
第四次作业-肖大智
猫狗大战代码学习

import numpy as np
import matplotlib.pyplot as plt
import os
import torch
import torch.nn as nn
import torchvision
from torchvision import models, transforms, datasets
import time
import json
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("Using gpu: %s" % torch.cuda.is_available())
数据预处理
下载重新整理好的数据集
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip ! unzip dogscats.zip
进行数据预处理
normalize = transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]) #对图像进行标准化
vgg_format = transforms.Compose([transforms.CenterCrop(224), #把许多步骤组合在一起
transforms.ToTensor(),
normalize])
data_dir = "./dogscats"
dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) #数据加载器
for x in ['train', 'valid']}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']}
dset_classes = dsets['train'].classes
Normalize(),对图像进行标准化,与ToTensor()搭配,将图像灰度范围从0~255变换到-1~1。
Compose(),即把许多步骤组合在一起。
ImageFolder是一个数据加载器,要求按照一定格式组织数据集。其返回的dset有三个属性:self.classes,用一个list保存类别名称。self.class_to_idx,类别对应的索引。self.imgs,是保存(img-path, class)元组的list。
我们可以打印出train的dsets进行观察。

loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6)
'''
valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400
同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看
'''
count = 1
for data in loader_valid:
print(count, end='\n')
if count == 1:
inputs_try,labels_try = data
count +=1
print(labels_try)
print(inputs_try.shape)
DataLoader本质上是一个可迭代对象,将数据集分成若干小的、随机的batch。对于训练集,我们一般使用shuffle乱序,而验证集和测试集不使用。
创建VGG Model
我们直接选择预训练好的VGG模型,使用softmax对结果进行处理
!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
model_vgg = models.vgg16(pretrained=True)
with open('./imagenet_class_index.json') as f:
class_dict = json.load(f)
dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))]
inputs_try , labels_try = inputs_try.to(device), labels_try.to(device)
model_vgg = model_vgg.to(device)
outputs_try = model_vgg(inputs_try)
print(outputs_try)
print(outputs_try.shape)
'''
可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。
但是我也可以观察到,结果非常奇葩,有负数,有正数,
为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数
'''
m_softm = nn.Softmax(dim=1)
probs = m_softm(outputs_try)
vals_try,pred_try = torch.max(probs,dim=1)
print( 'prob sum: ', torch.sum(probs,1))
print( 'vals_try: ', vals_try)
print( 'pred_try: ', pred_try)
print([dic_imagenet[i] for i in pred_try.data])
imshow(torchvision.utils.make_grid(inputs_try.data.cpu()),
title=[dset_classes[x] for x in labels_try.data.cpu()])

修改VGG层
VGG模型有三种元素,卷积层CONV,全连接层FC,池化层Pool。
观察VGG的结构后,我们需要将其最后的nn.Linear由1000类修改为2类,使其对应本次的实验。因为是预训练好的VGG,我们在训练中冻结前面层的参数,仅更新最后一层。
print(model_vgg)
model_vgg_new = model_vgg;
for param in model_vgg_new.parameters():
param.requires_grad = False
model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2)
model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1)
model_vgg_new = model_vgg_new.to(device)
print(model_vgg_new.classifier)
修改后的VGG模型,注意到最后Linear的out_features=2。

进行训练并测试
'''
第一步:创建损失函数和优化器
损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签.
它不会为我们计算对数概率,适合最后一层是log_softmax()的网络.
'''
criterion = nn.NLLLoss()
# 学习率
lr = 0.001
# 随机梯度下降
optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr)
'''
第二步:训练模型
'''
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train() #是保证BN层用每一批数据的均值和方差,随机取一部分网络连接来训练更新参数
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer = optimizer
optimizer.zero_grad()
loss.backward()
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
# 模型训练
train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg)
训练效果的准确率在94%左右。
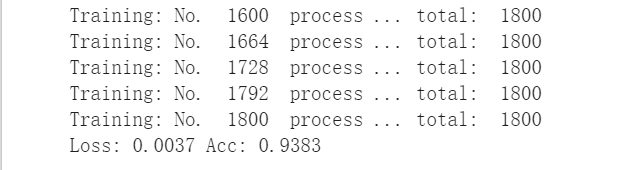
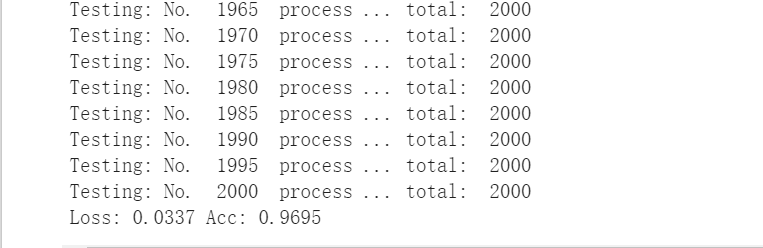
去验证测试集,发现准确率在97%左右
我们最后可视化一下输出,发现效果还是可以的。

猫狗大战上手练习
数据预处理
学习了上述代码之后,我们开始自己练习,下载并解压研习社的数据集。
!wget https://static.leiphone.com/cat_dog.rar !unrar x cat_dog.rar
研习社给出的数据集的文件组织形式和ImageFolder要求的不一样,需要自己更改。
import shutil
def classify_pics(dir_name):
path = "./cat_dog/" + dir_name + "/"
cat = path + "cat"
dog = path + "dog"
if not os.path.exists(cat):
os.makedirs(cat)
if not os.path.exists(dog):
os.makedirs(dog)
files = os.listdir(path)
for file in files:
if not os.path.isdir(file):
name = os.path.splitext(file)[0].split('_')[0]
if name == 'cat':
shutil.move(path+file, cat)
elif name == 'dog':
shutil.move(path+file, dog)
classify_pics("train")
classify_pics("valid")
path = "./cat_dog/test/"
raw = path + "raw"
if not os.path.exists(raw):
os.makedirs(raw)
files = os.listdir(path)
for file in files:
if not os.path.isdir(file):
shutil.move(path+file, raw)
最终实现如下形式的数据组织格式,划分为训练集,验证集,测试集。其中数据集20000张,验证集和测试集各2000张。

拿到数据集以后,剩下的步骤和上边的代码学习类似,只需要简单依照数据集修改一下。
使用VGG模型训练并测试
训练集的训练效果如下:
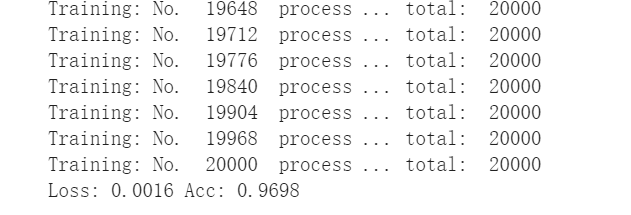
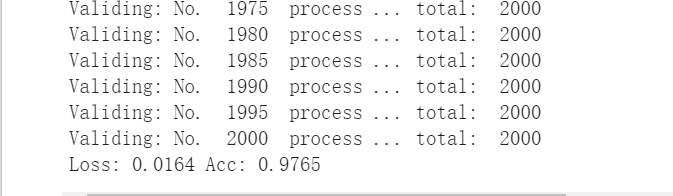
验证集的验证效果如下:
最后是将测试结果写到csv文件中,提交到研习社,查看最终的测试效果。
def test_model(model,dataloader,size):
model.eval()
#predictions = np.zeros(size)
i = 0
total_preds = {}
for inputs, classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
_,preds = torch.max(outputs.data,1)
key = dsets['test'].imgs[i][0]
print(key)
total_preds[key] = preds[0]
i+=1
with open("./res.csv", "a+") as f:
for i in range(size):
f.write("{},{}\n".format(i, total_preds["./cat_dog/test/raw/" + str(i) + ".jpg"]))
test_model(model_vgg_new, loader_test, size=dset_sizes['test'])
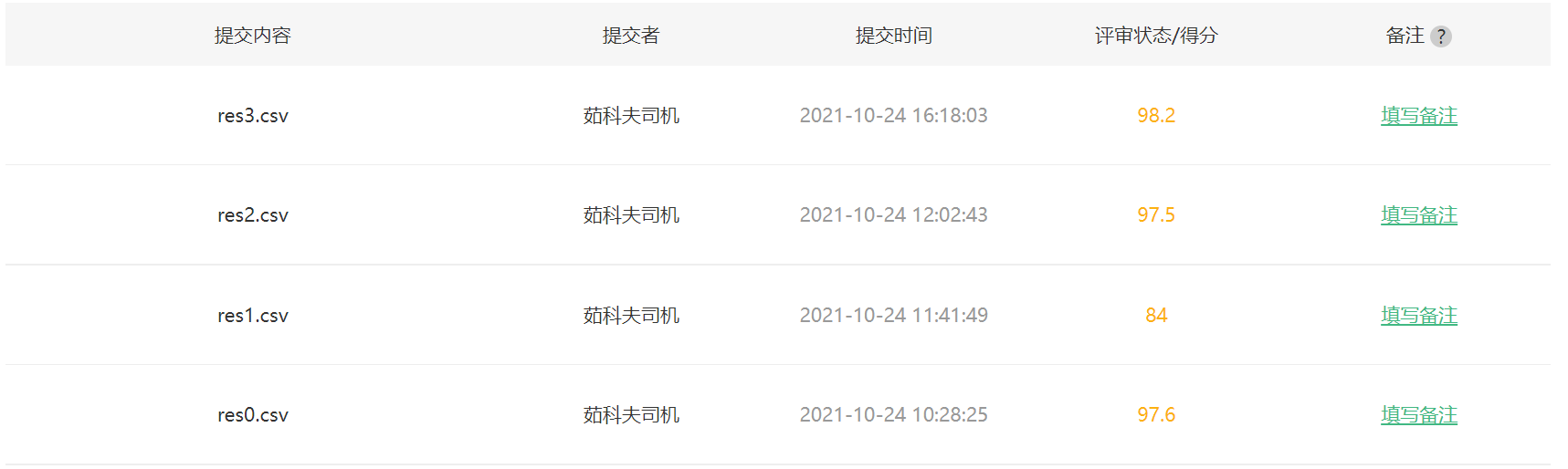
最终结果是在97.6%

进行优化
首先可以想到利用transforms对数据进行增强。
选用了transforms.RandomRotate()对数据集进行随机旋转,transforms.ColorJitter()对数据集进行亮度等属性的变化。
然后在训练中,将随机梯度下降SGD更换成Adam优化器。同时增大迭代次数,将epoch由1改为4
但是数据过强也会影响效果,搞得第二次成功率只有84%,因此要注意数据增强的参数。
vgg_format = transforms.Compose([
transforms.CenterCrop(224),
transforms.ColorJitter(brightness=0.2,contrast=0.2,saturation=0.2,hue=0), #调整亮度、对比度、饱和度、色相
transforms.RandomRotation(5), #随机旋转
transforms.ToTensor(),
normalize,])
optimizer_vgg = torch.optim.Adam(model_vgg_new.classifier[6].parameters(),lr = lr) #使用Adam优化器
但是最终的效果也不理想,准确率为97.5%,与最初相比低了0.1%。鉴于训练一次花费时间有点长,优化行动就先鸽了,以后有机会再搞搞。
--------------------------
更新一下优化方法,让随机旋转的角度从5度降至3度,亮度参数由0.2降至0.1。然后让loader_train的betch_size由64扩大到128,训练迭代次数epoch从4降至2,此外还在VGG模型的nn.Linear(4096, 2)前增加了一个ReLU激活函数。一顿微调之后成功提高了一点成功率,达到了98.2%
总结
本次作业算是完整的学习了一个简单的深度学习项目,对于深度学习模型VGG网络有了更进一步的了解。在学习代码的时候,了解了一些函数的处理功能,对自己实际操作有一定的帮助。但是在尝试优化时,却不太容易得到想要的效果,一方面可能是玄学问题?(误),另一方面就是对一些偏向原理的东西不太了解,不能依此来进行更有效的优化,是以后需要学习提高的地方。


