
fiddler抓包请求一键批量转换成python代码
使用教程:
首先从Fiddler选中你要转换的请求 -> Save -> Selected Session -> as Text(也可以选择as Text(Header only)...),如图所示:
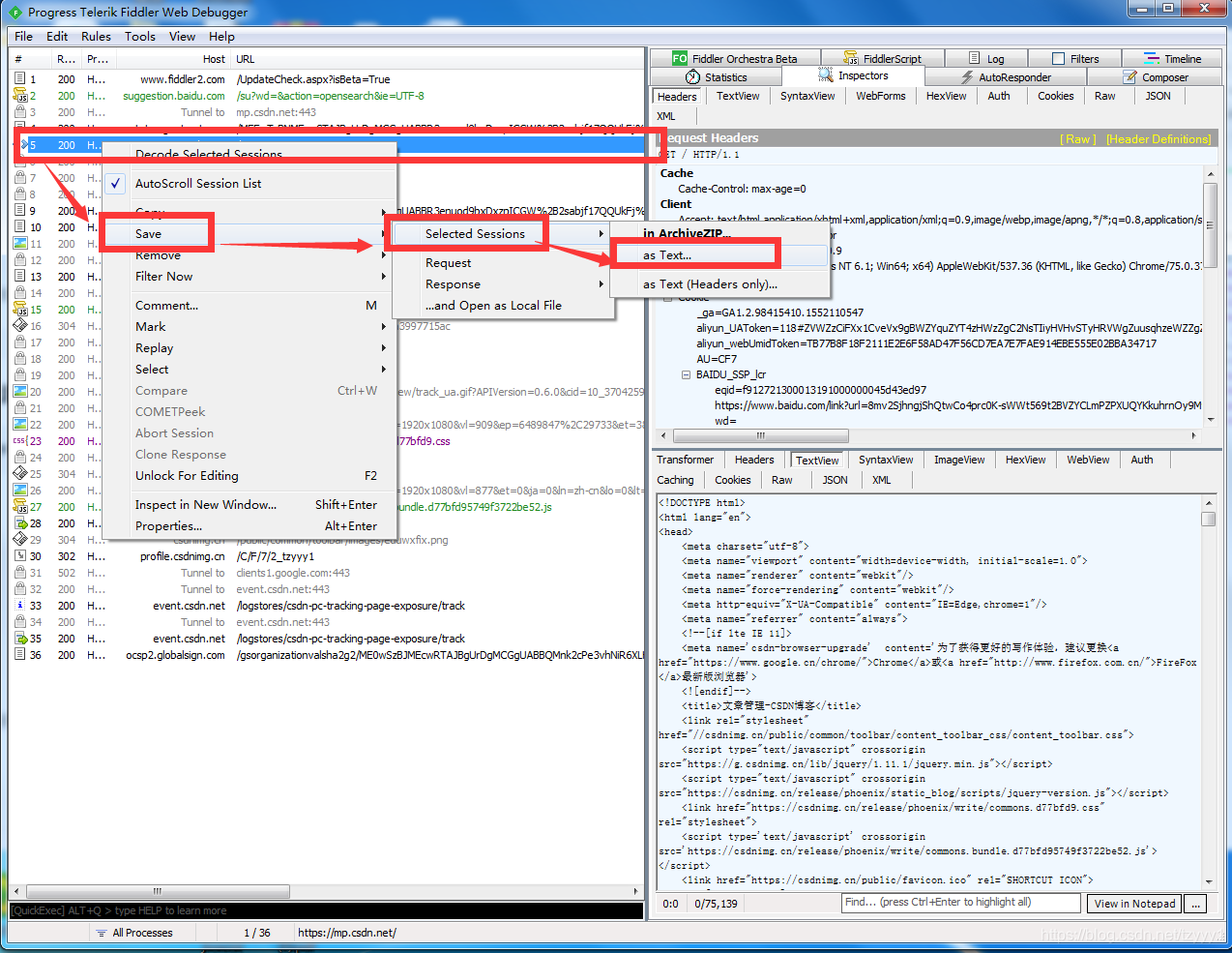
这样,我们就得到了包含了这个请求的txt文本(把这个文件移动到和前面Python代码同一个文件夹)
代码展示:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
def batch_test():
"""批量读取"""
file_dir = os.path.join(os.path.dirname(__file__))
print(file_dir)
return_list = []
for root, dirs, files in os.walk(file_dir):
for str_filename in files:
#Full.txt fiddler保存下来的所有txt文件,需要Full.txt后缀格式,可以自己手动修改后缀格式
if str_filename.endswith('Full.txt'):
return_list.append(str_filename)
# print(return_list)
return return_list
class FidToPy(object):
def __init__(self, str_name, sa_name):
self.str_filename = str_name
self.save_name = sa_name
self.text = ""
self.url_list = []
self.headers = {}
self.cookies = {}
self.data = {}
def get_url(self):
infos = self.text.split("\n")[0]
self.url_list = [infos.split(" ")[0], infos.split(" ")[1]]
def get_headers(self):
infos = self.text.split("\n")[1:]
info = ""
for i in infos:
if "Cookie: " in i:
break
info += i + "\n"
headers = info.split("\n")
while "" in headers:
headers.remove("")
for i in headers:
if ": " not in i:
break
self.headers[i.split(": ")[0]] = i.split(": ")[1]
def get_cookies(self):
infos = self.text.split("\n")[1:]
cookies_flag = 0
for i in infos:
if "Cookie: " in i:
self.cookies = i.replace("Cookie: ", "")
print(self.cookies)
cookies_flag = 1
break
if cookies_flag == 1:
self.cookies = {i.split("=")[0]: i.split("=")[1] for i in self.cookies.split("; ")}
def get_data(self):
try:
infos = self.text.split("\n")
for i in range(2, len(infos)):
if infos[i - 1] == "" and "HTTP" in infos[i + 1]:
self.data = infos[i]
break
self.data = {i.split("=")[0]: i.split("=")[1] for i in self.data.split("&")}
except:
pass
def get_req(self, sa_name):
info_beg = "#!/usr/bin/python\n# -*- coding: UTF-8 -*-\nimport requests\n\n"
info_url = "url = \'{}\'\n".format(self.url_list[1])
info_headers = "headers = {}\n".format(self.headers)
info_cookies = "cookies = {}\n".format(self.cookies)
info_data = "data = {}\n\n".format(self.data)
if "GET" in self.url_list[0]:
info_req = "html = requests.get(url, headers=headers, verify=False, cookies=cookies)\n"
else:
info_req = "html = requests.post(url, headers=headers, verify=False, cookies=cookies, data=data)\n"
info_end = "print(len(html.text))\nprint(html.text)\n"
text = info_beg + info_url + info_headers + info_cookies + info_data + info_req + info_end
print(text)
with open(self.save_name, "w+", encoding="utf8") as p:
p.write(text)
print("转化成功!!")
print(self.save_name, "文件保存!")
def read_infos(self):
with open(self.str_filename, "r+", encoding="utf-8") as p:
old_line = ""
for line in p:
if old_line == b"\n" and line.encode() == b"\n":
break
old_line = line.encode()
self.text += old_line.decode()
# print("self.text:", self.text)
def start(self) -> object:
self.read_infos()
self.get_url()
self.get_headers()
self.get_cookies()
self.get_data()
print("self.url_list:", self.url_list)
print("self.headers:", self.headers)
print("self.cookies:", self.cookies)
print("self.data:", self.data)
self.get_req(self.save_name)
if __name__ == '__main__':
for i in batch_test():
save_name = i.replace("txt", "py")
print(save_name)
print(type(save_name))
file_dir =os.path.abspath(os.path.join(os.path.dirname(__file__),save_name))
print(i)
print(file_dir)
f = FidToPy(i,file_dir)
f.start()
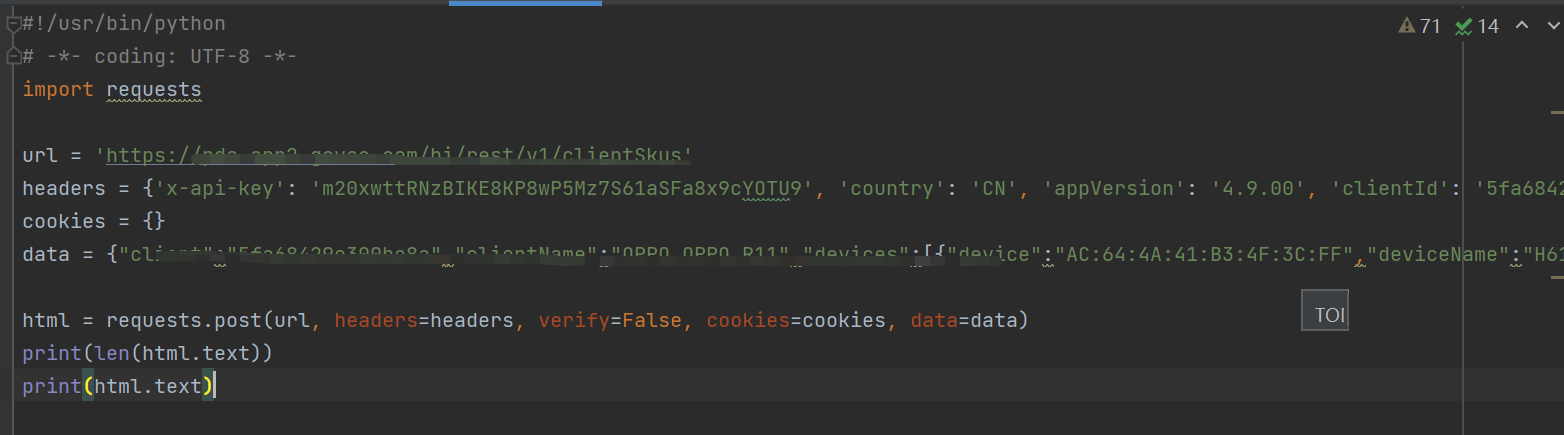
执行文件后展示:
参考文档:https://blog.csdn.net/tzyyy1/article/details/98512856
本文来自博客园,作者:橘子偏爱橙子,转载请注明原文链接:https://www.cnblogs.com/xfbk/p/15976149.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号