
SQL中GROUP BY 默认取非聚合的第一条记录
GROUP BY 分组中的坑
1.分组后select后的字段只能有以下两种:
- 出现在group by 后面的字段
- 使用聚合函数的列
2.group by 默认取非聚合的第一条记录
例题:牛客网数据库实战之获取所有部门中当前员工薪水最高的相关信息
表:dept_emp
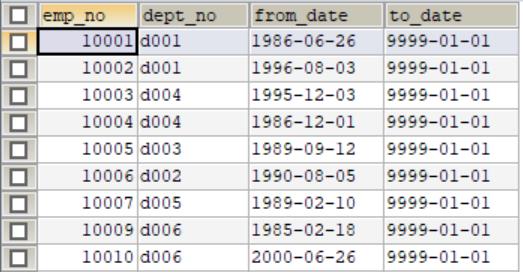
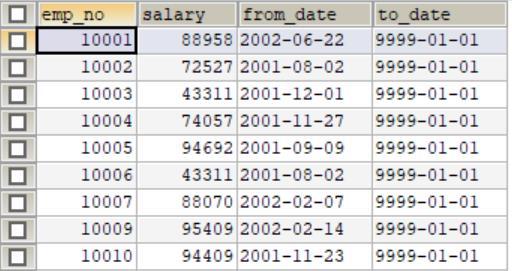
表:salaries
错误的解题方法:
1 select e.dept_no,e.emp_no,max(salary) as maxSalary 2 from dept_emp e 3 inner join salaries s on e.emp_no = s.emp_no 4 group by dept_no 5 order by dept_no
其中e.emp_no既不是group by后面的字段,也不是使用聚合函数的列,emp_no是非聚合字段,不能出现在SELECT。因为一个聚合字段(dept_no)对应多个非聚合字段(emp_no),所以选择的时候,会默认选择非聚合字段中的第一个,于是出错。
显示错误的结果:
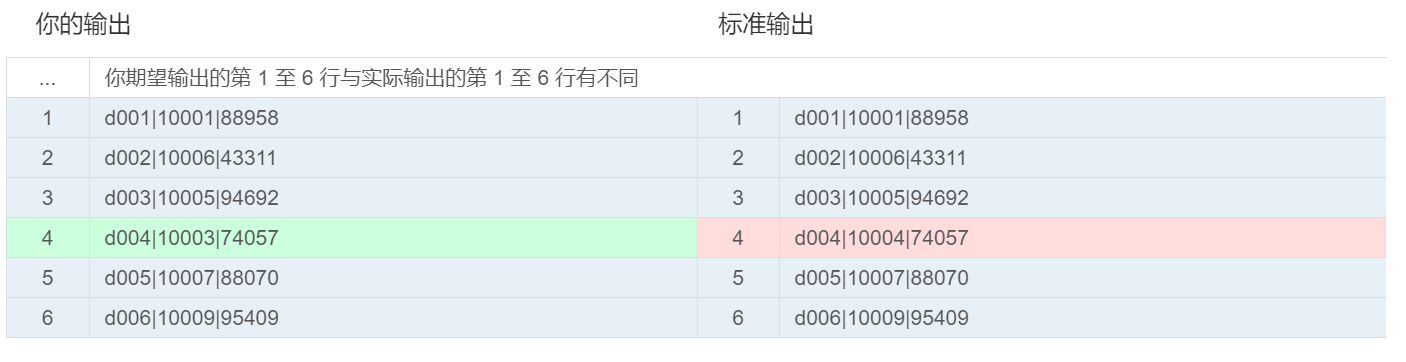
因为group by默认取非聚合的第一条记录,部门d004有两个员工,分别是1003,1004,由于select后面跟的emp_no既不是group by后面的字段,也不是使用聚合函数的列,因此默认选取了1003,而不是真实的数据1004!!!
正确的解题方法:

SELECT de.`dept_no`,de.`emp_no`,s.`salary` FROM dept_emp de JOIN salaries s ON de.`emp_no` = s.`emp_no` AND de.`to_date` = '9999-01-01' AND s.`to_date` = '9999-01-01' WHERE s.`salary`=( SELECT MAX(salary) FROM dept_emp de2 JOIN salaries s2 ON de2.`emp_no` = s2.`emp_no` AND de2.`to_date` = '9999-01-01' AND s2.`to_date` = '9999-01-01' WHERE de.`dept_no` =de2.`dept_no` GROUP BY de2.`dept_no` ) ORDER BY dept_no
注意: 关于为什么一定要两个表格的时间都限制成规定时间(9999-01-01)
因为薪水表是按年发的,而题目要查找的当前的薪水,所以要过滤掉以前的阶段。即一个领导从入职到现在阶段不同,薪水不同,所以to_date为最新,表示最新的薪水


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人