pandas笔记
从文件读写数据
- pd.read_csv()
- pd.read_excel()
- read_csv()
- 参数
| 参数 | 说明 |
|---|---|
| path | 文件路径 |
| header | 指定哪一行用作列索引,默认为0,可设置为None |
| index_col | 用作行索引的列编号 |
| skiprows | 需要忽略的行数,默认是0 |
| nrows | 需要读取的行数,从skiprows跳过的开始算起,默认是余下所有 |
从excel读入数据
数据内容包含列索引
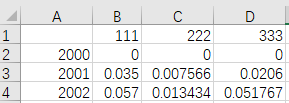
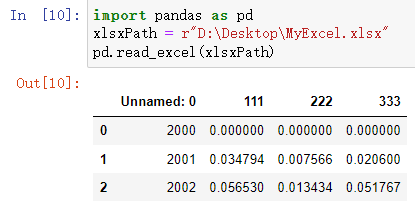
import pandas as pd
excelPath = r"D:\Desktop\MyExcel.xlsx"
pd.read_excel(excelPath)
数据内容不包含列索引
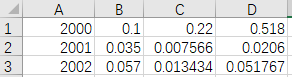
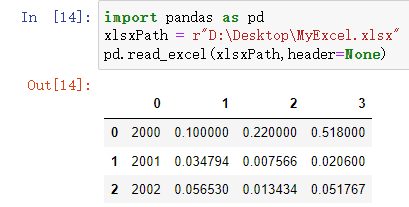
import pandas as pd
xlsxPath = r"D:\Desktop\MyExcel.xlsx"
pd.read_excel(xlsxPath,header=None)
从文本文件中读入数据
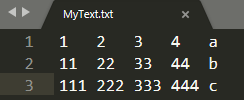
import pandas as pd
xlsxPath = r"D:\Desktop\MyText.txt"
pd.read_csv(xlsxPath,sep = '\t',header = None)

写出到excel或txt
obj.to_csv(path) # 默认写出行与列索引
obj.to_csv(path,sep=',',index=False,header=False) # 不写出行与列索引
python内置数据转为Series
# 列表转换
obj = pd.Series([1 2 3 4])
obj = pd.Series([1, 2 ,3 ,4],index=['1' ,'2', '3', '4'])
obj[['1' ,'2']]
# 字典转换
sdata = {'ddx':1 , 'xmy':2}
obj3 = pd.Series(sdata)
obj3
python内置数据转为DataFrame
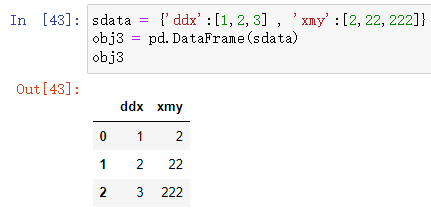
# 字典转换而来
sdata = {'ddx':[1,2,3] , 'xmy':[2,22,222]}
obj3 = pd.DataFrame(sdata)
obj3
数据操作
obj.index=['a','b'] # 改变Series的列索引
obj.head() # 选取前5行
obj.columns # 获取DataFrame的列索引
obj[列索引文本] # 获取DataFrame的某(些)列
del obj[列索引文本] # 删除某列
obj.drop(行标签) # 按行标签删除obj中的行
obj.drop(列标签,axis=1) # 按列标签删除obj中的列
obj.drop(列标签,axis='columns') # 按列标签删除obj中的列
obj.T # 转置
obj.values # 获取获取DataFrame的列索引的文本
obj.reindex(行索引) # 按行索引重构DataFrame,行索引可为列表
切片
Series
obj['a']
obj['a':'cc']
obj['a':]
obj[0:2] # 提取第0到1列
DataFrame
obj['colum1’] # 从DataFrame提取一列
obj['colum1','colum2] # 从DataFrame提取2列
obj[0:2] # 从DataFrame提取0行1行
obj.loc['a',['b',c']] # 通过标签切片,提取'a'行,['b',c']列
obj.loc['a','b':'c'] # 通过标签切片,提取'a'行,'b':'c']列
obj.iloc[:2,1] # 通过数字切片,提取第0,1行,第1列
本文来自博客园,作者:xdd1997
转载请注明:https://www.cnblogs.com/xdd1997/p/15690247.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号