

synchronized 关键字原理
OS 有哪些方法来完成同步:
- 互斥量
pthread_mutex_t:重量锁,拿不到锁就sleep,会进入内核态synchronized使用了mutex
- 自旋锁
pthread_spin_t:OS 空转 - 信号量
sem
synchronized 字节码原理:monitorenter monitorexit,会在异常表处理异常,保证调用monitorexit 退出临界区,并调用 athorw 抛出异常。
对象头
对象布局:
-
对象头
- Mark Word:64 bit
- 类型指针 klass pointer:默认使用了指针压缩技术为 32 bit,否则是 64 bit
- 若为对象数组,还应有记录数组长度的数据
-
实例数据
-
对齐填充:8 字节的整数倍
打印对象信息
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
<scope>provided</scope>
</dependency>
MarkWord markWord = new MarkWord();
// markWord.hashCode();
System.out.println(VM.current().details());
System.out.println(ClassLayout.parseClass(MarkWord.class).toPrintable());
System.out.println(ClassLayout.parseInstance(markWord).toPrintable());
打印出来的对象头二进制信息是按字节(8位)倒叙,因为是小堆存储。
# Running 64-bit HotSpot VM.
# Using compressed oop with 3-bit shift.
# Using compressed klass with 3-bit shift.
# WARNING | Compressed references base/shifts are guessed by the experiment!
# WARNING | Therefore, computed addresses are just guesses, and ARE NOT RELIABLE.
# WARNING | Make sure to attach Serviceability Agent to get the reliable addresses.
# Objects are 8 bytes aligned.
# Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes]
org.jxch.test.markword.MarkWord object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 12 (object header) N/A
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
org.jxch.test.markword.MarkWord object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 64 21 18 00 (01100100 00100001 00011000 00000000) (1581412)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
MarkWord
markWord.hpp:
// 64 bits:
// --------
// unused:25 hash:31 -->| unused_gap:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused_gap:1 age:4 biased_lock:1 lock:2 (biased object)
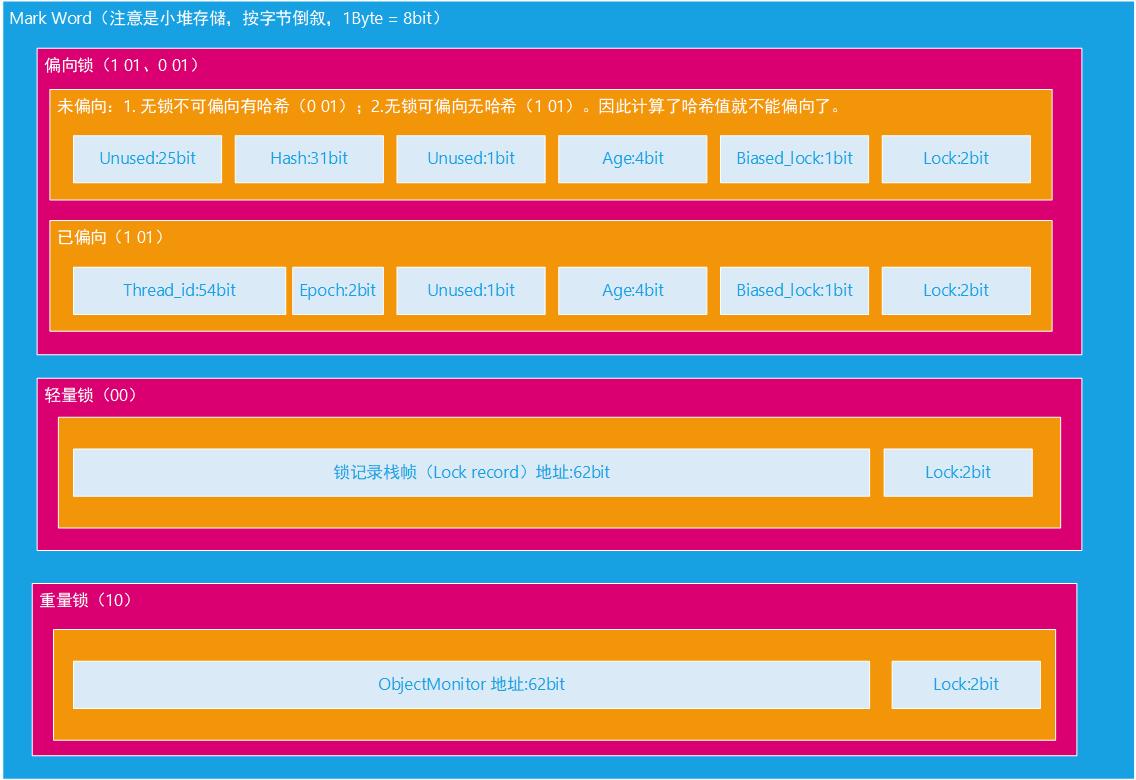
偏向锁
计算了 hash 值后,就不可偏向了,直接升为轻量锁,因为无法存放 thread_id 了。
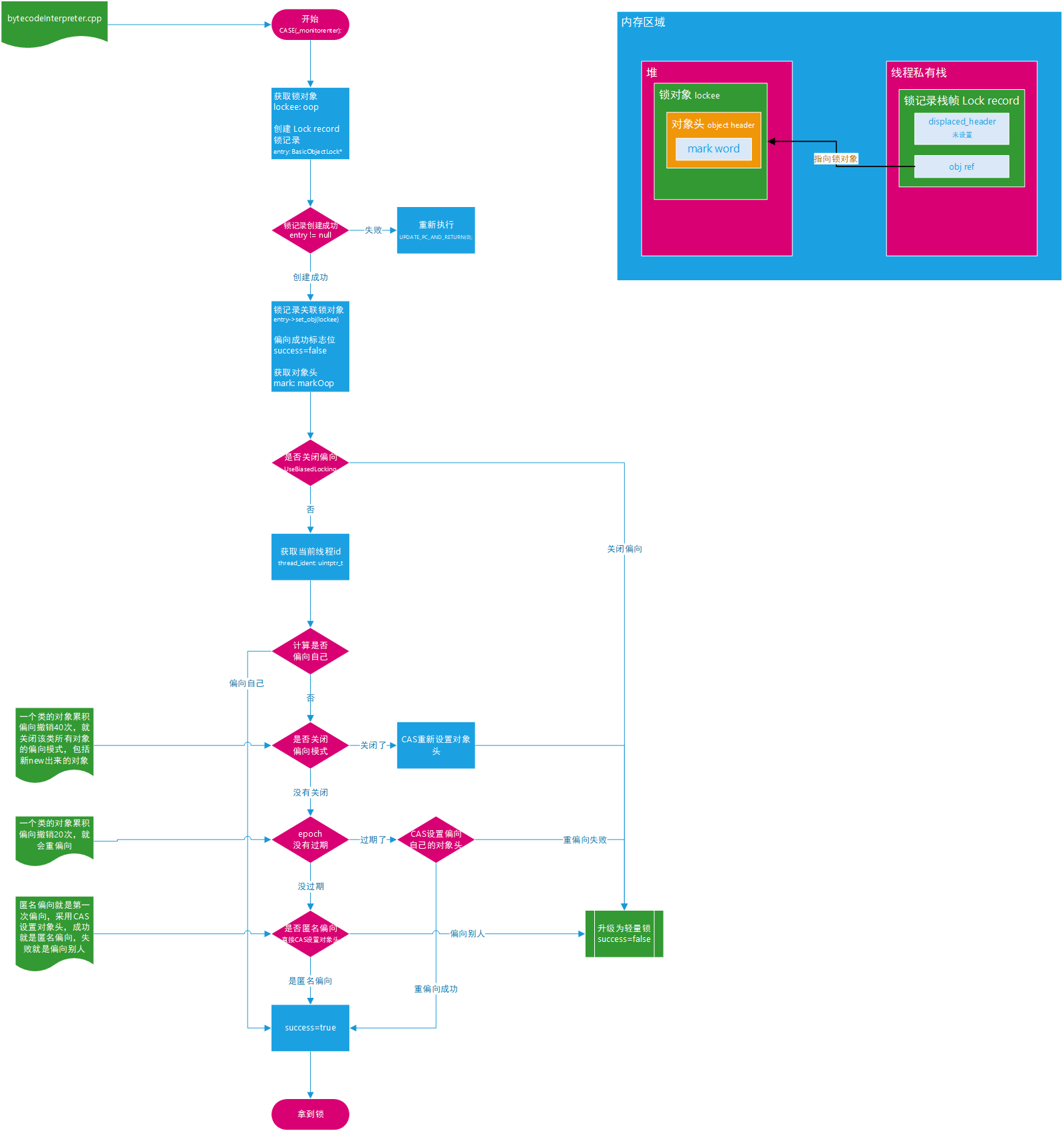
- 很多项目需要使用
-XX:UseBiasedLocking关闭偏向锁,判断自己的项目几乎用不到偏向锁时可以关闭 - 偏向锁延时:
-XX:BiaseLockingStartupDelay- JVM 认为自身启动时用不到偏向锁,所以为了省去锁的膨胀和偏向锁撤销的过程,使用了偏向延时,默认四秒,因为四秒足够它启动了
- 线程 id 重复:一个线程死了,操作系统为新线程分配的id可能与上一个线程相同。偏向锁依然生效,这不是 bug。
轻量锁
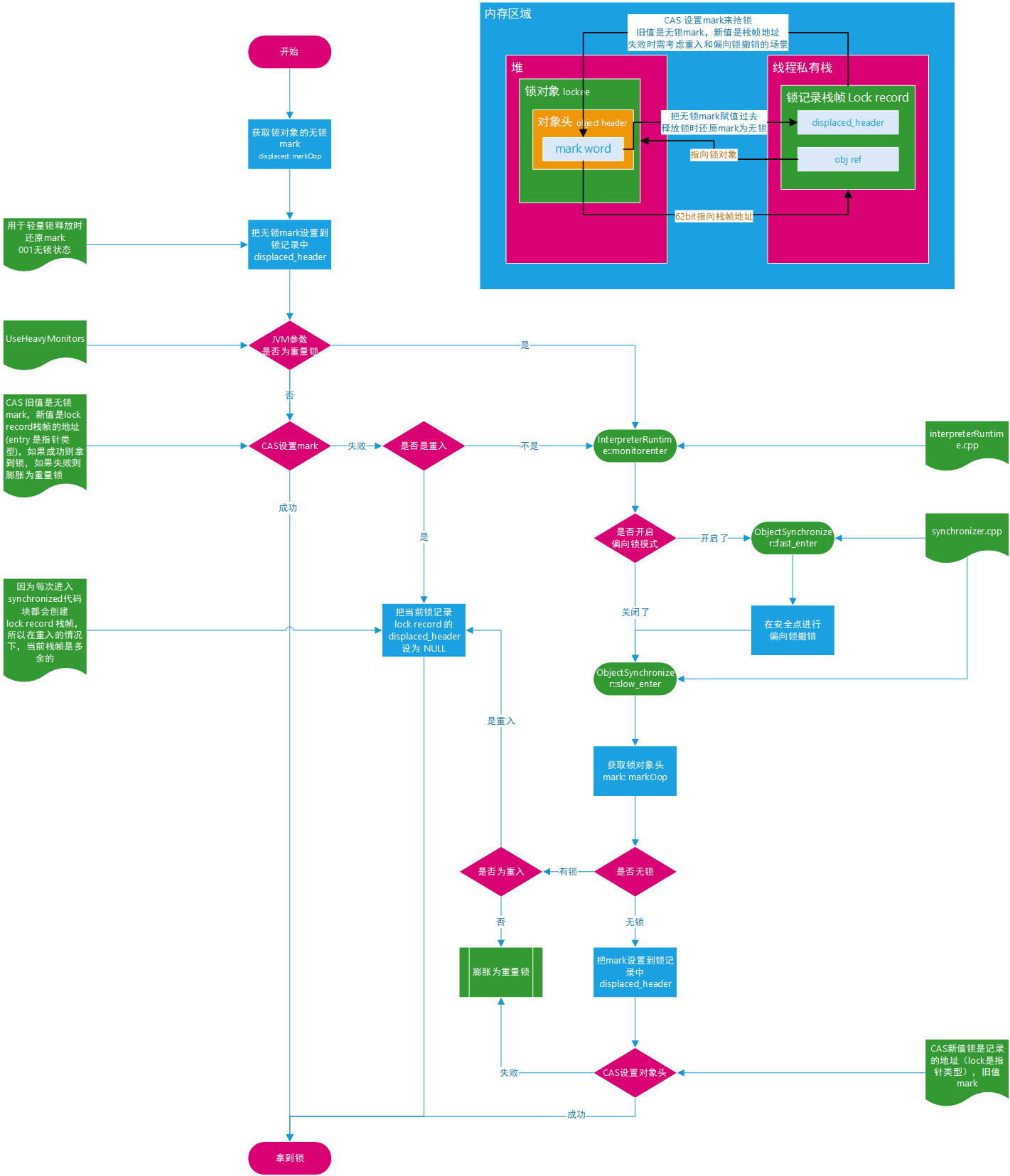
重量锁
太复杂了,简单了解一下,原理和 AQS 差不多。
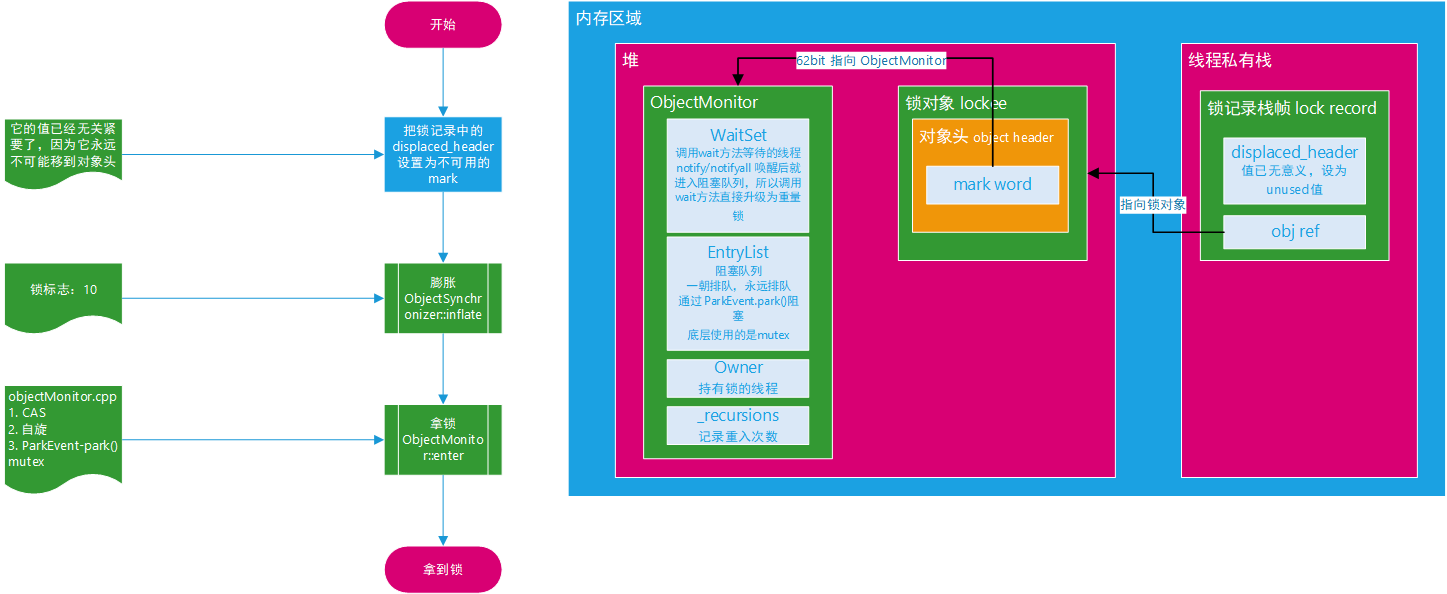
synchronized关键字是非公平锁。因为它直接 CAS 尝试拿锁,失败后才排队synchronized关键字是重量锁,底层调用metux进入内核态park()方法也会进入内核态
wait notify
持有锁的线程发现条件不满足,调用 wait,即可进入 WaitSet 变为 WAITING 状态 BLOCKED和 WAITING 的线程都处于阻塞状态,不占用 CPU 时间片 BLOCKED 线程会在 持有锁的线程释放锁时唤醒 WAITING 线程会在 持有锁的线程调用 notify/notifyAll 时唤醒,但唤醒后并不意味者立刻获得锁仍需进入 EntryList 重新竞争
和 sleep 的区别:
wait是Object的方法;任何对象都可以直接调用;sleep是Thread的静态方法wait必须配合synchronized关键字一起使用;如果一个对象没有获取到锁直接调用wait会异常;sleep则不需 要wait可以通过notify主动唤醒;sleep只能通过打断主动叫醒wait会释放锁、sleep在阻塞的阶段是不会释放锁的
