关系型数据库到HBase的数据储存方式变迁(摘抄)

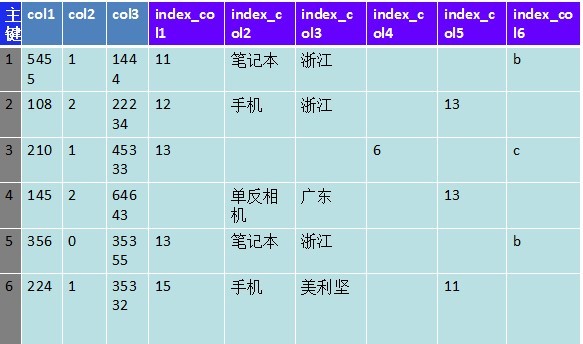
上图是6个索引字段,实际情况可能是上百个甚至更多,并且还需要根据多个索引字段刷选。查询性能越来越低,甚至无法满足查询要求。关系型数据里的局限也开始显现,于是很多人开始接触NoSQL。
列族数据库很强大,很多人就想把数据从mysql迁到hbase,存储的方式还是跟图一或者图二一样,主键为rowkey。其他各个字段的数据,存 储一个列族下的不同列。但是想对索引字段查询就没有办法,目前还没有比较好的基于bigtable的二级索引方案,所以无法对索引字段做查询。

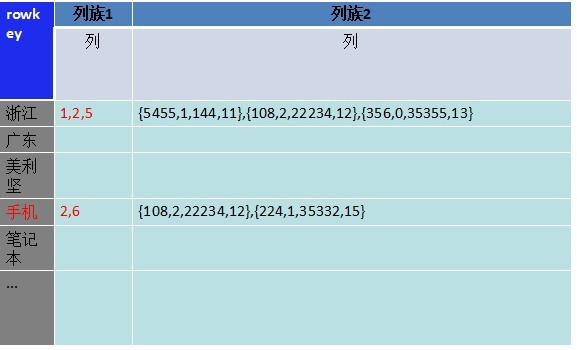
图四

口水:Hbase将table水平划分成N个Region,region按column family划分成Store,每个store包括内存中的memstore和持久化到disk上的HFile。

具体操作过程如下:
============================创建blogtable表=========================
create 'blogtable', 'info','text','comment_title','comment_author','comment_text'
============================插入概要信息=========================
put 'blogtable', '1', 'info:title', 'this is doc title'
put 'blogtable', '1', 'info:author', 'javabloger'
put 'blogtable', '1', 'info:url', 'http://www.javabloger.com/index.php'
put 'blogtable', '2', 'info:title', 'this is doc title2'
put 'blogtable', '2', 'info:author', 'H.E.'
put 'blogtable', '2', 'info:url', 'http://www.javabloger.com/index.html'
============================插入正文信息=========================
put 'blogtable', '1', 'text:', 'what is this doc context ?'
put 'blogtable', '2', 'text:', 'what is this doc context2?'
==========================插入评论信息===============================
put 'blogtable', '1', 'comment_title:', 'this is doc comment_title '
put 'blogtable', '1', 'comment_author:', 'javabloger'
put 'blogtable', '1', 'comment_text:', 'this is nice doc'
put 'blogtable', '2', 'comment_title:', 'this is blog comment_title '
put 'blogtable', '2', 'comment_author:', 'H.E.'
put 'blogtable', '2', 'comment_text:', 'this is nice blog'
HBase的数据查询\读取,可以通过单个row key访问,row key的range和全表扫描,大致如下:
注意:HBase不能支持where条件、Order by 查询,只支持按照Row key来查询,但是可以通过HBase提供的API进行条件过滤。
例如:http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/filter/ColumnPrefixFilter.html
scan 'blogtable' ,{COLUMNS => ['text:','info:title'] } —> 列出 文章的内容和标题
scan 'blogtable' , {COLUMNS => 'info:url' , STARTROW => '2'} —> 根据范围列出 文章的内容和标题
get 'blogtable','1' —> 列出 文章id 等于1的数据
get 'blogtable','1', {COLUMN => 'info'} —> 列出 文章id 等于1 的 info 的头(Head)内容
get 'blogtable','1', {COLUMN => 'text'} —> 列出 文章id 等于1 的 text 的具体(Body)内容
get 'blogtable','1', {COLUMN => ['text','info:author']} —> 列出 文章id 等于1 的内容和作者(Body/Author)内容
我的废话2:
有人会问Java Web服务器中是Tomcat快还是GlassFish快?小型数据库中是MySQL效率高还是MS-SQL效率高?我看是关键用在什么场景和怎么使用这 个产品(技术),所以我渐渐的认为是需要对产品、技术本身深入的了解,而并非一项新的技术就是绝佳的选择。试问:Tomcat的默认的运行参数能和我们线 上正在使用的GlassFish性能相提并论吗?我不相信GlassFishv2和GlassFishv3在默认的配置参数下有显著的差别。我们需要对产 品本身做到深入的了解才能发挥他最高的性能,而并非感观听从厂家的广告和自己的感性认识 迷信哪个产品的优越性。
我的废话3:
对于NOSQL这样的新技术,的的确确是可以解决过去我们所需要面对的问题,但也并非适合每个应用场景,所以在使用新产品的同时需要切合当前的产品需要, 是需求在引导新技术的投入,而并非为了赶时髦去使用他。你的产品是否过硬不是你使用了什么新技术,用户关心的是速度和稳定性,不会关心你是否使用了 NOSQL。相反Google有着超大的数据量,能给全世界用户带来了惊人的速度和准确性,大家才会回过头来好奇Google到底是怎么做到的。所以根据 自己的需要千万别太勉强自己使用了某项新技术。
我的废话4:
总之一句话,用什么不是最关键,最关键是怎么去使用!
前面刚开始使用HBase只是用于存取某些简单的JAVA对象或是简单数据,所以一般设置列族和列标示时只用一个就行了。
最近有个任务是把系统中的站内消息移到HBase当中去,才开始查HBase中的一对多关系,发现网上的资料讲的都不甚详尽,这篇blog记录一下我的设计和想法,这些想法毕竟未经证实,尚需验证。如果有大虾认为有不妥甚至错误的地方请不吝指教。
首先讲两个我参考的资料,背景:一个主贴和N个回帖的一对多关系,学过一点数据库的应该都能体会到,图我就不画了:
1.官方推荐资料:
http://wiki.apache.org/hadoop/Hbase/DataModel
2.一位大大的简单HBase一对多表结构的介绍(感觉实际上他参考了资料1,不过讲的不太。。合理,而且下面列表的那个comment_title应该是写错了,一对多的那个例子貌似也让人很不解):
http://doudouclever.blog.163.com/blog/static/17511231020127893233972/
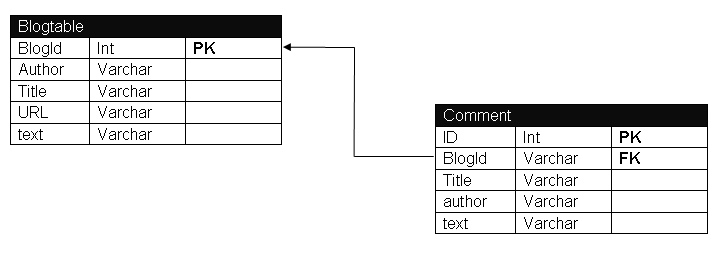
最终的解决方案是这个表(按照官方资料):
| Table | Row Key | Family | Attributes(ColumnKeys/Qualifiers) |
| BlogTable | ID | info: | Author,Title,URL |
| text: | No ColumnKey,3version | ||
| comment title: | Column keys are written like YYYMMDDHHmmss. Should be IN-MEMORY and have a 1 version | ||
| comment author: | Same keys. 1 Version | ||
| comment text: | Same keys. 1 Version |
1.HBase的二维表结构:

2.Hbase中,对于某个Column Family中的Column Key是可以动态增加的
存储于关系型数据库中的数据如下,简单起见某些字段删减了:
表头
| ID | Author | Title | Body |
| 1 | 张三 | 消息头 | 这是内容Hello World! |
| ID | HeadID | CommentAuthor | Title | Body |
| 1 | 1 | 李四 | 回复头1 | 这是回复内容1 |
| 2 | 1 | 王五 | 回复头2 | 这是回复内容2 |

结论:从图中可以看出,HBase是把以前关系数据库明细表的字段作为ColumnFamily,而明细表的主键作为ColumnKey的这种结构来达到一对多的效果的。关系型数据库,明细增多时是纵向添加数据;对于Hbase,则是通过ColumnKey的增加来添加数据
由此可能产生的问题:
- 1.HBase官方不推荐多Column Family,超过3个是妥妥儿不推荐的,原文见
- http://hbase.apache.org/book.html#number.of.cfs 可是一对多的这种关系是必须用多Column Family的,这点矛盾让我到现在还很不解。。
- 2.RowKey的存储问题,传统数据库主键一般都是递增的方式生成的一批证书值,但是Hbase采用这种方式做为RowKey的话会导致regionserver负载过高的问题,所以RowKey的生成方式需要再讨论。
- 3.这种一对多的方式,如果回复很多很多,比如贴吧随便一个帖子就是上W回复的,会导致ColumnKey变得很多,也就是说Hbase表会变得很宽
- 尽管看过帖子说HBase并不是传统意义的二维结构,就是不会单独为某个Cell为空的区域留出空间存储数据(这里我可能理解和描述的都不太贴切), 总之这种“宽”的表结构,是对传统数据库表结构意识形态的一种冲击,不知道会不会有问题。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号