
kettle
kettle:可以把不同数据库的数据通过kettle以一种指定的格式输出,一般是输出到数据库中。
1、转换(transformation):完成针对数据的基础转换
2、作业(job):完成整个工作流的控制
kettle的概念模型:
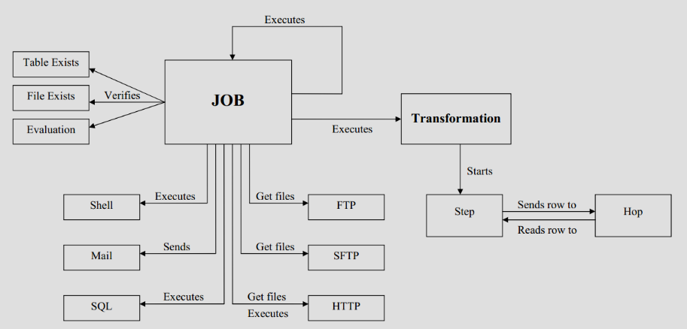
可视化编程:
step(步骤,控件):是转换里的基本组成单位
特性:
1、步骤需要一个名字,这个名字在转换范围内唯一。
2、每一个步骤都会读、写数据行(唯一的例外是“生成记录”步骤,该步骤只写数据)
3、步骤将数据写到与之相连的一个或者多个输出hop(节点连接),再传送到hop的另一端的步骤。
4、大多数的步骤都可以有多个输出hop,一个步骤的数据发送可以被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有记录被同时发送到所有的目标步骤。
hop(节点连接):步骤之间的带箭头的连线,定义了步骤之间的数据通道;实际上是俩个步骤之间的被称之为行集的数据行缓存(行集的大小可以在转换的设置里定义)
行集大小设置:在编辑 -> 设置 -> 杂项 -> 记录集合里的记录数;
数据行:数据已数据行的形式沿着步骤移动,一个数据行是零到多个字段的集合。
数据类型:
1、String:字符类型数据
2、Number:双精度浮点数
3、Integer:带符号长整型(64位)
4、BigNumber:任意精度数据
5、Date:带毫秒精度的日期时间值
6、Boolean:取值为TRUE和False的布尔值
7、Binary:二进制字段可以包含图像、声音、视频以及其他类型的二进制数据
8、Timestamp:时间戳
9、Internet Address:
元数据:每一个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据
1、名称:行里的字段名应用是唯一的,字段名
2、数据类型:字段的数据类型
3、格式:数据显示的方式,如Integer的#、0.00
4、长度:字符串的长度会在BigNumber类型的长度
5、精度:BigNumber数据类型的十进制精度
6、货币符号:¥
7、小数点符号:十进制的小数点格式 ;‘.’
8、分组符号:数值类型数据的分组符号;‘,’
9、去掉空格形式:不去、去左、去右、去俩边
并行:hop的这种基于行集缓存的规则允许每一个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流方式来处理。在数据仓库里,我们经常要处理大量的数据,所以这种并发低消耗内存的方式也是ETL工具的核心需求。
转换是不可能定义一个执行顺序的,因为所以的步骤都是并发进行的。
如果你想要一个任务沿着指定的顺序执行,那么就要使用job(作业)
shuc
合并多文件输入(即匹配多个文件):文件目录 + 正则匹配
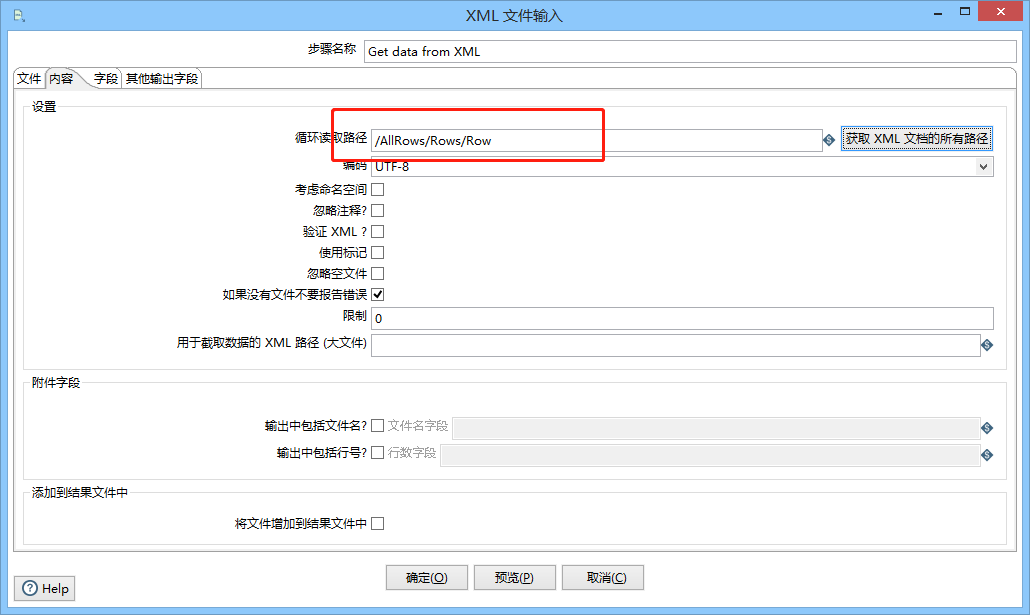
xml文件输入:
输入按钮位置:input -> Get data from XML
内容设置:
循环读取路径:当前位置
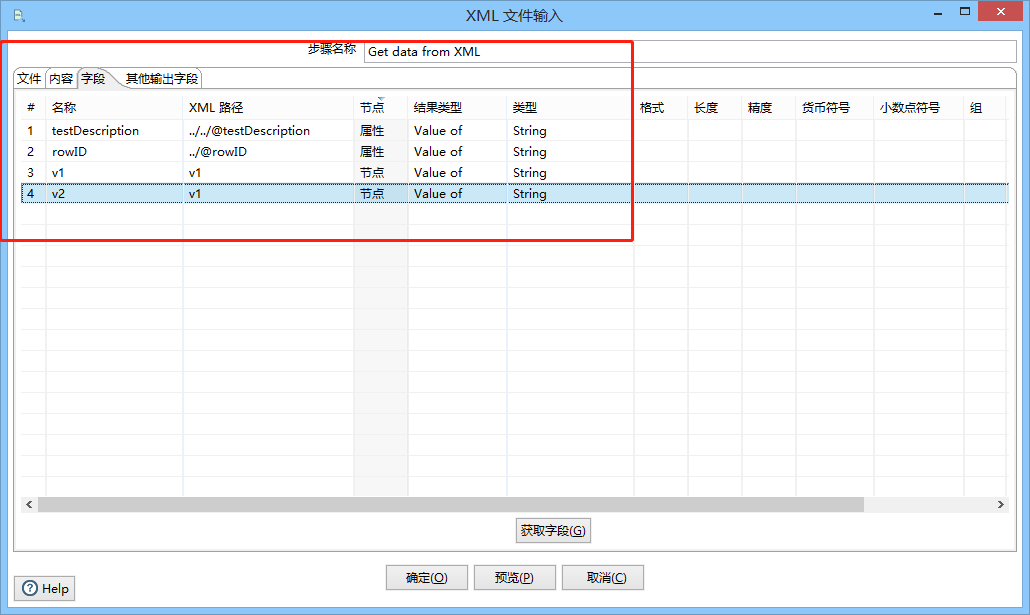
字段设置:
名称、填写XML路径、节点、结果类型、数据类型
<?xml version="1.0" encoding="UTF-8"?> <AllRows testDescription="1 - simple functionality test"> <Rows rowID="1">first row chunk of data <Row><v1>1.1.1</v1><v2>1.1.2</v2></Row> <Row><v1>1.2.1</v1><v2>1.2.2</v2></Row> </Rows> <Rows rowID="2">second row chunk of data <Row><v1>2.1.1</v1><v2>2.1.2</v2></Row> <Row><v1>2.2.1</v1><v2>2.2.2</v2></Row> </Rows> <Rows rowID="3">third row chunk of data <Row><v1>3.1.1</v1><v2>3.1.2</v2></Row> <Row><v1>3.2.1</v1><v2>3.2.2</v2></Row> </Rows> </AllRows>
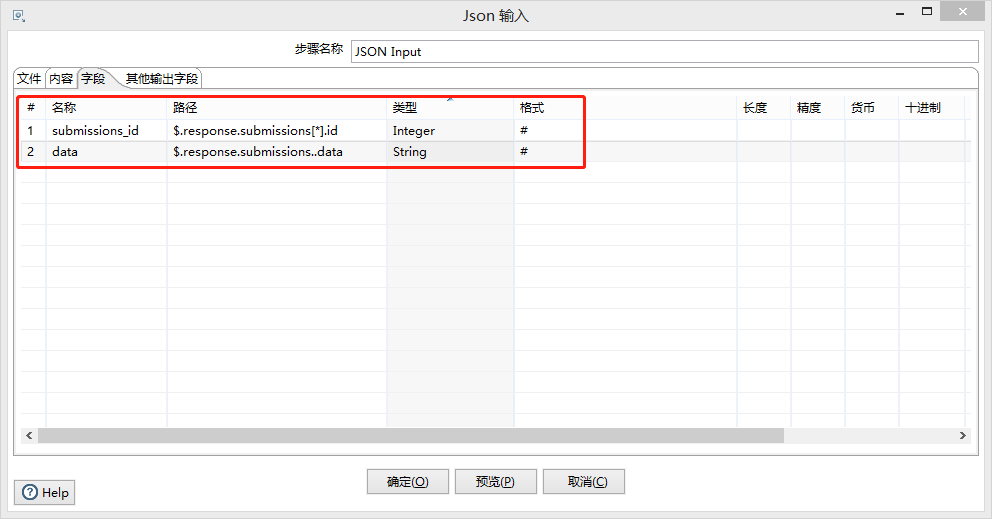
JSON输入:
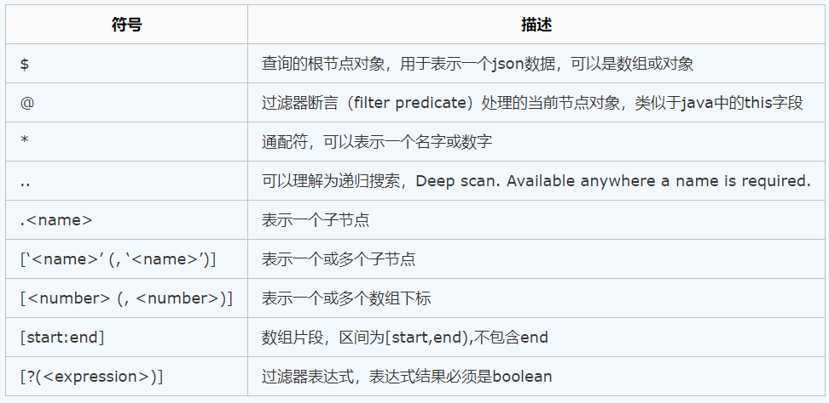
JsonPath:类似于Xpath在XML文档中的定位,JsonPath表达式通常用来路径的检索或者设置Json的
点记法:$.store.book[0].title
JsonPath操作符:
..:当前节点下的所有符合的条件
输入按钮位置:input -> JSON Input
字段设置:
名称、路径(JsonXpath)、数据类型、格式


{ "status": "ok", "response": { "submissions": [ { "id": "59434767", "timestamp": "2011-11-21 09:21:53", "user_agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:8.0) Gecko/20100101 Firefox/8.0", "remote_addr": "192.168.1.1", "payment_status": "", "data": [ { "field": "13776121", "value": "Baylor Dallas" }, { "field": "13776401", "value": "CHF" }, { "field": "13777966", "value": "John Doe" }, { "field": "13780027", "value": "9999" }, { "field": "13778165", "value": "None of the above" }, { "field": "13778985", "value": "Yes" }, { "field": "13778280", "value": "Yes" }, { "field": "13778424", "value": "Yes" }, { "field": "13778290", "value": "Yes" }, { "field": "13778324", "value": "Yes" }, { "field": "13778864", "value": "Yes" } ] }, { "id": "59474875", "timestamp": "2011-11-21 17:01:22", "user_agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:8.0) Gecko/20100101 Firefox/8.0", "remote_addr": "192.168.1.1", "payment_status": "", "data": [ { "field": "13776121", "value": "Healthsouth," }, { "field": "13776401", "value": "Pneumonia" }, { "field": "13777966", "value": "Jane Doe" }, { "field": "13780027", "value": "390" }, { "field": "13778165", "value": "Experienced a fall?" }, { "field": "13861153", "value": "Yes" }, { "field": "13780018", "value": "Yes" }, { "field": "13780006", "value": "No" }, { "field": "13780023", "value": "Yes" }, { "field": "13780024", "value": "Yes" } ] } ], "total": 2, "pages": 1 } }
生成记录:自动生成常量数据
限制:生成记录的条数
字段:名称、类型、值
自定义常量数据:就是生成key-value形式的常量数据
输出控件:
更新:就是把数据库已经存在的记录与数据流里面的记录进行对比,如果不同就进行更新。
注意(需要确保字段一一对应):如果记录不存在则会报错;需要勾选“忽略查询失败”的选项。
用来查询值的关键词:表字段,比较符(=、>、<、is null等等),流里的字段1、流里的字段2
更新字段(可字段更新字段):表字段、流里的字段
插入更新:就是把数据库已经存在的记录与数据流里面的记录进行对比,如果不同则进行更新,如果记录不存在则插入数据
用来查询值的关键词:表字段,比较符(=、>、<、is null等等),流里的字段1、流里的字段2
更新字段(可字段更新字段):表字段、流里的字段
删除:就是删除数据库表中指定条件的数据(删除一行数据)
查询值所需的关键字:表字段,比较符(=、>、<、is null等等),流里的字段1、流里的字段2
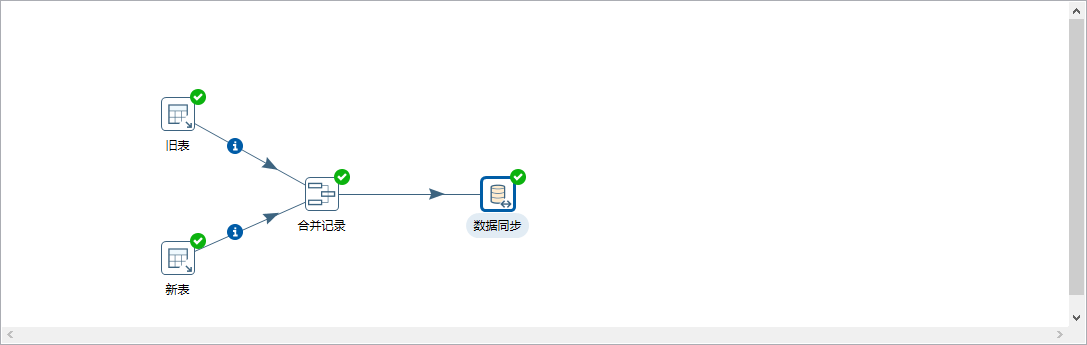
同步数据:需要通过合并记录来实现,旧表是原来的数据即需要被同步的数据;旧表是新进来的数据即同步的数据。
注意:
1、旧表和新表需要对字段进行排序来保证数据顺序的一致性
2、合并记录中匹配的关键字是判断的字段(即主键),数据字段是需要同步的数据。
3、数据同步中更新字段需要把flagfield字段删除
4、数据同步中高级选项中:
操作字段名:flagfield
当值相同时插入:new
当值相等时更新:changed
当值相等时删除:deleted
合并记录的原理:
新增了一个标志字段:
1、“identical” – 旧数据和新数据一样
2、“changed” – 数据发生了变化;
3、“new” – 新数据中有而旧数据中没有的记录
4、“deleted” –旧数据中有而新数据中没有的记录
作业:大多数ETL项目都需要完成各种各样的维护工作,例如如何传送文件,验证数据库表是否存在等等。而这些操作都是按照一定的顺序完成的。因为转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。一个作业包含一个或者多个作业项,这些作业项以某种顺序来执行。作业的执行顺序由作业项之间的hop和每一个作业项的执行结果来决定。
作业项:
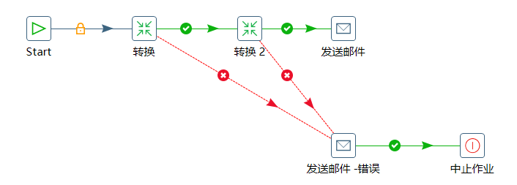
作业项是作业的基本构成部分,如同转换的步骤,作业项也可以使用图标的方式图形化展示。但是在作业项之间可以传达一个结果对象,这个结果对象里面包含了数据行,它不是以数据流的方式来传递的,而是等待一个作业项执行完了,再传递到下一个作业项,因为作业顺序执行作业项,所以必须定义一个起点,有一个叫“开始”的作业项就定义了这个点,一个作业项只能定一个开始作业项。
作业跳:作业项之间的连接线,他定义了作业的执行路径。作业里每个作业项的不同运行结果决定了做作业的不同执行路径。
3种执行顺序:
1、无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,上面有一个锁的图标。
2、当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情况下使用。这是一种绿色的连接线,上面有一个对钩号的图标。
3、当运行结果为假时执行:当上一个作业项的执行结果为假或者没有成功执行时,执行下一个作业项。这是一种红色的连接线,上面有一个红色的停止图标。
参数:
全局参数:定义是通过当前用户下.kettle文件夹中的kettle.properties文件来定义的。配置全局变量需要重启kettle才会生效
定义方式:键值对的方式:start_date = 20130101
局部参数:通过“Set Variable”与“Get Variable”方式来设置;在“Set Variable”时在当前转换当中是不能马上使用,需要在作业中的下一步骤中使用
参数的使用:在SQL中使用变量时需要把“是否替换变量”勾选上,否则无法使用变量
1、%%变量名%%
2、${变量名}
常量传递:自定义常量数据,在表输入的SQL语句里面使用?来替换;?替换的顺序就是常量定义的顺序;需要在从步骤中插入数据里选择上一步骤的自定义常量数据才能生效。
SELECT * FROM TABLE_NAME WHERE ID < ? AND ID > ?;
转换命名参数:在转换内部定义的变量,作用范围是在转换内部,在转换的空白处右键,选择转换设置就可以看见中的命名参数。
设置变量-获取变量:在转换里面一个作业分类,里面有设置变量和获取变量的步骤。
注意:“获取变量”时在当前转换当中不能马上使用,需要在作业的下一个步骤中使用

