
Python爬虫-Xpath语法与lxml库的用法(二)
一、 安装
pip方式安装
pip install lxml
二、 Xpath术语
2.1 节点
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。XML 文档是被作为节点树来对待的。树的根被称为文档节点或者根节点。
请看下面这个 XML 文档:
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
上面的XML文档中的节点例子:
<bookstore> (根节点) <author>J K. Rowling</author> (元素节点) lang="en" (属性节点)
2.2 节点关系
父(Parent)
每个元素以及属性都有一个父。
在下面的例子中,book 元素是 title、author、year 以及 price 元素的父:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
子(Children)
元素节点可有零个、一个或多个子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
兄弟(Sibling)
拥有相同的父的节点
在下面的例子中,title、author、year 以及 price 元素都是兄弟:
<book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
先辈(Ancestor)
某节点的父、父的父,等等。
在下面的例子中,title 元素的先辈是 book 元素和 bookstore 元素:
<bookstore> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> </bookstore>
后代(Descendant)
某个节点的子,子的子,等等。
在下面的例子中,bookstore 的后代是 book、title、author、year 以及 price 元素:
2.3 选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
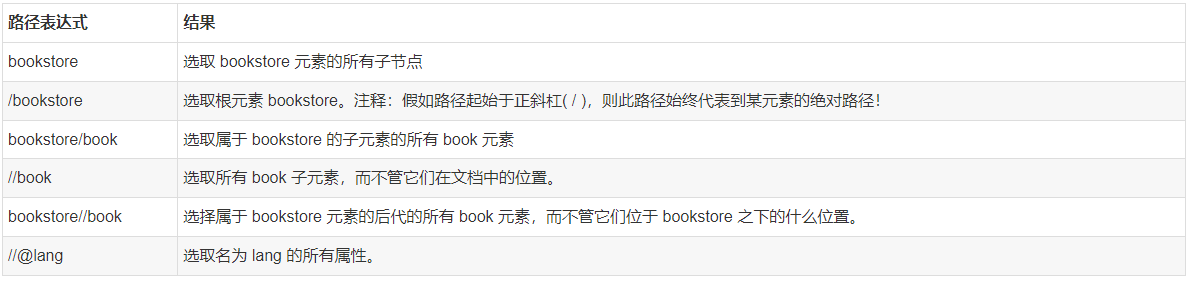
下面列出了最有用的路径表达式:
|
|
描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
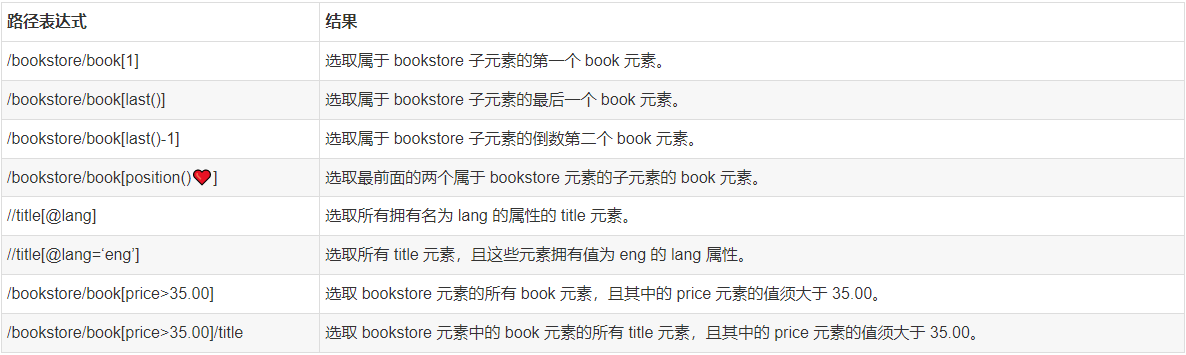
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。

在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:

选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。

2.4 XPath 实例
# -*- coding: utf-8 -*-
from lxml import etree
text = """
<div class="wrapper">
<i class="iconfont icon-back" id="back"></i>
<a rel="nofollow" href="/" id="channel">新浪社会</a>
<ul id="nav">
<li><a rel="nofollow" href="http://domestic.firefox.sina.com/" title="国内">国内</a></li>
<li><a rel="nofollow" href="http://world.firefox.sina.com/" title="国际">国际</a></li>
<li><a rel="nofollow" href="http://mil.firefox.sina.com/" title="军事">军事</a></li>
<li><a rel="nofollow" href="http://photo.firefox.sina.com/" title="图片">图片</a></li>
<li><a rel="nofollow" href="http://society.firefox.sina.com/" title="社会">社会</a></li>
<li><a rel="nofollow" href="http://ent.firefox.sina.com/" title="娱乐">娱乐</a></li>
<li><a rel="nofollow" href="http://tech.firefox.sina.com/" title="科技">科技</a></li>
<li><a rel="nofollow" href="http://sports.firefox.sina.com/" title="体育">体育</a></li>
<li><a rel="nofollow" href="http://finance.firefox.sina.com/" title="财经">财经</a></li>
<li><a rel="nofollow" href="http://auto.firefox.sina.com/" title="汽车">汽车</a></li>
</ul>
<i class="iconfont icon-liebiao" id="menu"></i>
</div>
"""
# 创建html对象
html = etree.HTML(text)
# 获取所有a标签的href内容
results = html.xpath('//a/@href')
print(results)
# 获取所有id为channel的a标签的href内容
results2 = html.xpath('//a[@id="channel"]/@href')
print(results2)
# 获取所有li标签下的a标签的文本内容
results3 = html.xpath('//li/a/text()')
print(results3)
运行结果如下:
['/', 'http://domestic.firefox.sina.com/', 'http://world.firefox.sina.com/', 'http://mil.firefox.sina.com/', 'http://photo.firefox.sina.com/', 'http://society.firefox.sina.com/', 'http://ent.firefox.sina.com/', 'http://tech.firefox.sina.com/', 'http://sports.firefox.sina.com/', 'http://finance.firefox.sina.com/', 'http://auto.firefox.sina.com/'] ['/'] ['国内', '国际', '军事', '图片', '社会', '娱乐', '科技', '体育', '财经', '汽车']
备注:
Ranorex Selocity 类似firepath的chrome插件
http://crx4.com/8198.html
本文来自博客园,作者:橘子偏爱橙子,转载请注明原文链接:https://www.cnblogs.com/xfbk/p/16637692.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号