揭秘python垃圾回收
说在前面
如果你了解过一些垃圾回收的方案,那么你应该会对垃圾回收的大致流程有些了解。本文适合略懂垃圾回收(GC)的人阅读,这里只是讲python3的垃圾回收算法,不是科普文!
- 环境:python 3.6.12
- 源码:https://www.python.org/downloads/release/python-3612/
python的GC算法
python使用的是引用计数+标记-清除+分代回收。其中引用计数为主,其他两种为辅。
- 引用计数
引用计数仍是目前最有效的GC方案。只需要耗费一点额外的内存来记录一个对象被引用的次数,就能最及时回收该对象。
当一个对象的引用计数为0时,它必定是可回收的(容易理解,自行推理)。python的做法也是这样,只要引用计数为0,则立即回收(del、变量赋值都可能导致某些对象的引用计数减少)。宏Py_DECREF就是用来减少引用计数的,如下:
#define _Py_Dealloc(op) ( \
_Py_INC_TPFREES(op) _Py_COUNT_ALLOCS_COMMA \
(*Py_TYPE(op)->tp_dealloc)((PyObject *)(op)))
#define Py_DECREF(op) \
do { \
PyObject *_py_decref_tmp = (PyObject *)(op); \
if (_Py_DEC_REFTOTAL _Py_REF_DEBUG_COMMA \
--(_py_decref_tmp)->ob_refcnt != 0) \
_Py_CHECK_REFCNT(_py_decref_tmp) \
else \
_Py_Dealloc(_py_decref_tmp); \
} while (0)
从上面可以看出,当一个对象的引用计数ob_refcnt为0时,立即调用_Py_Dealloc释放该对象,这是通过该对象的tp_dealloc方法处理的。下面看看dict的tp_dealloc对应的函数:
#define Py_XDECREF(op) \
do { \
PyObject *_py_xdecref_tmp = (PyObject *)(op); \
if (_py_xdecref_tmp != NULL) \
Py_DECREF(_py_xdecref_tmp); \
} while (0)
static void
dict_dealloc(PyDictObject *mp)
{
PyObject **values = mp->ma_values;
PyDictKeysObject *keys = mp->ma_keys;
Py_ssize_t i, n;
/* bpo-31095: UnTrack is needed before calling any callbacks */
PyObject_GC_UnTrack(mp);
Py_TRASHCAN_SAFE_BEGIN(mp)
if (values != NULL) {
if (values != empty_values) {
for (i = 0, n = mp->ma_keys->dk_nentries; i < n; i++) {
Py_XDECREF(values[i]); // 就是这里
}
free_values(values);
}
DK_DECREF(keys);
}
else if (keys != NULL) {
assert(keys->dk_refcnt == 1);
DK_DECREF(keys);
}
if (numfree < PyDict_MAXFREELIST && Py_TYPE(mp) == &PyDict_Type)
free_list[numfree++] = mp;
else
Py_TYPE(mp)->tp_free((PyObject *)mp);
Py_TRASHCAN_SAFE_END(mp)
}
可以看出,dict在释放其自身(即mp)之前,将其内所有元素(也就是values,因为key必然不是container)的引用计数减1,这个步骤需要递归处理(当value为container对象时)。
- 标记-清除
上面讲的引用计数虽然好用,但是解决不了循环引用的问题。比如下面例子:
a = [] # 新对象,设为q, 引用计数为1
b = [] # 新对象,设为p, 引用计数为1
a.append(b) # p += 1,即2
b.append(a) # q += 1,即2
del a # q -= 1, 即1
del b # p -= 1, 即1
上面程序执行完,引用计数q和p都为1,所以在执行完del后无法立即释放。循环引用只会出现在container之间(如list、dict、class等),其他类型则不会有此问题。于是,需要另外一种手段来辅助解决这个问题,标记-清除算法应运而生。
当一次GC触发时,可能存在哪些对象?
- 第1种:还未
del的对象,即能被程序直接用变量名获取到的 - 第2种:已被
del的对象,但是它还间接被有名变量所引用 - 第3种:已被
del的对象,程序已无法直接、间接访问到它了,但它仍被其他对象引用着(循环引用)
第1种必然是不必进行回收的,但是我们无法直接分辨。第2种也是不必进行回收的,因为程序还能间接取到该对象。第3种就是需要被回收的对象了。
不妨将这些对象看成多个有向图中的结点,举个例子,如下图:
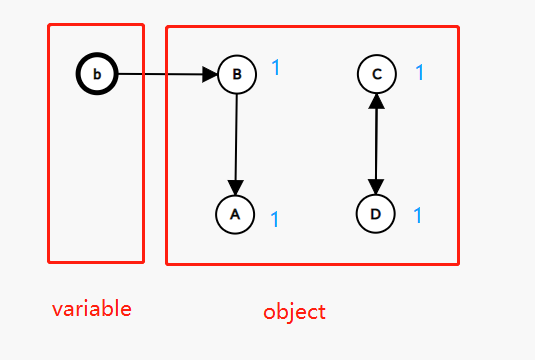
对应程序
c = []
d = [c]
c.append(d)
del c
del d
a = []
b = [a]
del a
- 变量b对应的对象B可以直接访问到(对应第1种)
- 变量a相应的对象A还能通过b间接访问到(对应第2种)
- 变量c、d相应的对象C、D已无法访问到(对应第3种)
标记-清除的思路是分三步进行:
-
第一步:先找出第1种
将第2个红框内的所有有向边去掉(不含b->B),得到A、B、C、D分别对应的引用计数是0、1、0、0,其中由于B的引用计数大于0,可断定其可被程序所直接获取,所以B是第1种。 -
第二步:找出第2种
从第1种得到的节点集B出发,所有能到达的点的集合就是第2种,即A。 -
第三步:找出第3种并释放它们
一个对象若不是第1种,也不是第2种,就属于第3种了,所以C、D是第3种。是可释放的对象。
至此,标记-清除算法完成。
- 分代回收
由于标记-清除算法虽然很实用,但是每次GC都得遍历所有对象,这在对象较多的时候实在吃不消,需要稍微优化一下以减少全员遍历的发生。
有大神观察发现,对象的生存时间越长,则被回收的概率越低。其实根据的是代码规范的局部性原则,即变量要尽量在使用时才定义(这里讲得不太好,请意会一下)。所以python将所有对象被分成3代(称为第0、1、2代),其中第0代是最年轻的,即最近才创建的对象,第1代次之,第2代是生存时间最久的。在GC的时候就只需要对其中一代进行精准回收即可,比如说第0代GC绝不会回收第1、2代的对象。
新创建的对象被放在了第0代,当第0代发生GC后,存活下来的对象就被移到第1代,同理,第1代也是如此,而第2代发生GC后存活对象就只能继续放在第2代了。需要留意的是,这3代的GC触发规则还不太一样,当程序中新创建对象个数达到count0后会触发第0代GC,当第0代GC次数达到count1后会触发第1代GC,当第1代GC次数达到count2后会触发第2代GC,执行gc.get_threshold()即可拿到这3个值。
看到这里可能会有个疑问: 分代后如何进行GC?和不分代有什么差别?
首先来看一些细节:
- python对第0代执行GC时,就只会遍历第0代的对象
- python对第1代执行GC之前,会将第0代的对象全部移到第1代
- python对第2代执行GC之前,会将第0、1代的对象全部移到第2代(即全量GC)
不分代的GC是全量的GC,不会出现对象跨代引用的问题。而python对跨代引用的解决方法就是不回收,即涉及到的对象都不回收,它们若是垃圾,最终必定会在同一代被回收。跨代引用的例子如下:
>>> import gc
>>> a = []
>>> b = []
>>> a.append(b)
>>> b.append(a)
>>> gc.collect(0) # 没有对象被回收,a和b自动升级到第1代
0
>>> c = []
>>> c.append(a) # 让c引用一下第1代的对象
>>> b.append(c)
>>>
>>> del a
>>> del b
>>> del c # 此时c在第0代
>>> # 此时情况如下图
>>> gc.collect(0) # 没有对象会被回收
0
>>> gc.collect(1) # 3个对象都被回收
3

根据上面讲过的所有内容,这样的结果符合预期。在第2次gc.collect(0)时,并没有回收C,因为它和第1代的对象仍有引用关系。其实,这种情况也好处理,python源码如下:
static int
visit_decref(PyObject *op, void *data)
{
if (PyObject_IS_GC(op)) {
PyGC_Head *gc = AS_GC(op);
assert(_PyGCHead_REFS(gc) != 0);
if (_PyGCHead_REFS(gc) > 0)
_PyGCHead_DECREF(gc); // 引用次数 -1
}
return 0;
}
static void
subtract_refs(PyGC_Head *containers)
{
traverseproc traverse;
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc=gc->gc.gc_next) { // 遍历当代每个节点
traverse = Py_TYPE(FROM_GC(gc))->tp_traverse;
traverse(FROM_GC(gc), (visitproc)visit_decref, NULL); // 逐个访问该container引用的所有对象
}
}
static void
update_refs(PyGC_Head *containers)
{
PyGC_Head *gc = containers->gc.gc_next;
for (; gc != containers; gc = gc->gc.gc_next) { // 仅处理当前代
assert(_PyGCHead_REFS(gc) == GC_REACHABLE);
_PyGCHead_SET_REFS(gc, Py_REFCNT(FROM_GC(gc))); // 拷贝
assert(_PyGCHead_REFS(gc) != 0); // 等于零的早被立即回收了
}
}
static void
move_unreachable(PyGC_Head *young, PyGC_Head *unreachable)
{
PyGC_Head *gc = young->gc.gc_next;
while (gc != young) {
PyGC_Head *next;
if (_PyGCHead_REFS(gc)) {
PyObject *op = FROM_GC(gc);
traverseproc traverse = Py_TYPE(op)->tp_traverse;
assert(_PyGCHead_REFS(gc) > 0);
_PyGCHead_SET_REFS(gc, GC_REACHABLE);
traverse(op, (visitproc)visit_reachable, (void *)young);
next = gc->gc.gc_next;
if (PyTuple_CheckExact(op)) {
_PyTuple_MaybeUntrack(op);
}
}
else {
next = gc->gc.gc_next;
gc_list_move(gc, unreachable); // 看这里,只有引用计数为0才可能会被回收
_PyGCHead_SET_REFS(gc, GC_TENTATIVELY_UNREACHABLE);
}
gc = next;
}
}
static Py_ssize_t
collect(int generation, Py_ssize_t *n_collected, Py_ssize_t *n_uncollectable, int nofail)
{
...
update_refs(young); // 拷贝引用计数
subtract_refs(young); // 去掉有向边
move_unreachable(young, &unreachable); // 将可能是垃圾的对象找出来
...
}
在visit_decref中在执行_PyGCHead_DECREF之前的那个if判断,它可以过滤掉那些比自己年长的对象(指的是年代比当前代大的)。因为update_refs只更新了当前代的对象的_PyGCHead_REFS(gc),其他代的_PyGCHead_REFS(gc)仍然是个特殊值GC_REACHABLE,是个负值,所以其他代的对象的引用计数_PyGCHead_REFS(gc)不会被改变。而源码中只会考虑回收当代中去掉有向边后引用计数为0的对象。
剩下一点小细节:
- 在执行GC时,对象的引用计数是不能动的,至少对不能回收的对象来说,它还有用呢。所以在执行GC之前需要拷贝一份出来使用,这一步对应上面源码中的
update_refs函数。
至此,所有python3垃圾回收的细节都讲完了,若有不明之处,你掏钱,我来给你讲讲。

