Python-beautifulsoup库
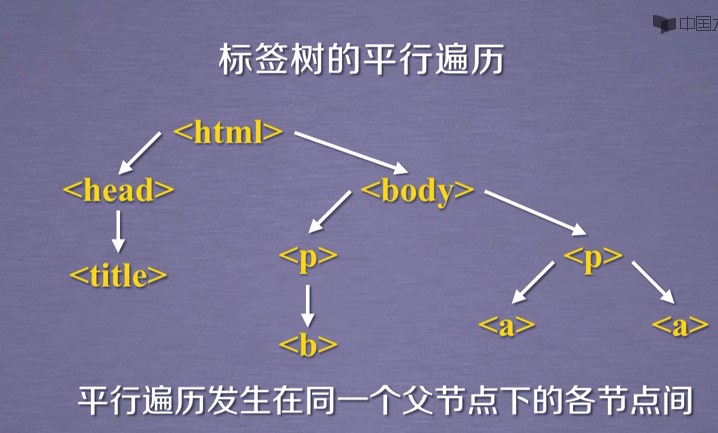
1 #beautifulsoup库的安装 2 pip install beautifulsoup4 3 python -m pip install --upgrage pip 4 from bs4 import BeautifulSoup 5 6 #----------------beautifulsoup库的使用-------------------------------------- 7 import requests 8 from bs4 import BeautifulSoup 9 url = "http://python123.io/ws/demo.html" 10 r = requests.get(url) 11 # print(r.text) 12 demo = r.text 13 soup = BeautifulSoup(demo,"html.parser") #熬一锅`粥 14 #print(soup.prettify()) #打印这锅粥 15 16 #下行遍历函数:.contents() .children()用于循环 .descendants() 17 soup.head #获取head标签 18 soup.head.contents #获取head的子节点,返回类型是列表 19 soup.body.contents # 20 len(soup.body.contents) #terurn 5 21 soup.body.contents[2] 22 print('以下输出子节点:') 23 for child in soup.body.children: 24 print('##',child) 25 print('以下输出子孙节点:') 26 for child in soup.body.descendants: 27 print('**',child) 28 29 #---上行遍历 .parent .parents(用于循环) 30 soup.title.parent #return <head><title>This is a python demo page</title></head> 31 soup.html.parents #返回 html所有内容 32 soup.parent #返回为空 33 print('以下输出父节点:') 34 for par in soup.a.parents: 35 if par is None: 36 print('$$$',par) 37 else: 38 print('%',par.name) 39 40 #----平行遍历---- 41 # 向后.next_sibling 向前.previous_sibling 加 s 用于遍历 42 #title 与 p标签 不构成平行关系 43 soup.a.next_sibling #return ' and ' 所以<a>标签的下一个标签不一定是<a>标签,需要判断 44 soup.a.next_sibling.next_sibling #return <a ...</a> 45 46 soup.a.previous_sibling 47 soup.a.previous_sibling.previous_sibling 48 print('以下输出下行遍历:') 49 for sibling in soup.a.next_siblings: 50 print('##',sibling) 51 print('以下输出上行遍历:') 52 for sibling in soup.a.previous_siblings: 53 print('**',sibling)

本文来自博客园,作者:xdd1997
转载请注明:https://www.cnblogs.com/xdd1997/p/11732724.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号