
第二次作业-肖大智
【第一部分】视频学习心得及问题总结
由神经网络模型创造的价值基本上都是基于监督式学习的。当数据量增大的时候,深度学习模型的效果会逐渐好于传统机器学习算法。现在深度学习如此强大的原因归结为三个因素:Data,Computation,Algorithms。其中,数据量的几何级数增加,加上GPU出现、计算机运算能力的大大提升,使得深度学习能够应用得更加广泛。另外,算法上的创新和改进让深度学习的性能和速度也大大提升。逻辑回归模型一般用来解决二分类问题。二分类就是输出y只有{0,1}两个离散值。逻辑回归问题可以看成是一个简单的神经网络,只包含一个神经元。逻辑回归的损失函数,在设计好网络模型后,w和b都是未知参数,需要反复训练优化得到。因此,我们需要定义一个cost function,包含了参数w和b。通过优化cost function,当cost function取值最小时,得到对应的w和b。对于m个训练样本,我们通常使用上标来表示对应的样本。最小化Cost function,让Cost function尽可能地接近于零。梯度下降算法用来计算出合适的w和b值,从而最小化Cost function。梯度下降算法是先随机选择一组参数w和b值,然后每次迭代的过程中分别沿着w和b的梯度(偏导数)的反方向前进一小步,不断修正w和b。每次迭代更新w和b后,都能让J(w,b)更接近全局最小值。整个神经网络的训练过程实际上包含了两个过程:正向传播和反向传播。正向传播是从输入到输出,由神经网络计算得到预测输出的过程;反向传播是从输出到输入,对参数w和b计算梯度的过程。反向传播算法内容比较复杂。自编码器是一个只有一个隐藏层的神经网络,它先对输入x进行编码,再对编码结果进行解码,我们希望能够得到和输入x非常相似的输出y(最理想情况就是输入和输出完全一样)。则编码所得到的结果就可以看作是该输入数据的特征。对于该目标更新网络参数,从而使其效果达到最优,这就构建了一个自解码器。受限玻尔兹曼机的本质是一种自编码器,它由可视层和隐藏层组成,可视层其实就是输入层,只不过名称不同。可视层和隐藏层之间的神经元采用对称的全连接,而层内的神经元之间没有连接。所有的神经元只有1和0两种状态,分别表示激活和未激活。
问题:1.什么样的数据集适合节点数多的模型?
2.什么样的数据集适合层数多的模型?
3.模型具体是怎么训练的?
4.为什么加了ReLU激活函数之后,准确率大大提高?
【第二部分】代码学习
1.

提示出错,根据提示将v改为float型后成功运行。
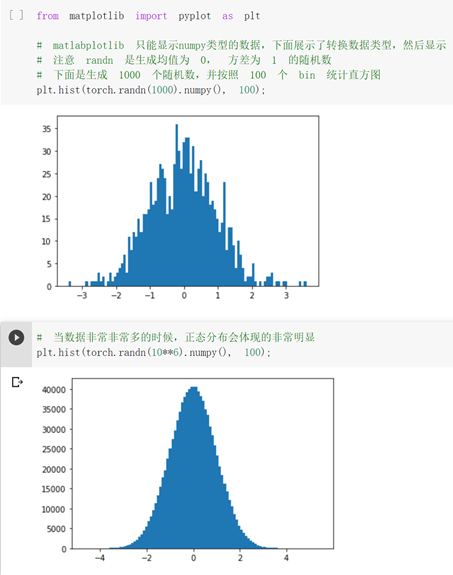
之前用c语言没做过这种可视化的图表,感觉很有意思,很厉害。
2.
2.1

1.不改动
训练模型一:8s
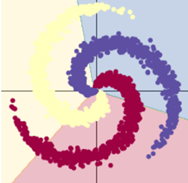
训练模型二:9s
用了 Rule函数的模型训练效果显著提升。
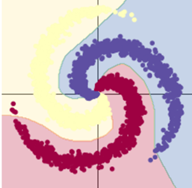
2.样本改为10000
训练模型一:11s

训练模型二:12s
样本点增加,训练结果差别不大。
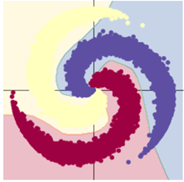
3.隐层节点改为1000
训练模型一:9s
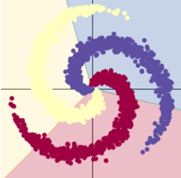
训练模型二:10s
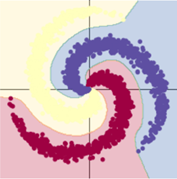
隐层节点增加,用了激活函数的模型效果显著提升;而模型一基本不变。
总结:使用合适的激活函数、增加隐层节点可以提高训练效果。同时会一定程度上增加训练时间。
//样本类别改为7还挺好看的

2.2
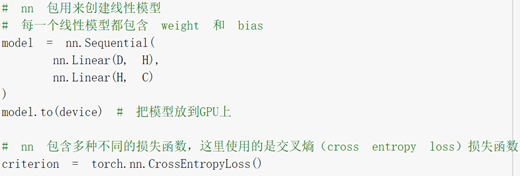
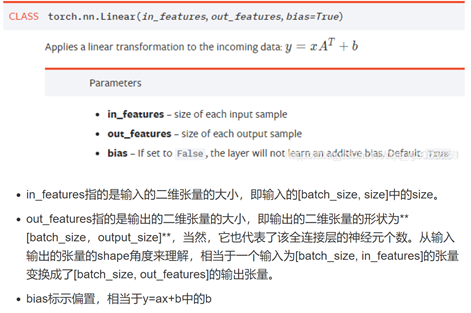
查了nn.linear()参数的意义,还是不理解函数做了什么。
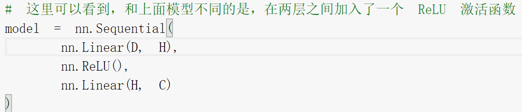
Relu激活函数对训练模型的改善极大。


