会有什么问题?Java多线程访问同一个java.sql.Connection会导致事务错乱。例如:现有线程thread #1 和线程thread #2,两个线程会有如下数据库操作:
thread #1: update xxx; update yyy; commit;
thread #2: delete zzz; insert ttt; rollback;
语句执行的序列在connection对象上,可能表现成了: delete zzz; update xxx; insert ttt; rollback; update yyy; commit;
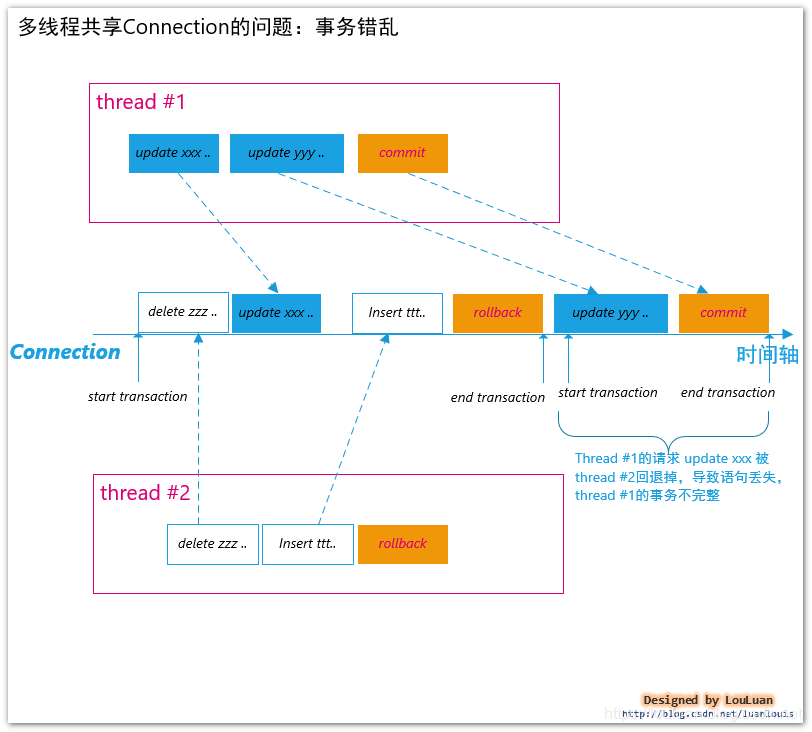
上图可以看到,Thread #1的请求 update xxx 被thread #2回退掉,导致语句丢失,thread #1的事务不完整。
(2) Java多线程访问同一个java.sql.Connection 的原则
解决上述事务不完整的问题,从本质上而言,就是多线程访互斥资源的方法。多线程互斥访问资源的方式在Java中的实现方式有很多,如下使用有一个最简单的使用 synchronized 关键字来实现 :

java.sql.Connection sharedConnection = <创建流程> ## thread #1 的业务伪代码: synchronized(sharedConnection){ `update xxx`; `update yyy`; `commit`; } ## thread #2 的业务伪代码: synchronized(sharedConnection){ `delete zzz`; `insert ttt`; `rollback`; }
上述的伪代码在执行上能够体现成如下的形式,即同一时间内,只有一个线程占用Connection对象。 假设Thread #2先获取到了Connection锁,如下图所示:
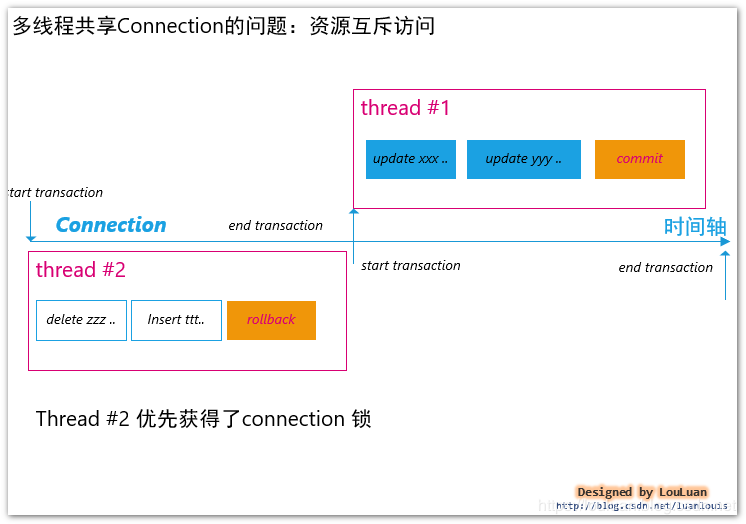
上述的流程还有有点问题:假如 thread #2 在执行语句 delete zzz,insert ttt,rollback 的过程中,在insert ttt之前有一段业务代码抛出了异常,导致语句只执行到了 delete zzz,这会导致在connection对象上有一个尚未提交的delete zzz请求; 当thread #1拿到了connection 对象的锁之后,接着执行 update xxx; update yyy; commit; 即:在两个线程执行完了之后,对connection的操作为delete zzz; update xxx; update yyy; commit; 示例如下:
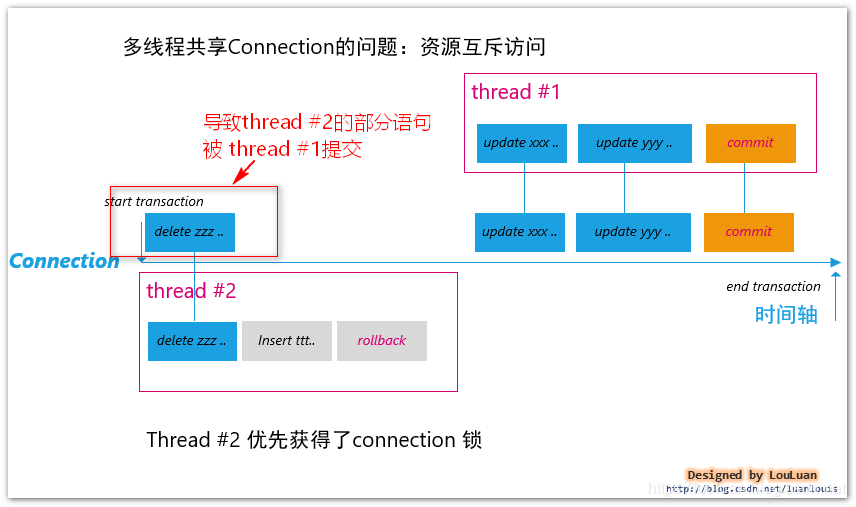
解决方案: 确保每个线程在使用Connection对象时,最终要明确对Connection做commit 或者rollback。 调整后的伪代码如下所示:
java.sql.Connection sharedConnection = <创建流程> ## thread #1 的业务伪代码: synchronized(sharedConnection){ try{ ` update xxx`; `update yyy`; `commit`; } catch(Exception e){ `rollback`; } } ## thread #2 的业务伪代码: synchronized(sharedConnection){ try{ `delete zzz`; `insert ttt`; `rollback`; } catch(Exception e){ `rollback`; } }
综上所述,解决多个线程访问同一个Connection对象时,必须遵循两个基本原则:
- 以资源互斥的方式访问Connection对象;
- 在线程执行结束时,应当最终及时提交(commit)或回滚(rollback)对Connection的影响;不允许存在尚未被提交或者回滚的语句。
java.sql.Connection实例在事务结束后有必要释放销毁吗?
正常情况下,我们在写业务代码时,会有类似的流程:
- 创建一个java.sql.Connection实例;
- 基于java.sql.Connection 做相关事务提交操作
- 销毁java.sql.Connection 实例
实际上,第三个步骤是完全没有必要销毁java.sql.Connection 实例的。我们已介绍Connection的性质:当建立了 java.sql.Connection 连接后,可以不限次数执行事务SQL请求, 也就是说,当此次事务结束后,我可以紧接着使用这个Connection对象开启下一个事务。 另外,由于创建一个java.sql.Connection实例的代价本身就比较大,笔者测试的数据库建立Connection的时间,一般都在至少0.1s级别,如果每一个事务在执行的时候,都要花费额外的0.1s 来做连接,会严重影响当前服务的性能和吞吐量。 结合上面的叙述,目前的做法,在完成事务后,并不会销毁java.sql.Connection实例,而是将其回收到连接池中。
java.sql.Connection数据库连接池

一般连接池需要如下几个功能:
- 管理一批Connection对象,一般会有连接数上限设置;
- 为每一个获取Connection请求做资源分配;如果资源不足,设置等待时间;
- 根据实际Connection的使用情况,为了提高系统之间的利用率,动态调整连接池中Connection对象的数量,如应用实际使用的连接数比较少时,会自动关闭掉一些处于无用状态的连接;当请求量大的时候,再动态创建。
目前比较流行的几个连接池解决方案有:HikariCP、阿里的Druid、apache的DBCP等。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 使用C#创建一个MCP客户端
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现