

前言
第一章主要讲的是hadoop基础知识。老师讲的还是比较全面简单的,起码作为一个非专业码农以及数据库管理人员,也能狗大致了解其特点
首先是概括图(以hadoop2.0为例) 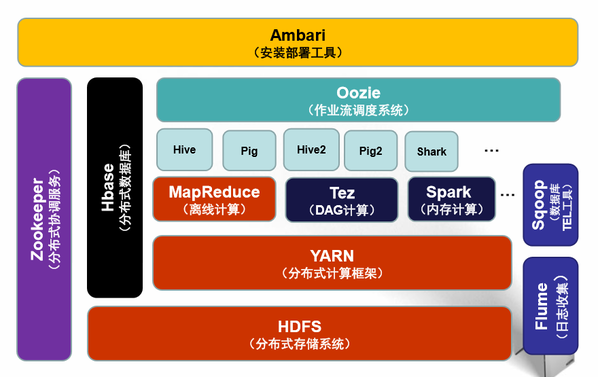
一、Hadoop基础架构:
HDFS(分布式存储层,主要储存数据)
YARN(集群资源管理层)
MapReduce 分布式数据处理,java
HDFS为最基本的,分布式文件系统
Redundant, Reliable Storage
它可扩展性好,资源不够时再买服务器就可以直接集成了。另外数据重分布也很方便,对服务器崩溃等等处理也及时。
其会把如1G等大文件,会冗余均等储存在多个服务器上(即使一个服务器崩溃了也无所谓),其过程均在后台处理而用户体验不到。
YARN负责集群管理调度
Cluster Resource Management
它兼容多个计算框架(spark/mapreduce等等),可以统一管理调度多个应用程序
另外,对多用户管理方便(可以方便分配用户资源等等)
基本是数据库管理者调度资源等用的
MapReduce是计算框架的一种
依然方便扩展,适合数据离线处理
里面涉及几个框架图,有空看看这些框架图可以更了解他们的架构与应用原理。
二、Hadoop具体模块解析(应用层)
Hadoop1.0
Hive 数据仓库 与sql整合
Pig 流行引擎
Mahout 数据挖掘库
–>Oozie 可以调度上述三种作业,先后处理什么作业,设定执行作业
–>Hbase 构建了hdfs之上的分布式数据库
–>数据引用 flume sqoop
协调服务zookeeper
Hadoop2.0
增加了YARN(计算框架)
预装了新一代软件 hive2 pig2等等
Hive: 日志数据处理,数据仓库
可以把sql语句转化为MapReduce语句
与数据库进行接口,作为一个类似于SQL的查询语言,使我们不用直接编写程序调用HDFS数据
它一般用于离线数据处理,而不是交互性数据处理。
一般用于:
1)日志分析(如pv uv):百度、淘宝
2)多维度数据分析
3)海量结构化数据李贤分析
4)低成本进行海量数据分析,不用专门学习MapReduce(简称MR)
Pig: 数据流语言,也是基于MapReduce
sql表达能力过于有限,不够直观。因此对于adhoc的数据分析不够。定义了新的pig Latin语言
也是用于离线数据分析
(PPT里对比了单词分组的MapReduce/hive/pig的案例)
感觉pig更像一个对象式编程,还可以自编写函数。而hive结构型数据处理转换成本更低(sql),大公司还是在用它居多
Mahout: 提供数据挖掘库
包括推荐、聚类、分类三大算法。
反正常用的数据挖掘算法都有了。
HBase:分布式数据库
有表的概念
但是Hbase会有版本、时间戳概念,就是如果新数据进来插入,不会覆盖原来的cell,而是储存在时间戳里(每一行数据)通过版本号数量限制可限定储存的版本数
另外有column family,可以由任意column组成(适合变量)
Zookeeper:用于解决分布式环境下数据管理问题
用户不会直接使用这个系统,而是底层系统用zookeeper解决资源配置问题,包括HDFS/HBase/YARN等
阿里巴巴也开发了使用Zookeeper,Dubbo/Metaq
Sqoop:数据同步工具
就是把Hadoop跟传统mysql,db2等数据库结合
属于基于MapReduce的一个程序
Flume:日志收集系统
与Sqoop类似,用于把日志导入hadoop里面
可以把网站使用的数据统一加载到HDFS里(加载基于Flume的客户端)agent-collector-HDFS
涉及客户端内容。(ATM采集信息等集群)
Oozie:用于调度不同的作业之间的管理与调度
对于有前后关系的、需要周期性定期性执行的工具进行调度甚至监控报警(邮件、短信报警)
本文来自博客园,作者:茄子_2008,转载请注明原文链接:https://www.cnblogs.com/xd502djj/p/5227033.html

