

做作业的过程中发现,把一节点停掉,dfsadmin和50070都无法马上感知到一个data node已经死掉
HDFS默认的超时时间为10分钟+30秒。
这里暂且定义超时时间为timeout
计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
参考 http://f.dataguru.cn/thread-128378-1-1.html
--------------------------
Linux环境:CentOs6.4
Hadoop版本:Hadoop-1.1.2
master: 192.168.1.241 NameNode JobTracker DataNode TaskTracker
slave:192.168.1.242 DataNode TaskTracker
内容:设置DataNode的心跳,当某一个节点失去连接之后,在超过设置的时间,看hadoop能否正常工作。
设置时间:
<property>
<name>heartbeat.recheck.interval</name>
<value>15</value>
</property>
第一步: 配置hdfs-site.xml
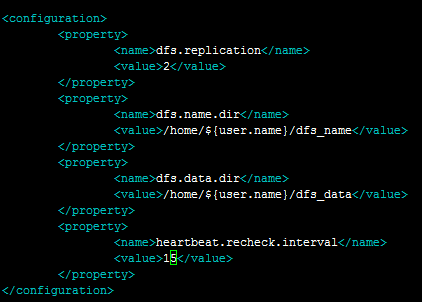
第二步:重启Hadoop
第三步:通过网页浏览两个节点的状态。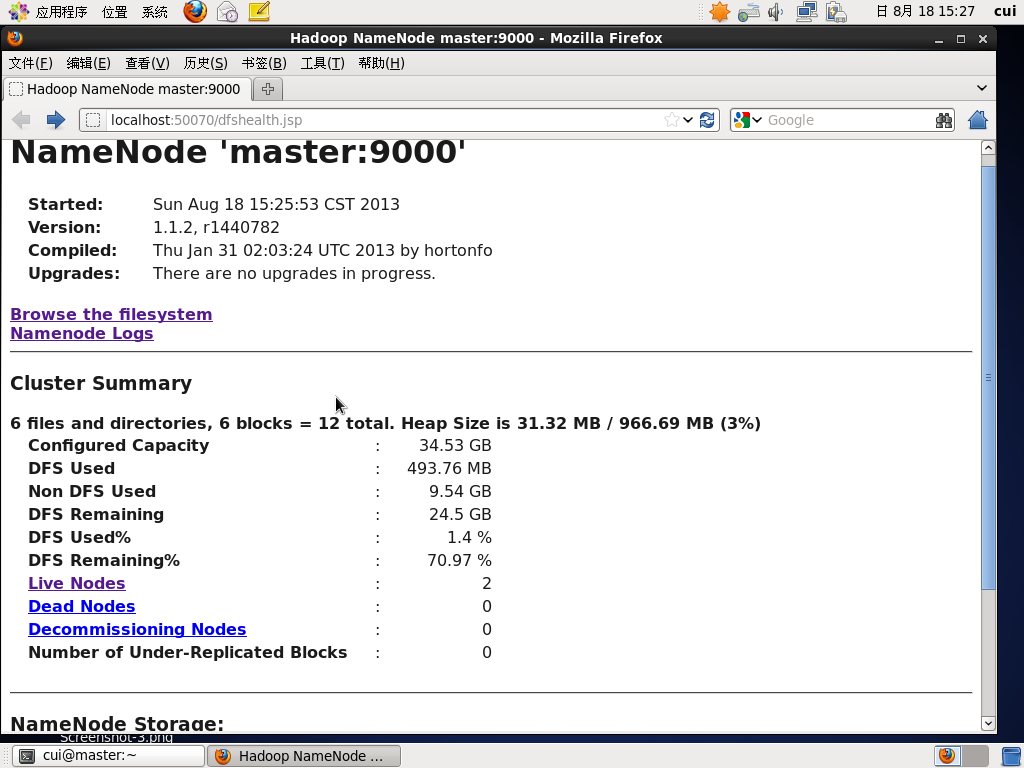
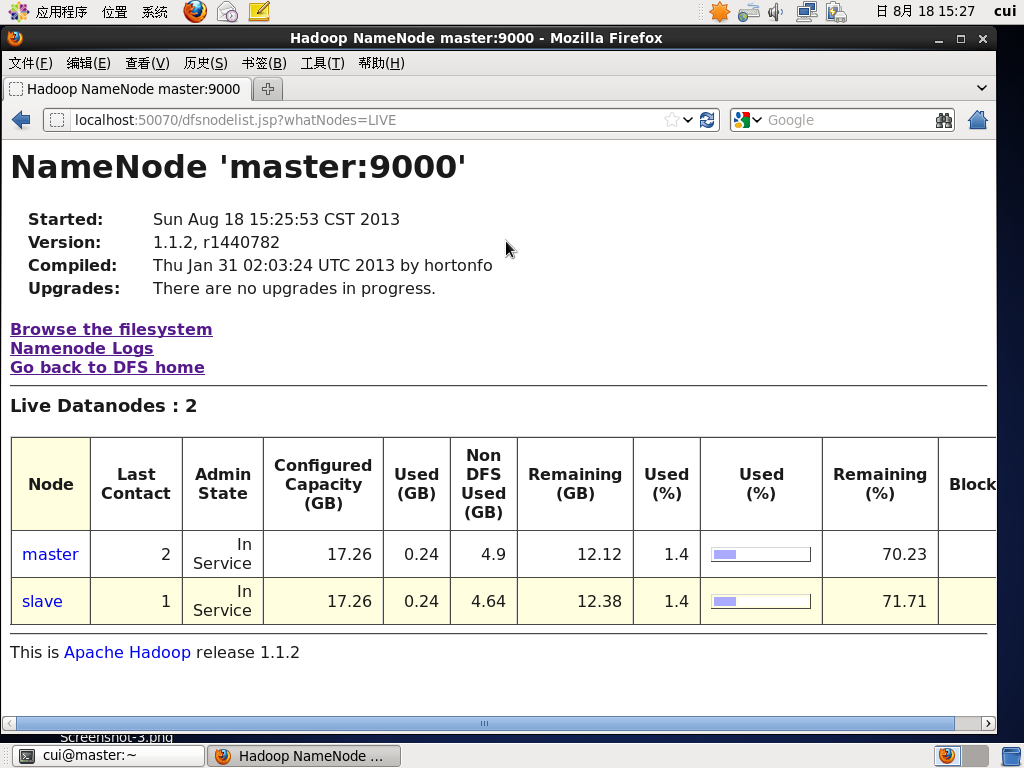
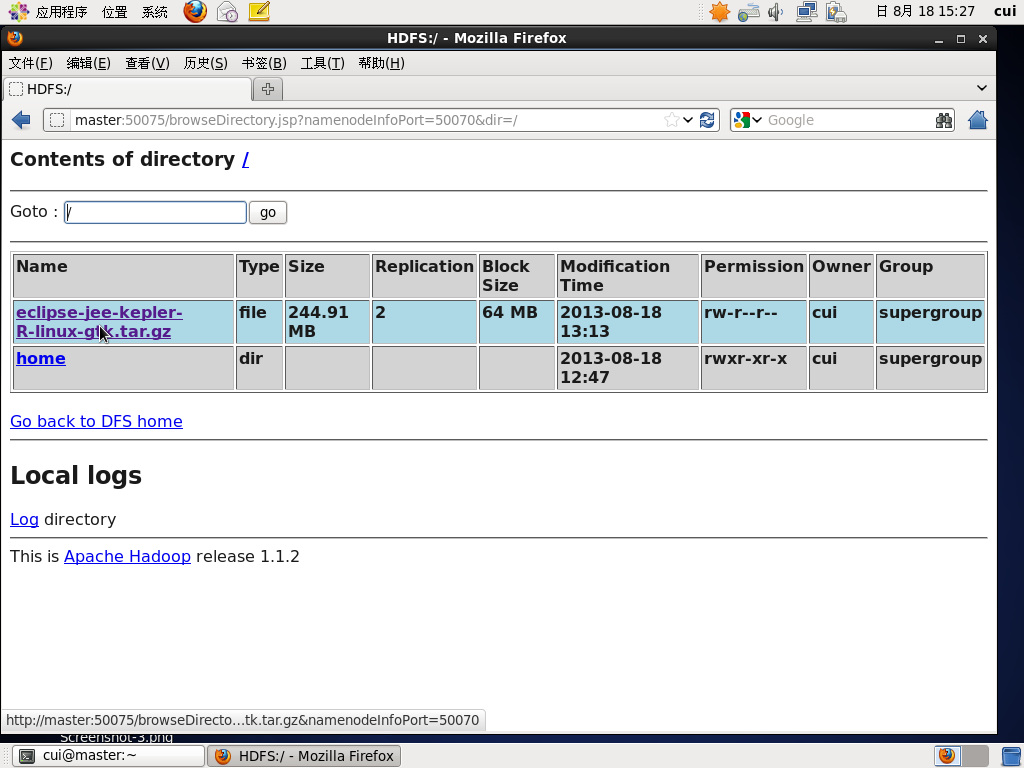
hadoop两个节点都已正常运行。
第三步:杀死主节点的进程,等待15秒。
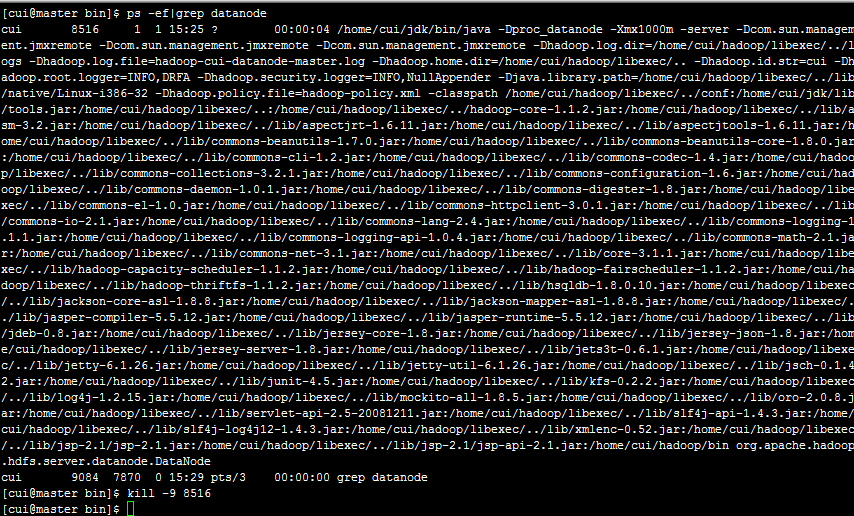
通过kill命令杀死master上的DataNode节点。
第四步:查看节点状态
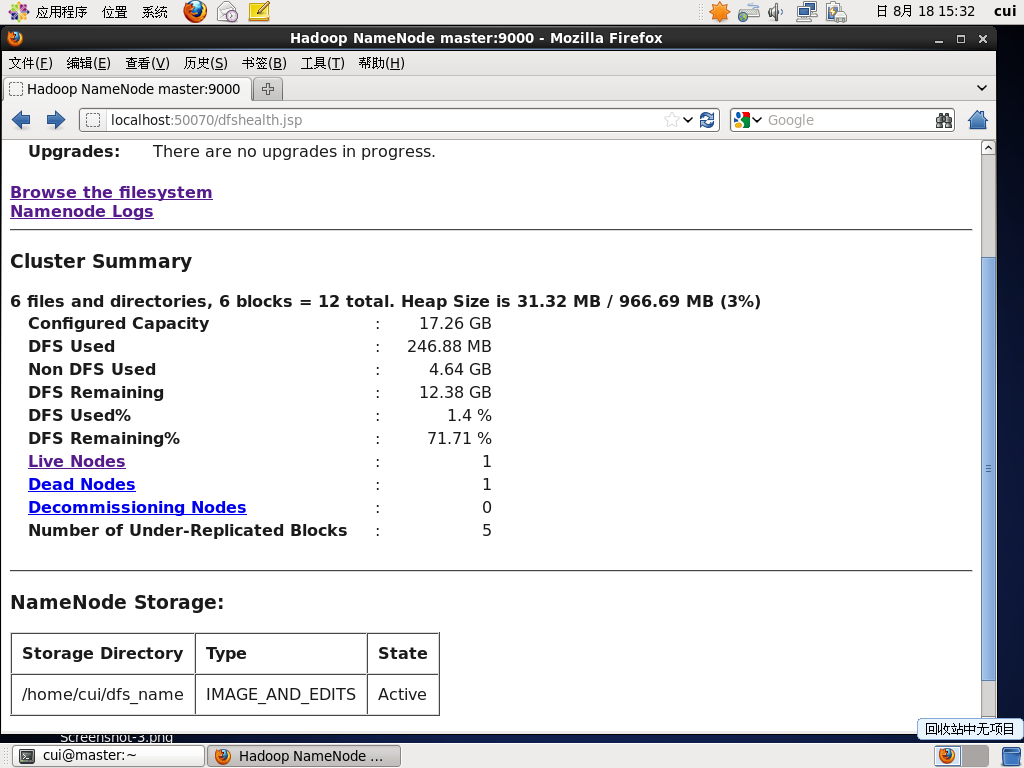
活着的DataNode还有1个,死亡的DataNode一个
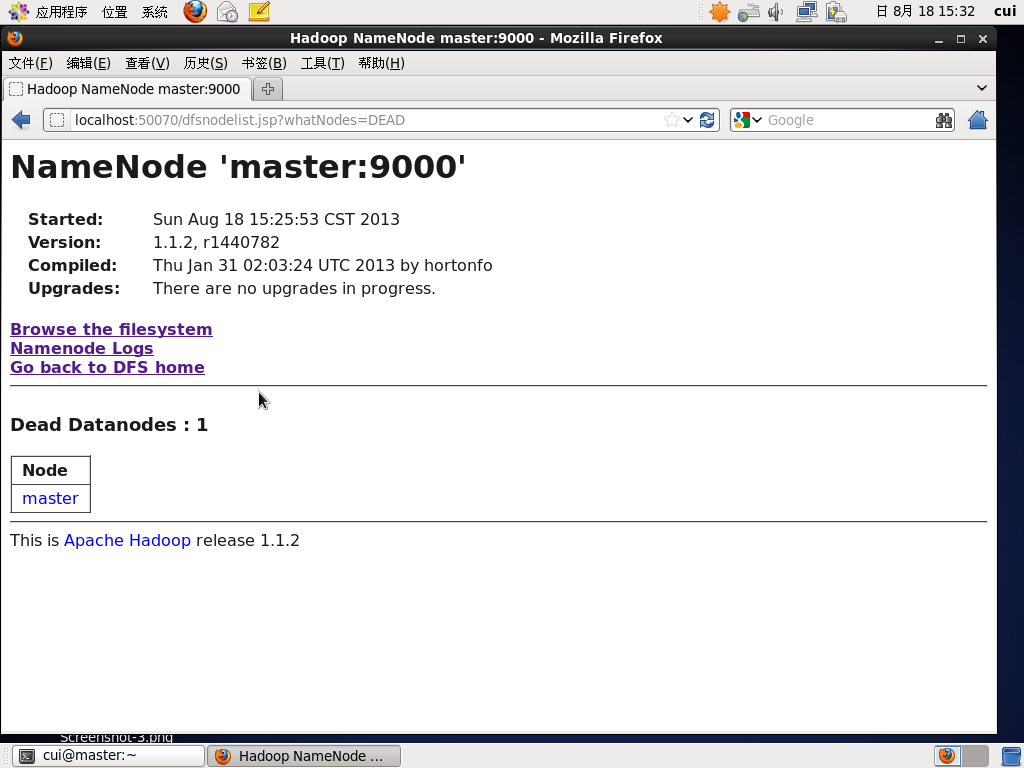
master上的DataNode节点已经标识为Dead

只剩下slave节点,其最后连接时间是2秒(Last Contact 2)
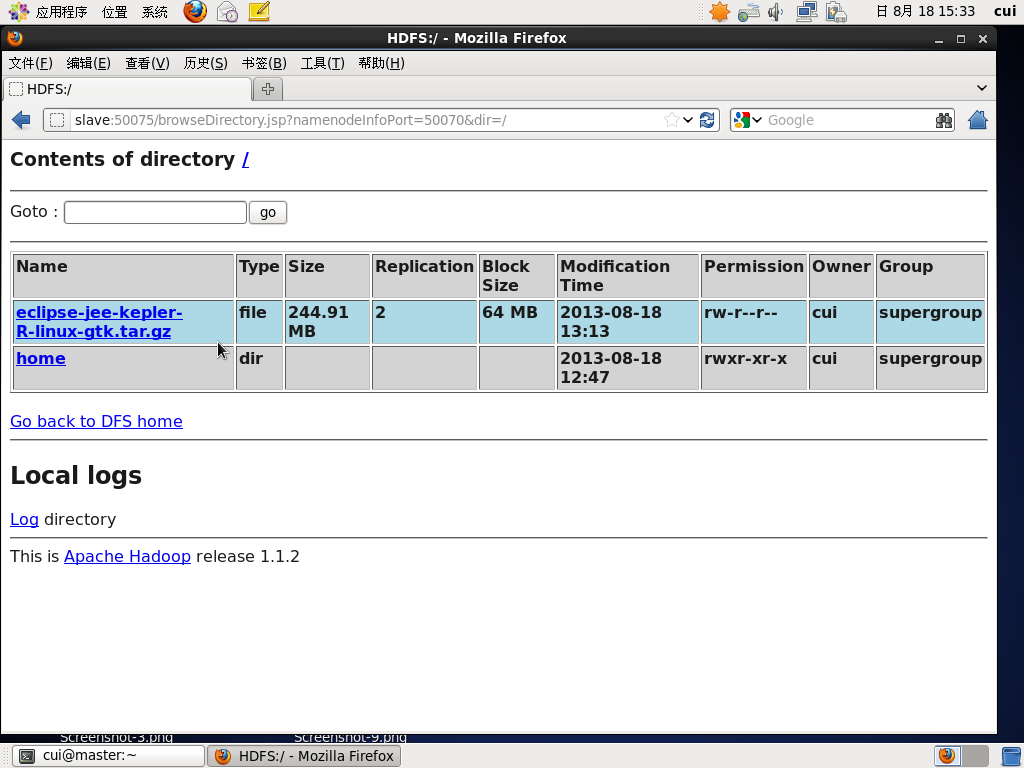
杀死一个节点,两一个节点仍能够正常查看文件信息。

只有slave节点在运行。
本文来自博客园,作者:茄子_2008,转载请注明原文链接:https://www.cnblogs.com/xd502djj/p/4645298.html

