
SQL之留存率的题目
关于留存率的SQL语句,之前看到猴子分析那里给过一个思路,是用timestampdiff函数来求,而且有一个模板,可以统一求次日留存率、三日留存率、七日留存率之类的,但是在牛客网刷题也遇到一些留存率分析的题目,发现试图套模板出了问题,因此这里梳理总结一下思路。
先看数据如下:表:login,字段分别有id、user_id、client_id、date,分别表示序号、用户id、设备号、登录日期
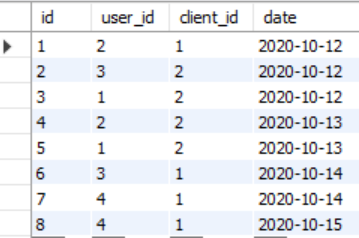
然后要求输出格式如下:

一、猴子分析的求留存率思路:
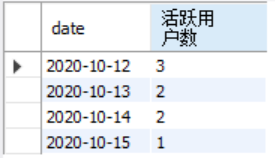
1.求出每天的活跃用户数:
select date,count(distinct user_id) as 活跃用户数 from login group by date
显示结果如下:
2.求出次日留存数:
利用自联结【一个表如果涉及到时间间隔,就需要用到自联结,也就是将两个相同的表进行联结】,将两个表连起来,使用timestampdiff(unit,begin,end)求出时间间隔,然后用case when 计算出时间间隔=1的用户数量,即次日留存数。
注意:这里猴子分析的表述有点歧义,真正的自联结,应该是给同一张表起别名,比如loign as a,login as b,然后再在where里面加条件,但其实猴子分析这里提供的连接是用的外连接里的左连接 left join,将同一张表起别名连接起来。
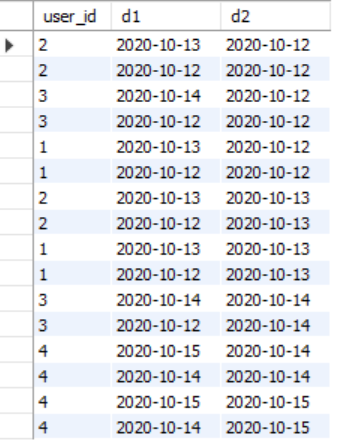
自连结:
select a.user_id,a.date as d1,b.date as d2 from login as a,login as b where a.user_id = b.user_id
左连接:
select a.user_id,a.date as d1,b.date as d2 from login as a left join login as b on a.user_id = b.user_id

可以看出来查出来结果除了顺序有点不一样以外,其余内容本质上是一样的。
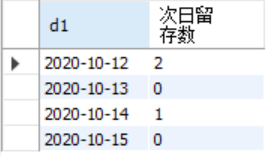
然后使用timestampdiff(unit,begin,end)求出时间间隔,然后用case when 计算出时间间隔=1的用户数量,即次日留存数。
select d1,count(distinct case when day_diff = 1 then user_id else null end) as 次日留存数
from(select *,timestampdiff(day,d1,d2) as day_diff from( select a.user_id,a.date as d1,b.date as d2 from login as a left join login as b on a.user_id = b.user_id) as c) as d group by d1
3.求出次日留存率
留存率 = 新增用户中登录用户数/新增用户数,所以次日留存率 = 次日留存用户数/当日用户活跃数
这是猴子分析中给出的公式,注意是有问题的,具体问题下面会说!
当日活跃用户数是count(disctinct 用户id),在上面分析次日留存数中,用次日留存用户数/当日用户活跃数就是次日留存率
select d1,count(distinct case when day_diff = 1 then user_id else null end) as 次日留存数, count(distinct case when day_diff = 1 then user_id else null end)/count(distinct user_id) as 次日留存率 from(select *,timestampdiff(day,d1,d2) as day_diff from( select a.user_id,a.date as d1,b.date as d2 from login as a,login as b where a.user_id = b.user_id) as c) as d group by d1

但这个结果跟牛客网给出的答案是不符合的!因为2020-10-14号这天的次日留存率标准答案应该是1!这个问题就在于猴子分析给出的次日留存率公式是有问题的!次日留存率应该是次日留存用户数/当日新增用户数,重点就是分母应该是新增用户数,而不是猴子分析里给出的活跃用户数!这种算法会把老用户也算进去,如果仔细观察原始数据表login就会知道,2020-10-14号登录的用户有两个,分别是user_id为3和user_id为4的,但2020-10-15号登录的用户只有user_id为4的用户了,所以按照猴子分析的算法2020-10-14号这天的次日留存率会是0.5。但实际上user_id为3的用户早在2020-10-12就登录了,所以他根本不能被算在2020-10-14的新增用户里,他只是一个老用户!!!
所以想真正的计算出每个日期新用户的次日留存率必须要计算出两张表,一张是每天的新用户表,一张是每天的留存用户表!下面给出牛客网的大神的解题思路:
二、牛客大神的统计新用户留存率思路:
以集合的思想来理解,以date对整体进行划分,划分为之后每个集合里需要包括每个date的新用户数,每个date的留存用户数,这两部分相除组成留存率
select date,xxx from group by date
基于此进一步完善我们想要的框架:
select c.date,round( count(d.user_id)/count(),3)as p from(每天的新用户表) as c left join(每天的留存用户表) as d on c.user_id = d.user_id group by c.date
接下来再分别写一个新用户表和留存用户表,完了塞进上述结构里去:
新用户表,别名c
select a.date,b.user_id from (select distinct l1.date from login l1) as a left join (select l2.user_id,min(l2.date) as f_date from login l2 group by l2.user_id) as b on a.date = b.f_date
表a:【表a存在的目的是为了把所有日期展示出来,否则只会有出现新用户登录的12和14号,13号和15号就被遗漏了】
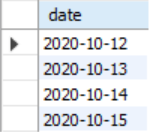
表b:

最终查出来的每天的新用户表(别名c)如下:
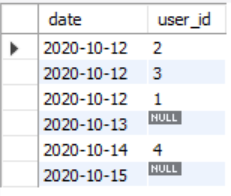
留存用户表,别名d【留存用户表因为涉及到时间间隔=1的问题,所以用之前猴子分析中提到的两表连接最简单了(自连结左连接都行)】
select distinct l3.user_id from login l3,login l4 where l3.user_id =l4.user_id and date_add(l3.date,interval 1 day)=l4.date #这里换成 and timestampdiff(day,l3.date,l4.date)=1 一样的效果
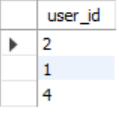
最后将新用户表c和留存用户表d连接起来,以新用户表c为主表,左连接留存用户表d:

select * from(select a.date,b.user_id from (select distinct l1.date from login as l1) as a left join (select user_id,min(date) as m_date from login as l2 group by user_id) as b on a.date = b.m_date) as c left join(select distinct l3.user_id from login l3,login l4 where l3.user_id =l4.user_id and date_add(l3.date,interval 1 day)=l4.date) as d on c.user_id = d.user_id
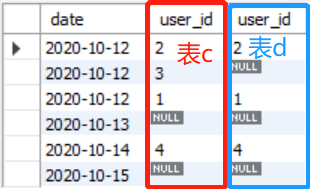
然后塞进一开始的框架里,组成完整的SQL查询语句:
select date,round(count(distinct d.user_id)/count(distinct c.user_id),3) as p from(select a.date,b.user_id from (select distinct l1.date from login as l1) as a left join (select user_id,min(date) as m_date from login as l2 group by user_id) as b on a.date = b.m_date) as c left join(select distinct l3.user_id from login l3,login l4 where l3.user_id =l4.user_id and date_add(l3.date,interval 1 day)=l4.date) as d on c.user_id = d.user_id group by date
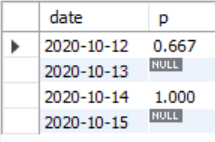
如果要求结果一定要显示为0而不是NULL的话,可以再加一个ifnull()函数,把NULL替换成0

select date,ifnull(round(count(distinct d.user_id)/count(distinct c.user_id),3),0)as p


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人