
Python爬虫-AJAX数据爬取实战(七)
一、案例分析
这里还需要借助浏览器的开发者工具来查看ajax请求,
下面以 Chrome 浏览器为例来介绍。
首先,用 Chrome 浏览器打开微博的链接 https://m.weibo.cn/u/2830678474,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择,随后在页面中点击鼠标右键,从弹出的快捷菜单中选择) “检查” 选项,此时便会弹出开发者工具,如图所示:
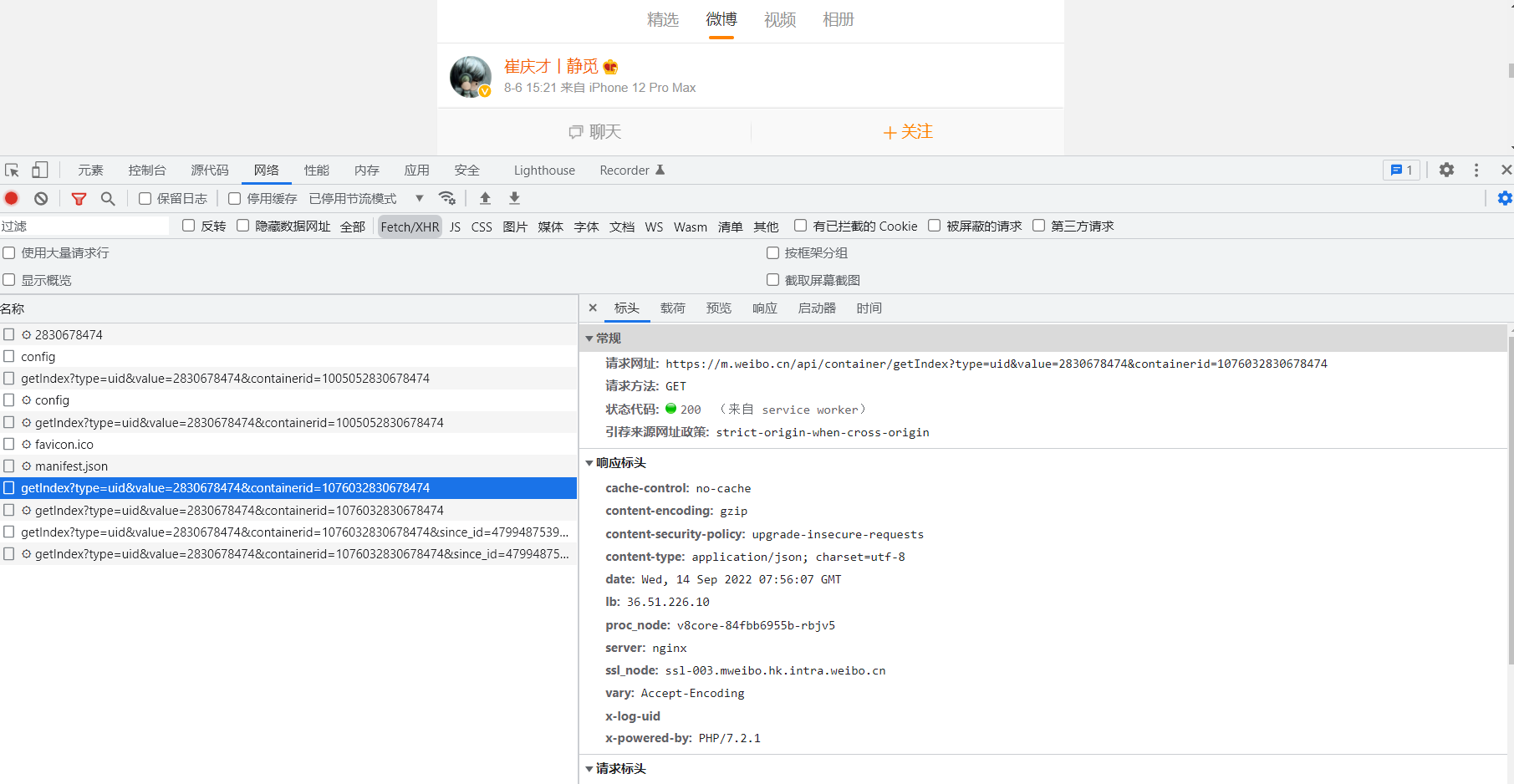
在右侧可以观察到其 Request Headers、URL 和 Response Headers 等信息。其中 Request Headers 中有一个信息为 X-Requested-With:XMLHttpRequest,这就标记了此请求是 Ajax 请求,如图所示:

二、AJAX数据爬取实战
先了解下什么是since_id:python-新浪爬取话题微博实践,简单说:在当前页面,Preview下的cardlistInfo下的since_id保存的就是下一个页面的Request URL里的since_id,注意,第一个页面里的Request URL没有since_id
如图所示:

分析思路:
我们可以在get_page(since_id=None)中传入since_id参数,因为第一个页面没有since_id,因此我们将since_id默认为None。
这个函数将会返回一个元组,其中包括了下一个页面的since_id和当前页面的json格式页面内容。利用返回的元组索引,我们就可以获得即将访问的下一个页面的since_id。
代码示例:
import time
from urllib.parse import urlencode
import requests
base_url='https://m.weibo.cn/api/container/getIndex?'
from pyquery import PyQuery as pq
headers={
'Referer':'https://m.weibo.cn/u/2830678474',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36',
'X-Requested-With':'XMLHttpRequest',
'X-XSRF-TOKEN':'0ea919'
}
def get_page(since_id=None):
"""获取微博列表下拉数据"""
params={
'type':'uid',
'value':'2830678474',
'containerid':'1076032830678474',
'since_id':since_id
}
url=base_url+urlencode(params)
try:
respone=requests.get(url,headers=headers)
if respone.status_code==200:
res=respone.json()
items=res.get('data').get('cardlistInfo')
#返回下一个分页since_id
next_since_id=items['since_id']
return (res,next_since_id)
except requests.ConnectionError as e:
print('Error',e.args)
def parse_page(json):
if json:
items=json.get('data').get('cards')
for item in items:
item=item.get('mblog')
weibo={}
weibo['id']=item.get('id')
weibo['source']=item.get('source')
weibo['favorited']=item.get('favorited')
weibo['text']=pq(item.get('text')).text()
weibo['screen_name']=item.get('user')['screen_name']
weibo['profile_url']=item.get('user')['profile_url']
# print(weibo)
yield weibo
#连接数据库
import pymysql
db = pymysql.connect(host='xxx.xxx.xxx.xxx',user='root', password='root', port=3308,database='spiders')
def drop_table(table):
'''删除表数据'''
cursor = db.cursor()
db.ping(reconnect=True)
sql="drop table if exists %s" % table
cursor.execute(sql)
print('删除数据表成功')
db.close()
def create_table(table):
#创建数据库表
cursor = db.cursor()
db.ping(reconnect=True)
sql ="CREATE TABLE IF NOT EXISTS %s (id VARCHAR(255) NOT NULL, source VARCHAR(255) NOT NULL, favorited VARCHAR(255) NOT NULL,text VARCHAR(255) NOT NULL, screen_name VARCHAR(255) NOT NULL,profile_url VARCHAR(255) NOT NULL,PRIMARY KEY (id))" % table
cursor.execute(sql)
print('创建数据表成功')
db.close()
def insert_table1(id=None,text=None,source=None,favorited=None,screen_name=None,profile_url=None):
'''动态插入数据'''
data = {
'id': id,
'text': text,
'source': source,
'favorited': favorited,
'screen_name': screen_name,
'profile_url': profile_url,
}
table = 'ajax_result01'
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
cursor = db.cursor()
db.ping(reconnect=True)
sql = 'INSERT INTO {table}({keys}) VALUES ({values})'.format(table=table, keys=keys, values=values)
# print(keys)
# print(values)
try:
if cursor.execute(sql,tuple(data.values())):
print('success')
db.commit()
except:
print('faild-插入表数据失败')
db.rollback()
db.close()
def main():
drop_table('ajax_result01')
create_table('ajax_result01')
time.sleep(2)
for i in range(2):
if i==0:
"i==0第一页since_id不需要传参"
print("第{}页".format(i+1))
tuple_since_id = get_page()
# print(tuple_since_id)
results = parse_page(tuple_since_id[0])
for result in results:
id=result['id']
text=result['text']
source=result['source']
favorited=result['favorited']
screen_name=result['screen_name']
profile_url=result['profile_url']
print(result['id'])
print(result['text'])
print(result['source'])
print(result['favorited'])
print(result['screen_name'])
print(result['profile_url'])
time.sleep(1)
#将爬取到的数据插入到mysql数据表
insert_table1(id, text, source, favorited, screen_name, profile_url)
else:
print("第{}页".format(i+1))
tuple_since_id = get_page()
#调用tuple_since_id两次,第1次拿到next_since_id的值,第2次同上取到res值
tuple_since_id = get_page(tuple_since_id[1])
results = parse_page(tuple_since_id[0])
for result in results:
id = result['id']
text = result['text']
source = result['source']
favorited = result['favorited']
screen_name = result['screen_name']
profile_url = result['profile_url']
print(result['id'])
print(result['text'])
print(result['source'])
print(result['favorited'])
print(result['screen_name'])
print(result['profile_url'])
time.sleep(1)
# 将爬取到的数据插入到mysql数据表
insert_table1(id, text, source, favorited, screen_name, profile_url)
if __name__ == '__main__':
main()
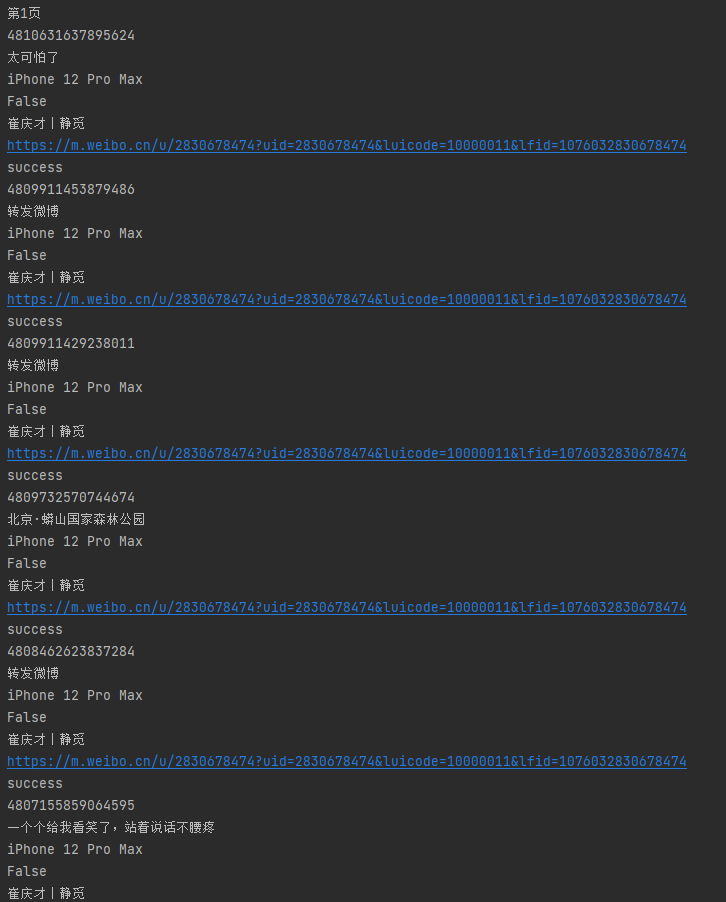
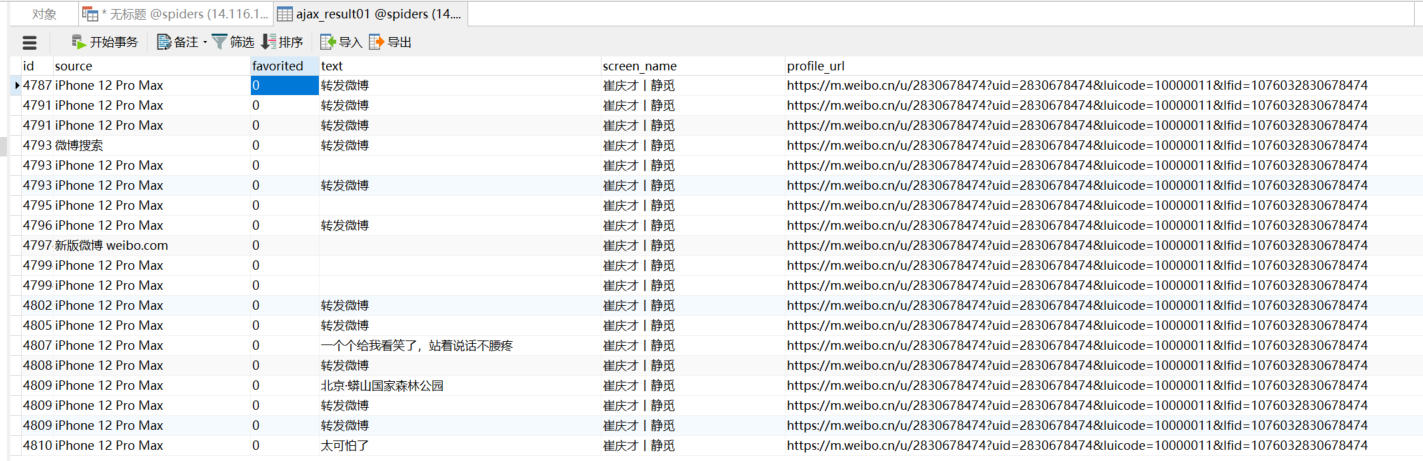
运行结果:
本文来自博客园,作者:橘子偏爱橙子,转载请注明原文链接:https://www.cnblogs.com/xfbk/p/16693442.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号