
阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
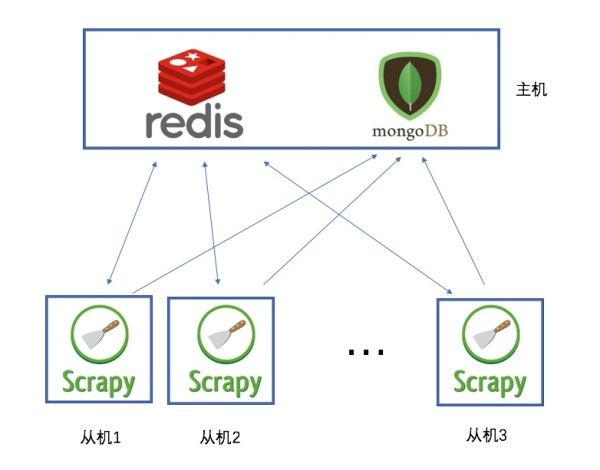
说白了,就是使用redis来维护一个url队列,然后scrapy爬虫都连接这一个redis获取url,且当爬虫在redis处拿走了一个url后,redis会将这个url从队列中清除,保证不会被2个爬虫拿到同一个url,即使可能2个爬虫同时请求拿到同一个url,在返回结果的时候redis还会再做一次去重处理,所以这样就能达到分布式效果,我们拿一台主机做redis 队列,然后在其他主机上运行爬虫.且scrapy-redis会一直保持与redis的连接,所以即使当redis 队列中没有了url,爬虫会定时刷新请求,一旦当队列中有新的url后,爬虫就立即开始继续爬
首先分别在主机和从机上安装需要的爬虫库
pip3 install requests scrapy scrapy-redis redis
在主机中安装redis
#安装redis yum install redis 启动服务 systemctl start redis 查看版本号 redis-cli --version 设置开机启动 systemctl enable redis.service
修改redis配置文件 vim /etc/redis.conf 将保护模式设为no,同时注释掉bind,为了可以远程访问,另外需要注意阿里云安全策略也需要暴露6379端口
改完配置后,别忘了重启服务才能生效
systemctl restart redis
然后分别新建爬虫项目
scrapy startproject myspider
在项目的spiders目录下新建test.py
#导包 import scrapy import os from scrapy_redis.spiders import RedisSpider #定义抓取类 #class Test(scrapy.Spider): class Test(RedisSpider): #定义爬虫名称,和命令行运行时的名称吻合 name = "test" #定义redis的key redis_key = 'test:start_urls' #定义头部信息 haders = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/73.0.3683.86 Chrome/73.0.3683.86 Safari/537.36' } def parse(self, response): print(response.url) pass
然后修改配置文件settings.py,增加下面的配置,其中redis地址就是在主机中配置好的redis地址:
BOT_NAME = 'myspider' SPIDER_MODULES = ['myspider.spiders'] NEWSPIDER_MODULE = 'myspider.spiders' #设置中文编码 FEED_EXPORT_ENCODING = 'utf-8' # scrapy-redis 主机地址 REDIS_URL = 'redis://root@39.106.228.179:6379' #队列调度 SCHEDULER = "scrapy_redis.scheduler.Scheduler" #不清除缓存 SCHEDULER_PERSIST = True #通过redis去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" #不遵循robots ROBOTSTXT_OBEY = False
最后,可以在两台主机上分别启动scrapy服务
scrapy crawl test
此时,服务已经起来了,只不过redis队列中没有任务,在等待状态
进入主机的redis
redis-cli
将任务队列push进redis
lpush test:start_urls http://baidu.com
lpush test:start_urls http://chouti.com
可以看到,两台服务器的爬虫服务分别领取了队列中的任务进行抓取,同时利用redis的特性,url不会重复抓取
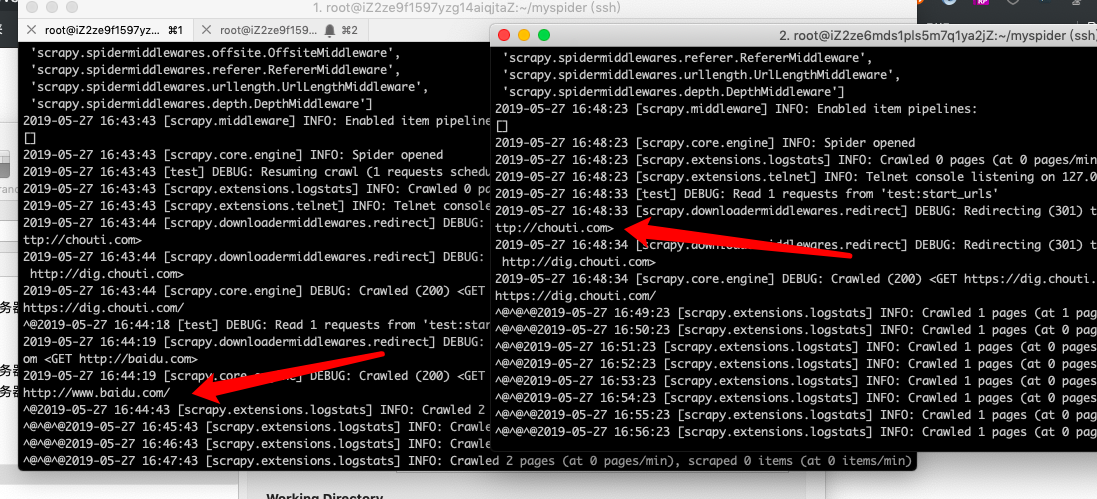
爬取任务结束之后,可以通过flushdb命令来清除地址指纹,这样就可以再次抓取历史地址了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号