python爬取动态加载的数据
分析网页,查找数据位置
https://item.jd.com/12737107.html,想获取商品价格
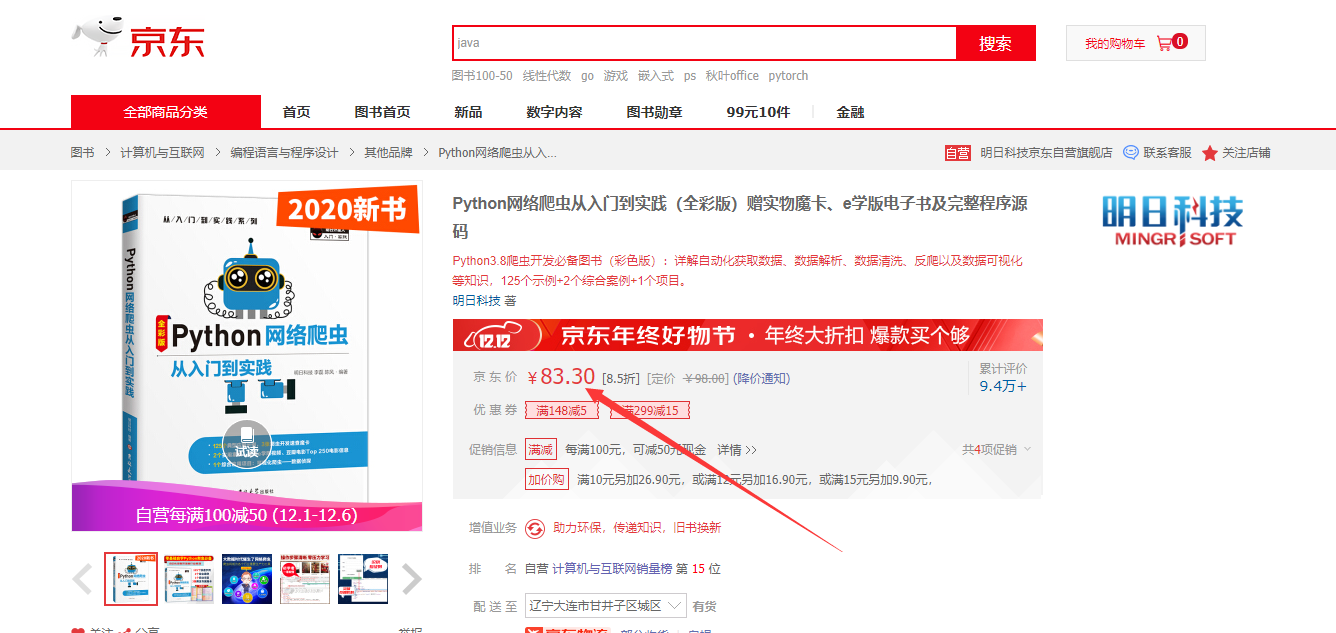
右键---查看网页源代码,Ctrl+F,发现价格信息不在html页面内
右键---检查
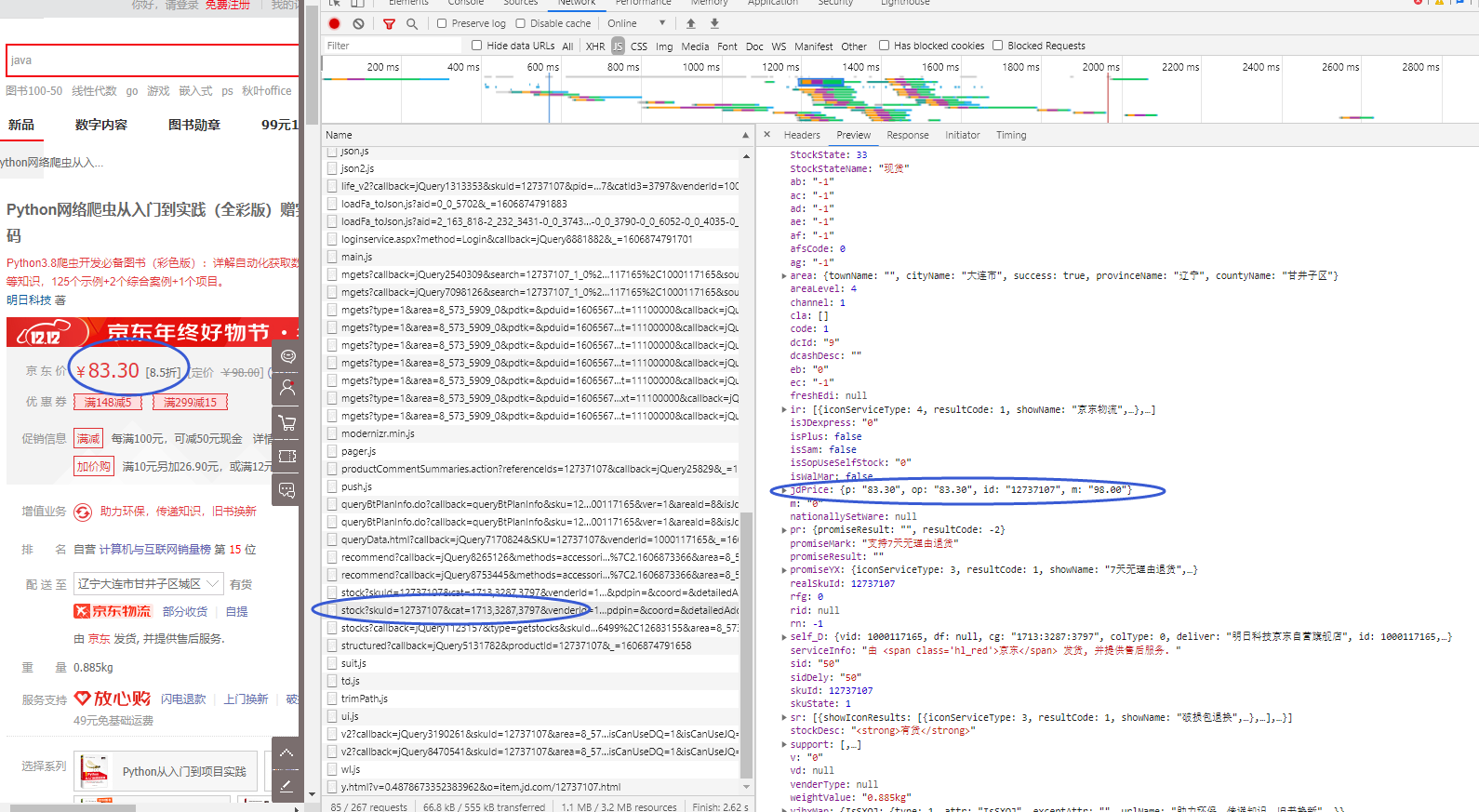
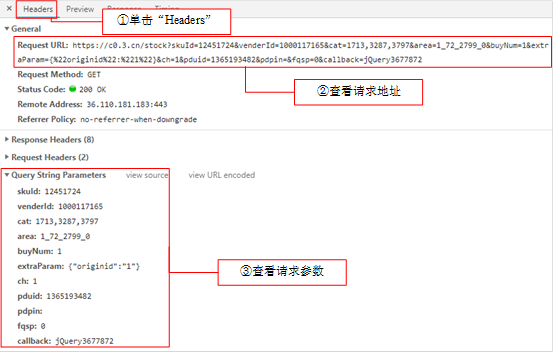
写代码获取数据
注意下面的url与页面中Request URL请求的不一样
原Request URL:

现为:
url = 'https://c0.3.cn/stock?skuId=12737107&cat=1713,3287,3797&venderId=1000117165&area=8_573_5909_0&buyNum=1&choseSuitSkuIds=12752623&'\ 'extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&pduid=1606567201710521294120&pdpin=&coord=&detailedAdd=&'
代码:
import requests # 网络请求模块 # 头部信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'} # 获取商品价格的请求地址,因为callback参数不是必要参数,所以在实现网络请求时可以去除该参数(必须去除) url = 'https://c0.3.cn/stock?skuId=12737107&cat=1713,3287,3797&venderId=1000117165&area=8_573_5909_0&buyNum=1&choseSuitSkuIds=12752623&'\ 'extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&pduid=1606567201710521294120&pdpin=&coord=&detailedAdd=&' # 发送网络请求 re = requests.get(url,headers = header) # 网页header里面有写明是get还是post方法 json = re.json() # 解析json数据 print('当前售价为:',json['stock']['jdPrice']['op']) # 当前售价 print('定价为:',json['stock']['jdPrice']['m']) # 定价
本文来自博客园,作者:xdd1997
转载请注明:https://www.cnblogs.com/xdd1997/p/14072344.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号