连接池简介
1、连接池是创建和管理一个连接的缓冲池的技术,这些连接准备好被任何需要它们的线程使用。
作用:避免频繁地创建与消毁,给服务器减压力。
2、数据库的弊端:
1.当用户群体少服务器可以支撑,如果群体比较大万级别服务器直接死机。数据库默认的并发访问50.
2.每一个用完数据库之后直接关闭,不能重复利用太浪费资源。
3、设计连接池:
1.在池子中创建出多个连接供使用。
2.当用户需要操作数据库时直接从池子中获取连接即可。
3.当用户使用完毕之后把连接归还给连接池,可以达到重复使用。
4.可以设定池子的最大容器。比如50个连接,当第51个人访问的时候,需要等待。
5.其它用户释放资源的时候,可以使用。
4、手动实现连接池


import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.util.Properties; public class JDBCTool { private static Connection conn; private static String driverName; private static String username; private static String url; private static String password; static { InputStream is = JDBCTool.class.getClassLoader().getResourceAsStream("qq.properties"); Properties prop = new Properties(); try { prop.load(is); } catch (IOException e) { e.printStackTrace(); } driverName = (String)prop.get("driverClassName"); username = (String)prop.get("username"); url = (String)prop.get("url"); password = (String)prop.get("password"); try { Class.forName(driverName); } catch (Exception e) { e.printStackTrace(); } } public static Connection getConn() { try { conn = DriverManager.getConnection(url, username, password); } catch (SQLException e) { e.printStackTrace(); } return conn; } public static void close(Connection conn,PreparedStatement ps,ResultSet rs) { if(conn!=null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } if(ps!=null) { try { ps.close(); } catch (SQLException e) { e.printStackTrace(); } } if(rs!=null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
import java.sql.Connection; import java.util.ArrayList; import java.util.List; public class MyJDBCPool { /* 1.定义一个容器 集合 2.初始化连接,并放在池子中。 3.创建一个从容器中获取连接的方法 4.创建一个归还连接的方法。*/ private static List<Connection> pool = new ArrayList<>(); private static int List_size = 3; static { for(int i=0;i<List_size;i++) { Connection conn=null; conn = JDBCTool.getConn(); pool.add(conn); System.out.println("当前存放连接为:"+conn+",当前池子中剩余连接数为:"+pool.size()); } System.out.println("====================="); } //取出一个连接 要判断是否为空 public static Connection getConn() throws NullPointerException{ if(pool.isEmpty()) { System.out.println("请等待"); throw new NullPointerException("已经空了,别拿了"); } Connection conn = pool.remove(0); System.out.println("当前取出的连接为:"+conn+",当前剩余连接数为:"+pool.size()); return conn; } //归还连接 要判断是否为真正的连接 public static void returnConn(Connection conn) { if(conn==null) { System.out.println("你玩我?"); return; } pool.add(conn); System.out.println("当前存入的连接为:"+conn+",当前剩余连接数为:"+pool.size()); } }
import java.sql.Connection; public class Test1 { public static void main(String[] args) { Connection conn = MyJDBCPool.getConn(); Connection conn1 = MyJDBCPool.getConn(); Connection conn2 = MyJDBCPool.getConn(); MyJDBCPool.returnConn(conn2); MyJDBCPool.returnConn(conn1); MyJDBCPool.returnConn(conn); } }
注:这里涉及到一个properties文件,文件内容是key =value形式存在的,先使用类加载器(或输入流)将文件加载进来,然后使用properties对象处理文件,使用get()方法获取内容。
常用连接池
1、导入连接池的步骤
导包 buildpath
配置文件 properties
加载文件流,使用properties处理文件
使用连接池的API读取prop对象,创建连接池
getConnection获取连接
返回连接的引用
2、dbcp连接池 开源连接池,效率高,但安全性不强
工具包下载地址:http://commons.apache.org/proper/commons-pool/download_pool.cgi
http://commons.apache.org/proper/commons-dbcp/download_dbcp.cgi
导包 commons-dbcp 和commons-pool mysql-connection
配置文件导入*.properties 建议放在src根目录
import java.sql.Connection; import org.apache.commons.dbcp.BasicDataSource; public class Test1{ public static void main(String[] args) throws Exception{ BasicDataSource bds = new BasicDataSource(); // 4个必须设置的属性 bds.setDriverClassName("com.mysql.jdbc.Driver"); bds.setUrl("jdbc:mysql:///db0619"); bds.setUsername("root"); bds.setPassword("root"); //其他属性,都是可选属性 bds.setInitialSize(100); // 初始创建100个连接 bds.setMaxActive(50); // 最大活动数 bds.setMaxIdle(20); // 最大空闲数 bds.setMinIdle(10); // 最小空闲数 bds.setMaxWait(-1); // 最大等待时间 Connection conn = bds.getConnection(); System.out.println(conn); Connection conn2 = bds.getConnection(); System.out.println(conn2); } }
import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.InputStream; import java.sql.Connection; import java.sql.SQLException; import java.util.Properties; import javax.sql.DataSource; import org.apache.commons.dbcp.BasicDataSourceFactory; public class DBCPUtil { private static DataSource ds; static{ try { Properties p = new Properties(); InputStream is = new FileInputStream("src/db.properties"); p.load(is); ds = BasicDataSourceFactory.createDataSource(p); } catch (Exception e) { e.printStackTrace(); } } public static DataSource getDataSource(){ return ds; } public static Connection getConnection(){ Connection conn = null; try { conn = ds.getConnection(); } catch (SQLException e) { e.printStackTrace(); } return conn; } }
3、c3p0连接池
工具包:https://sourceforge.net/projects/c3p0/
导包 c3p0-0.9.5.2.jar mchange-commons-java... mysql-connection...
配置文件名称:c3p0-config.xml c3p0.properties
<?xml version="1.0" encoding="UTF-8"?> <c3p0-config> <!-- 默认配置,如果没有指定则使用这个配置 --> <default-config> <!-- 四个基本配置 --> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql:///db0619</property> <property name="user">root</property> <property name="password">root</property> <!-- 当连接池用完时客户端调用getConnection()后等待获取新连接的时间,超时后将抛出 SQLException,如设为0则无限期等待。单位毫秒。Default: 0 --> <property name="checkoutTimeout">30000</property> <!--隔多少秒检查连接池的空闲连接,0表示不检查--> <property name="idleConnectionTestPeriod">30</property> <!-- 初始化连接数 --> <property name="initialPoolSize">10</property> <!-- 连接的最大空闲时间,默认为0秒、不会关闭任何连接。设置30秒,30秒到期后, 连接若未使用就会被关闭 --> <property name="maxIdleTime">30</property> <!-- 池中最多的连接存放数目 --> <property name="maxPoolSize">100</property> <!-- 池中最少的连接存放数目 --> <property name="minPoolSize">10</property> <property name="maxStatements">200</property> </default-config> <named-config name="offcn"> <!-- 四个基本配置 --> <property name="driverClass">com.mysql.jdbc.Driver</property> <property name="jdbcUrl">jdbc:mysql:///test</property> <property name="user">root</property> <property name="password">root</property> <!-- 当连接池用完时客户端调用getConnection()后等待获取新连接的时间,超时后将抛出 SQLException,如设为0则无限期等待。单位毫秒。Default: 0 --> <property name="checkoutTimeout">30000</property> <!--隔多少秒检查连接池的空闲连接,0表示不检查--> <property name="idleConnectionTestPeriod">30</property> <!-- 初始化连接数 --> <property name="initialPoolSize">10</property> <!-- 连接的最大空闲时间,默认为0秒、不会关闭任何连接。设置30秒,30秒到期后, 连接若未使用就会被关闭 --> <property name="maxIdleTime">30</property> <!-- 池中最多的连接存放数目 --> <property name="maxPoolSize">100</property> <!-- 池中最少的连接存放数目 --> <property name="minPoolSize">10</property> <property name="maxStatements">200</property> </named-config> </c3p0-config>
import java.sql.Connection; import com.mchange.v2.c3p0.ComboPooledDataSource; public class Test1{ public static void main(String[] args) throws Exception{ ComboPooledDataSource cds = new ComboPooledDataSource(); //4 个基本设置 cds.setDriverClass("com.mysql.jdbc.Driver"); cds.setJdbcUrl("jdbc:mysql:///db0619"); cds.setUser("root"); cds.setPassword("root"); Connection conn = cds.getConnection(); System.out.println(conn); } }
import java.sql.Connection; import java.sql.SQLException; import javax.sql.DataSource; import com.mchange.v2.c3p0.ComboPooledDataSource; public class C3P0Util { private static DataSource ds; static{ //ds = new ComboPooledDataSource();//加载src/c3p0-config.xml,并使用配置文件中默认的配置配置<default-config> ds = new ComboPooledDataSource("offcn"); //加载src/c3p0-config.xml,并使用名字为offcn的配置配置 } public static DataSource getDataSource(){ return ds; } public static Connection getConnection(){ Connection conn = null; try { conn= ds.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return conn; } }
4、druid连接池
工具包:
导包:druid-1....jar mysql-connection...
配置文件名称 druid.properties
import java.io.InputStream; import java.sql.Connection; import java.sql.SQLException; import java.util.Properties; import javax.sql.DataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; public class DruidUtils { private static DataSource ds; private static Connection conn; static{ try { InputStream is = MyJDBC.class.getClassLoader().getResourceAsStream("druid.properties"); Properties prop = new Properties(); prop.load(is); ds = DruidDataSourceFactory.createDataSource(prop); } catch (Exception e) { e.printStackTrace(); } } public static Connection getConnection() { try { conn = ds.getConnection(); } catch (SQLException e) { // TODO Auto-generated catch block e.printStackTrace(); } return conn; } public static DataSource getDataSource() { return ds; } }
DBUTils工具类
1、DBUtils是java编程中的数据库操作实用工具,小巧简单实用。
2、核心类QueryRunner
3、数据更新操作使用update(String sql,Object[] params...); 若无指定连接,也可以在参数一前传Connection
参数一:sql语句 ,参数二 Object数组,对sql语句中的占位符赋值 返回值为int 代表更新了几行数据
4、数据查询操作 query(String sql,handler,Object[] params...); 若无指定连接,也可以在参数一前传Connection
参数一:sql语句 ,
参数二 :如何处理返回的二维表格Object[],List<Object[]>,map, list<map>,javaBean,List<JavaBean>,Object…
参数三:对sql语句中的占位符赋值
5、ResultSetHandler中常用的处理方式
|
BeanHandler |
将结果集中第一条记录封装到一个指定的javaBean中。 |
|
BeanListHandler |
将结果集中每一条记录封装到指定的javaBean中,将这些javaBean在封装到List集合中 |
|
MapHandler |
将结果集中第一条记录封装到了Map<String,Object>集合中,key就是字段名称,value就是字段值
|
|
MapListHandler |
将结果集中每一条记录封装到了Map<String,Object>集合中,key就是字段名称,value就是字段值,在将这些Map封装到List集合中。 |
|
ScalarHandler |
它是用于单数据。例如select count(*) from 表操作。 |
import java.sql.Connection; import java.sql.SQLException; import java.util.List; import java.util.Map; import org.apache.commons.dbutils.QueryRunner; import org.apache.commons.dbutils.handlers.ArrayHandler; import org.apache.commons.dbutils.handlers.BeanHandler; import org.apache.commons.dbutils.handlers.BeanListHandler; import org.apache.commons.dbutils.handlers.MapHandler; import org.apache.commons.dbutils.handlers.MapListHandler; import org.apache.commons.dbutils.handlers.ScalarHandler; import com.bean.Users; import com.utils.MyJDBC; public class UsersdaoImpl implements Usersdao { @Override public int insertUser(Users user) { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql="insert into users values(?,?,?)"; int result=0; try { result = qr.update(sql,new Object[] {user.getId(),user.getUsername(),user.getPwd()}); } catch (SQLException e) { e.printStackTrace(); } return result; } @Override public int deleteUserById(Integer id) { QueryRunner qr = new QueryRunner(); Connection conn = MyJDBC.getConnection(); String sql = "delete from users where id=?"; int result = 0; try { result = qr.update(conn, sql, id); } catch (SQLException e) { e.printStackTrace(); } return result; } @Override public int updateUser(Users user) { QueryRunner qr = new QueryRunner(); Connection conn = MyJDBC.getConnection(); String sql = "update users set username=?,pwd=? where id=?"; int result=0; try { result = qr.update(conn, sql,new Object[] {user.getUsername(),user.getPwd(),user.getId()}); } catch (SQLException e) { e.printStackTrace(); } return result; } @Override public List<Users> findAllStudent() { QueryRunner qr = new QueryRunner(); Connection conn = MyJDBC.getConnection(); String sql = "select * from users"; List<Users> list=null; try { list = qr.query(conn,sql, new BeanListHandler<>(Users.class)); } catch (SQLException e) { e.printStackTrace(); } return list; } @Override public Users findUserById(Integer id) { QueryRunner qr = new QueryRunner(); Connection conn = MyJDBC.getConnection(); String sql = "select * from users where id=?"; Users user=null; try { user = qr.query(conn,sql,new BeanHandler<>(Users.class),id); } catch (SQLException e) { e.printStackTrace(); } return user; } @Override public List<Users> findUserByName(String name) { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql = "select * from users where username like ?"; List<Users> list = null; try { list = qr.query(sql,new BeanListHandler<Users>(Users.class), "%"+name+"%"); } catch (SQLException e) { e.printStackTrace(); } return list; } @Override public Map<String, Object> findFirstRow() { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql = "select * from users"; Map<String,Object> map = null; try { map=qr.query(sql, new MapHandler()); } catch (SQLException e) { e.printStackTrace(); } return map; } @Override public List<Map<String, Object>> findAllStudent2() { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql = "select * from users"; List<Map<String, Object>> lm=null; try { lm = qr.query(sql, new MapListHandler()); } catch (SQLException e) { e.printStackTrace(); } return lm; } @Override public long findUserCount() { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql = "select count(username) from users where username='HH'"; long l=0; try { l =(long)qr.query(sql,new ScalarHandler()); } catch (SQLException e) { e.printStackTrace(); } return l; } @Override public Object[] findStudent() { QueryRunner qr = new QueryRunner(MyJDBC.getDataSource()); String sql = "select * from users"; Object[] s=null; try { s = qr.query(sql, new ArrayHandler()); } catch (SQLException e) { e.printStackTrace(); } return s; } }
import java.util.List; import java.util.Map; import org.junit.Test; import com.bean.Users; import com.dao.Usersdao; import com.dao.UsersdaoImpl; public class Test { Usersdao us = new UsersdaoImpl(); @Test public void test1() { Users user1 = new Users(); user1.setId(null); user1.setUsername("小红"); user1.setPwd("112233"); int result = us.insertUser(user1); if(result>0) { System.out.println("添加成功"); }else { System.out.println("添加失败"); } } @Test public void test2() { int result = us.deleteUserById(7); if(result>0) { System.out.println("删除成功"); }else { System.out.println("删除失败"); } } @Test public void test3() { Users user = new Users(); user.setId(10); user.setUsername("HH"); user.setPwd("123456"); int result = us.updateUser(user); if(result>0) { System.out.println("修改成功"); }else { System.out.println("修改失败"); } } @Test public void test4() { List<Users> list = us.findAllStudent(); for(Users user:list) { System.out.println(user.getId()+"\t"+user.getUsername()+"\t"+user.getPwd()); } } @Test public void test5() { Users user = us.findUserById(3); System.out.println(user.getId()+"\t"+user.getUsername()+"\t"+user.getPwd()); } @Test public void test6() { List<Users> list = us.findUserByName("刘"); for(Users user:list) { System.out.println(user.getId()+"\t"+user.getUsername()+"\t"+user.getPwd()); } } @Test public void test7() { Map<String, Object> map = us.findFirstRow();//返回查询的第一条数据 key为字段 value为字段值 System.out.println(map); } @Test public void test8() { List<Map<String, Object>> lm = us.findAllStudent2(); for(Map<String,Object> map:lm) { System.out.println(map); } } @Test public void test9() { long l = us.findUserCount(); System.out.println(l); } @Test public void test10() { Object[] obj = us.findStudent(); System.out.println(obj); } }
import java.util.List; import java.util.Map; import com.bean.Users; public interface Usersdao { public int insertUser(Users user); public int deleteUserById(Integer id); public int updateUser(Users user); public List<Users> findAllStudent(); public Users findUserById(Integer id); public List<Users> findUserByName(String name); public Map<String,Object> findFirstRow(); public List<Map<String,Object>> findAllStudent2(); public long findUserCount(); public Object[] findStudent(); }
事务
1、什么是事务?
事务: 一组SQL操作,要么同时成功,要么同时失败。
2、在实际的业务开发中,有些业务操作要多次访问数据库。一个业务要发送多条SQL语句给数据库执行。需要将多次 访问数据库的操作视为一个整体来执行,要么所有的SQL语句全部执行成功。如果其中有一条SQL语句失败,就进行事务的回滚,所有的SQL语句全部执行失败。 例如: jack给tom转账,jack账号减钱,tom账号加钱。
3、MYSQL中可以有两种方式进行事务的操作:
自动提交事务:默认
手动提交事务:Start transaction; //开启事务
Sql1
Sql2
Sql3
...
Sqln
Commit;
4、回滚点 savepoint
在某些成功的操作完成之后,后续的操作有可能成功有可能失败,但是不管成功还是失败,前面操作都已经成功, 可以在当前成功的位置设置一个回滚点。可以供后续失败操作返回到该位置,而不是返回所有操作,这个点称之为 回滚点。
Start transaction;
Sql1
Sql2;
Savepoint ‘aaa’;
Sql3
...
Sqln
Rollback to ‘aaa’
Commit;
5、java中操作事务的方式
try{
conn.setAutoCommit(false); //默认为true 自动提交事务 false设置为手动提交
操作1,2,3,。。。 //注意,这些操作需是同一个conn连接去执行
conn.commit() //提交事务
}catch(SQLException e){
conn.rollback(); //回滚
e.printStackTrace();
}
import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.SQLException; import com.utils.C3P0Util; public class MyTransaction { public static void main(String[] args) { Connection conn = C3P0Util.getConnection(); PreparedStatement ps = null; try { conn.setAutoCommit(false); // 默认值时true --- 设置为手动提交事务 String sql = "update account set money=money+1000 where name='Tom'"; String sql2 = "update account set money=money+1000 where name='Tom'"; ps = conn.prepareStatement(sql); ps.executeUpdate(); ps = conn.prepareStatement(sql2); ps.executeUpdate(); conn.commit(); //提交事务 } catch (SQLException e) { try { conn.rollback(); // 回滚 } catch (SQLException e1) { e1.printStackTrace(); } e.printStackTrace(); } } }
6、事务的四大特性
|
事务特性 |
含义 |
|
原子性 (Atomicity) |
事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。 |
|
一致性 (Consistency) |
事务前后数据的完整性必须保持一致 |
|
隔离性 (Isolation) |
是指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个 并发事务之间数据要相互隔离,不能相互影响。 |
|
持久性 (Durability) |
指一个事务一旦被提交(commit),它对数据库中数据的改变就是永久性的,接下来即使数据库发 生故障也不应该对其有任何影响 |
7、几类事务的问题
- 第1类丢失更新:事务A撤销时,把已经提交的事务B的更新数据覆盖了。
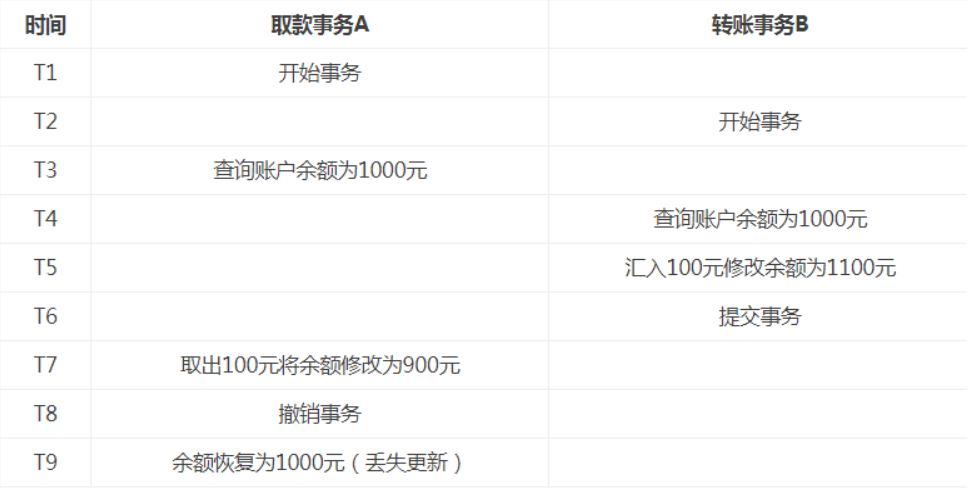
第2类丢失更新:事务A提交时覆盖事务B已经提交的数据,造成事务B所做的操作丢失。

解决方法:对行加锁,只允许并发一个更新事务。
- 脏读(Dirty Read):A事务读取B事务尚未提交的数据并在此基础上操作,而B事务执行回滚,那么A读取到的数据就是脏数据。

解决方法:如果在第一个事务提交前,任何其他事务不可读取其修改过的值,则可以避免该问题。
- 不可重复读(Non-repeatable Reads)
一个事务对同一行数据重复读取两次,但是却得到了不同的结果。事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时得到与前一次不同的值。

解决办法:如果只有在修改事务完全提交之后才可以读取数据,则可以避免该问题。
- 幻象读:指两次执行同一条 select 语句会出现不同的结果,第二次读会增加一数据行,并没有说这两次执行是在同一个事务中。
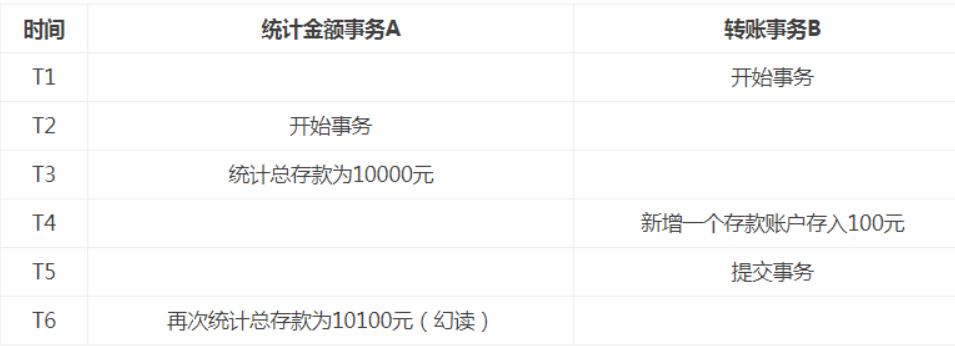
解决办法:如果在操作事务完成数据处理之前,任何其他事务都不可以添加新数据,则可避免该问题。
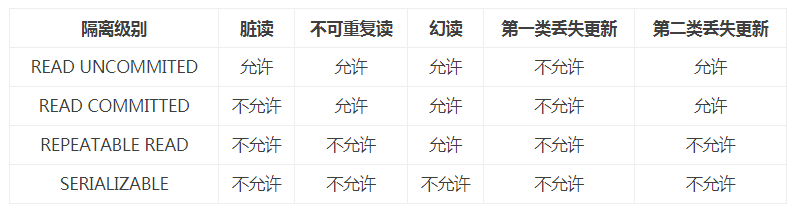
8、数据库事务的隔离级别有4个,由低到高依次为Read uncommitted(未授权读取、读未提交)、Read committed(授权读取、读提交)、Repeatable read(可重复读取)、Serializable(序列化),这四个级别可以逐个解决脏读、不可重复读、幻象读这几类问题。
- Read uncommitted(未授权读取、读未提交):
如果一个事务已经开始写数据,则另外一个事务则不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。这样就避免了更新丢失,却可能出现脏读。也就是说事务B读取到了事务A未提交的数据。 - Read committed(授权读取、读提交):
读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。该隔离级别避免了脏读,但是却可能出现不可重复读。事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。 - Repeatable read(可重复读取):
可重复读是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,即使第二个事务对数据进行修改,第一个事务两次读到的的数据是一样的。这样就发生了在一个事务内两次读到的数据是一样的,因此称为是可重复读。读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。这样避免了不可重复读取和脏读,但是有时可能出现幻象读。(读取数据的事务)这可以通过“共享读锁”和“排他写锁”实现。 - Serializable(序列化):
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。序列化是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号