

作业2
作业2
1.
empty只有一个nan???
功能torch.empty()返回填充有未初始化数据的张量
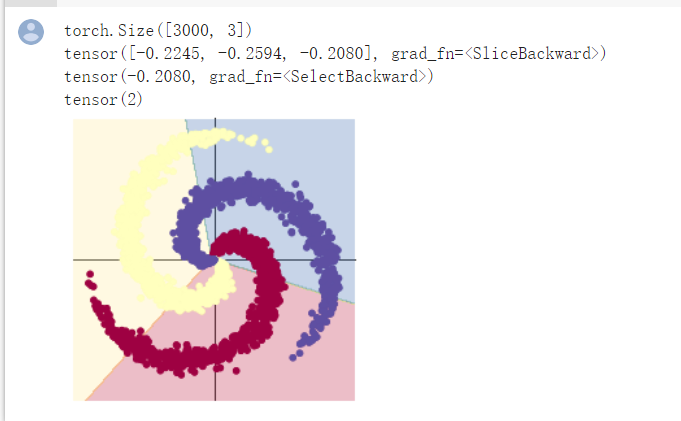
创建线性模型之后的分类结果
learning_rate = 1e-3
lambda_l2 = 1e-5
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()
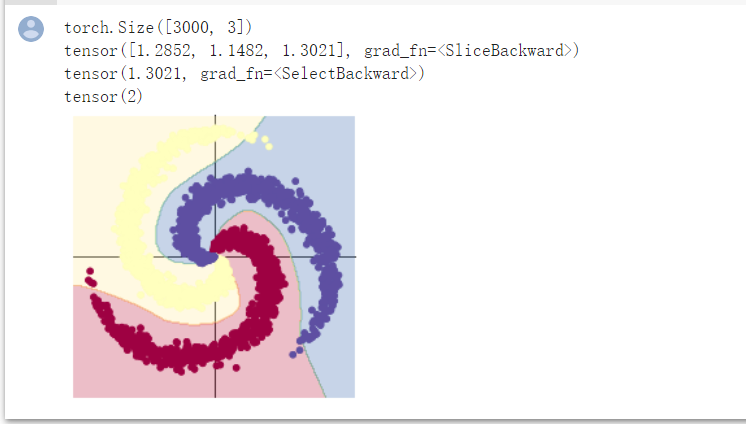
由图示明显能够看出,两层神经网络分类更加精细,准确,符合神经网络学习的特点,在运行时准确率达到0.95,而线性只有0.504;
但线性分类也有其优点,训练速度很快,预测速度也很快,可以推广到很大的数据集,对稀疏数据也有效。线性模型的另一个优点在于,根据回归和分类的公式,理解如何进行预测是相对比较容易的。
如果特征数量大于样本数量,线性模型的表现通常都很好。它也常用于非常大的数据集,只是因为训练其他模型并不可行。但在更低维的空间中,其他模型的泛化性能可能更好。
