五一培训 清北学堂 DAY2
今天还是冯哲老师的讲授~~
今日内容:简单数据结构(没看出来简单qaq)
1.搜索二叉树
前置技能 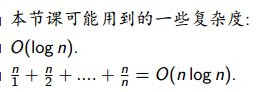
一道入门题
在初学OI的时候,总会遇到这么一道题。
给出N次操作,每次加入一个数,或者询问当前所有数的最大值。
维护一个最大值Max,每次加入和最大值进行比较。
时间复杂度O(N).
EX:入门题
给出N次操作,每次加入一个数,删除一个之前加入过的数,或者询问当前所有数的最大值。
N ≤ 100000.
引入二叉搜索树(BST):
特征:
二叉搜索树的key值是决定树形态的标准。
每个点的左子树中,节点的key值都小于这个点。
每个点的右子树中,节点的key值都大于这个点。
一个好例子:
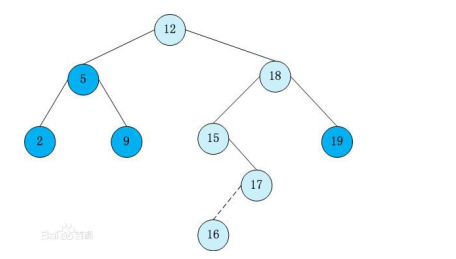
我们可以发现:每个结点的左儿子一定小于该结点,右儿子一定大于该结点!
进一步可以推出:每一层从左往右都是按从大到小的顺序拍好的(虽然没啥用)
示例:

基本操作:
查询最大/最小值
注意到BST左边的值都比右边小,所以如果一个点有左儿子,就往左儿子走,否则这个点就是最小值啦。
代码(最小值):
int Findmin() { int x = root; //x记录当前结点,当然从根节点开始找 while (ls[x]) x=ls[x]; //如果Is[x]不为0,说明有左儿子,让x等于它的左儿子 return key[x]; //返回最小权值 }
插入一个值
现在我们要插入一个权值为x的节点。
为了方便,我们插入的方式要能不改变之前整棵树的形态。
首先找到根,比较一下key[root]和x,如果key[root] < x,节点应该插在root右侧,否则再左侧。
看看root有没有右儿子,如果没有,那么直接把root的右儿子赋成x就完事了。
否则,为了不改变树的形态,我们要去右儿子所在的子树里继续这一操作,直到可以插入为止。
删除一个值
现在我们要删除一个权值为x的点
之前增加一个点我们能够不改变之前的形态。
定位一个节点
要删掉一个权值,首先要知道这个点在哪。
从root开始,像是插入一样找权值为x的点在哪。
int Find(int x) //在搜索二叉堆里定位一个数 { int now=root; //从根节点开始找 while(key[now]!=x) //如果不相等就一直往下找 if (key[now]<x) now=rs[now]; //如果大于当前结点就直接从右边找,二分思想减少复杂度 else now=ls[now]; //否则从左边找 return now; //如果没找到会返回空值 }
方案一
直接把这个点赋成一种空的状态.
但是这样的话查询起来不太方便。
所以还是稍微麻烦一点吧。
方案二
对这个节点x的儿子情况进行考虑。
如果x没有儿子,删掉x就行了。
如果x有一个儿子,直接把x的儿子接到x的父亲下面就行了。
x如果是x父亲的左儿子,那么x的儿子直接接在x父亲的左下面就好了,否则接在右下面
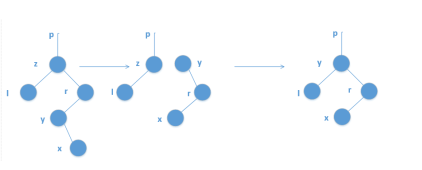
如果x有两个儿子,这种情况就比较麻烦了。
定义x的后继y,是x右子树中所有点里,权值最小的点。
找这个点可以x先走一次右儿子,再不停走左儿子。(因为y肯定在x右子树中的最左侧)
如果y是x的右儿子,那么直接把y的左儿子赋成原来x的左儿子,然后用y代替x的位置。
原理:
就算y是x右儿子中最小的一个,但一定比x的任何一个左儿子都大,所以换到x的位置其他的点不用动,因为左边的点都比他小,右边的点都比他大,而x小于任何一个右子树的点,所以换到右子树里就是最小的那个,也就是之前y所在的位置,又因为y没有左儿子,但可能有右儿子(y的右儿子代替的是y他本来在的位置),所以x换过去就成了上面只有一个孩子的情况,这样删除就方便啦!(不得不说这也太强了吧!)
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 300005 #define M 8000005 #define mid ((l+r)>>1) #define mk make_pair #define pb push_back #define fi first #define se second using namespace std; int i,j,m,n,p,k,ls[N],rs[N],sum[N],size[N],a[N],root,tot,fa[N]; void ins(int x)//插入一个权值为x的数字 { sum[++tot]=x; //用tot来表示二叉树里的节点个数,sum数组存第tot个结点的权值 size[tot]=1; //它能遍历到的点只有它自己 if (!root) root=tot;//如果一开始一个节点都没有,就要找一个节点当根 else { int now=root; //从根开始 for (;;) { ++size[now]; if (sum[now]>sum[tot]) //判断和当前节点的大小,如果tot小于当前结点now,说明应该插在now左边 { if (!ls[now]) //如果now没左儿子,直接插入 { ls[now]=tot;fa[tot]=now; //标记now的左儿子为tot,tot的父亲为now break; //跳出循环,进入下次插入 } else now=ls[now];//如果now有左儿子,那么继续从now的左儿子Is[now]继续往下找 } else { if (!rs[now]) //与上面同理 { rs[now]=tot; fa[tot]=now; break; } else now=rs[now]; } } } } int FindMin() //找最小值,肯定在左子树里 { int now=root; //从根节点开始找 while (ls[now]) now=ls[now]; //一直往下找,直到没有左孩子 return sum[now]; //返回最小值 } void build1()//暴力build的方法,每次插入一个值 { for (i=1;i<=n;++i) ins(a[i]); } int Divide(int l,int r) { if (l>r) return 0; ls[mid]=Divide(l,mid-1); rs[mid]=Divide(mid+1,r); fa[ls[mid]]=fa[rs[mid]]=mid; fa[0]=0; sum[mid]=a[mid]; size[mid]=size[ls[mid]]+size[rs[mid]]+1; return mid; } void build2()//精巧的构造,使得树高是log N的 { sort(a+1,a+n+1); root=Divide(1,n); tot=n; } int Find(int x)//查询值为x的数的节点编号 { int now=root; while (sum[now]!=x&&now) if (sum[now]<x) now=rs[now]; else now=ls[now]; return now; } int Findkth(int now,int k) { if (size[rs[now]]>=k) return Findkth(rs[now],k); //因为右子树的数都大于左子树中的数,所以如果当前点右子树的size值大于k,那么第k大的值一定在右子树里,递归右子树继续往下找 else if (size[rs[now]]+1==k) return sum[now]; //因为右子树一共有size[rs[now]]个,若size[rs[now]]+1==k,说明第k大的值就是当前结点,直接返回,因为左边的数都比当前结点的数小 else Findkth(ls[now],k-size[rs[now]]-1);//注意到递归下去之后右侧的部分都比它要大,第k大的数只能在左子树里了,此时我们已经找了前size[rs[now]]+1位大数了,所以要用k减去它 } void del(int x) //删除一个值为x的点 { int id=Find(x),t=fa[id];//找到这个点的编号id,t位id的父亲 if (!ls[id]&&!rs[id]) //如果这个结点没有儿子 { if (ls[t]==id) ls[t]=0; //是左儿子就将ls[t]置空 else rs[t]=0; //否则就将rs[t]置空 for (i=id;i;i=fa[i]) size[i]--; //将结点id删去后,他及他的祖先能遍历到的点都减少了一,所以要减去一 } else if (!ls[id]||!rs[id]) //只有一个儿子 { int child=ls[id]+rs[id];//找存在的儿子的编号,因为其中肯定有一个儿子的编号为0表示没有该儿子,加起来就是存在的那个儿子的编号 if (ls[t]==id) ls[t]=child; //是左儿子就将ls[t]接上id的孩子child else rs[t]=child; //否则就将rs[t]接上id的孩子child fa[child]=t; //标记child的新父亲 for (i=id;i;i=fa[i]) size[i]--; //将结点id删去后,他及他的祖先能遍历到的点都减少了一,所以要减去一 } else { int y=rs[id]; while (ls[y]) y=ls[y]; //找后继 if (rs[id]==y) { if (ls[t]==id) ls[t]=y; else rs[t]=y; fa[y]=t; ls[y]=ls[id]; fa[ls[id]]=y; for (i=id;i;i=fa[i]) size[i]--; size[y]=size[ls[y]]+size[rs[y]];//y的子树大小需要更新 } else //最复杂的情况 { for (i=fa[y];i;i=fa[i]) size[i]--;//注意到变换完之后y到root路径上每个点的size都减少了1 int tt=fa[y]; //先把y提出来 if (ls[tt]==y) { ls[tt]=rs[y]; fa[rs[y]]=tt; } else { rs[tt]=rs[y]; fa[rs[y]]=tt; } //再来提出x if (ls[t]==x) { ls[t]=y; fa[y]=t; ls[y]=ls[id]; rs[y]=rs[id]; } else { rs[t]=y; fa[y]=t; ls[y]=ls[id]; rs[y]=rs[id]; } size[y]=size[ls[y]]+size[rs[y]]+1;//更新一下size } } } int main() { scanf("%d",&n); for (i=1;i<=n;++i) scanf("%d",&a[i]); build1(); printf("%d\n",Findkth(root,2));//查询第k大的权值是什么,这里k==2 del(4); printf("%d\n",Findkth(root,2));
return 0; }
遍历
注意到权值在根的左右有明显的区分。
做一次中序遍历(按照 左儿子——父亲结点——右儿子的顺序访问)就可以从小到大把所有树排好了。
int dfs(int now) { if (ls[now]) dfs(ls[now]); //如果有左儿子,访问左儿子 printf("%d",key[now]) //输出now结点的权值 if (rs[now]) dfs(rs[now]); //如果有右儿子,访问右儿子 }
回到最初的题
让我们回到最初的题。
一个良好的例子:3 1 2 4 5
一个糟糕的例子:1 2 3 4 5
二叉搜索树每次操作访问O(h)个节点。
总结

2.二叉堆
定义

建堆

求最小值
可以发现每个点都比两个儿子小,那么最小值显然就是a[1]辣,是不是很simple啊。
插入一个值

修改一个点的权值
咦,为什么没有删除最小值?
删除最小值只要把一个权值改到无穷大就能解决辣
比较简单的是把一个权值变小。
那只要把这个点像插入一样向上动就行了。
变大权值
那么这个点应该往子树方向走。
看看这个点的两个儿子哪个比较小。
如果小的那个儿子的权值比他小,就交换。
直到无法操作。
解决定位问题
一般来说,堆的写法不同,操作之后堆的形态不同.
所以一般给的都是改变一个权值为多少的点.
假设权值两两不同,再记录一下某个权值现在哪个位置。
在交换权值的时候顺便交换位置信息。
删除权值
理论上来说删除一个点的权值就只需要把这个点赋成inf 然后down一次。
但是这样堆里的元素只会越来越多.
我们可以把堆里第n号元素跟这个元素交换一下。
然后n - -,把堆down一下就行了。
建堆
现在来考虑一种新的建堆方法。
倒序把每个节点都down一下.
正确性肯定没有问题。
复杂度n/2 + n/4 * 2 + n/8 * 3 + .... = O(n)
堆排序
看个题喽~
例一
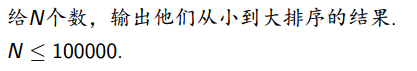
某正常学生:sort大法好,轻松过
奆佬冯哲老师:堆排堆排qwq
Sol
把数全部插进去,每次询问最小值,然后把根删掉就行了.
复杂度O(N log N). (和sort看起来差不多,排的次数多了就能看出差别来了)
例二——丑数

某正常学生:打表大法好!没有什么是打表解决不了的.
奆佬冯哲老师:
考虑递增的来构造序列.
x被选中之后,接下来塞进去x * 2, x * 3, x * 5, x * 7.
如果当前最小的数和上一次选的一样,就跳过.(话说有点像线性筛)
复杂度O(K log N).
Queue
每次都要写堆太麻烦了有没有什么方便的。
在C + +的include < queue >里有一个叫priority queue的东西。
基本操作:
set
堆好弱小啊,有没有什么更好用的。
在C + +的include < set >里有一个叫set的东西。
基本操作:
堆有啥用
我也不知道它有啥用(大雾
了解一种数据结构
为将来学习可并堆,斐波那契堆打下坚实基础(政治课即视比STL快。
能优化dij(图论).
3.RMQ
最简单的问题
给出一个序列,每次询问区间最大值.
N ≤ 100000, Q ≤ 1000000.
ST表

预处理

我们设f[i][j]是以i点为左端点向右2^j个单位这一区间的最小值,也就是区间[i,i+2^j);
显然这个区间的长度为2^j;
我们可以将这个区间平分为两半,因为原来的区间长度为2^j,所以平分后每个小区间的长度均为2^(j-1);
所以这两个小区间可以表示为: 左区间: f[i][j-1] 右区间:f[i+2^(j-1)][j-1] (左区间的右端点就是右区间的左端点)
我们知道这个区间的最小值等于它两个小区间的最小值的最小值,也就是:f[i][j]=min(f[i][j-1],f[i+2^(j-1)][j-1])!
这就是预处理的关键方程,下面上代码:
for(int i=1;i<=n;i++) f[i][0]=i; //f[i][0]就是i自己,因为这个区间是左闭右开的 for(int j=1;1<<j<=n;j++) //注意j层在外面,不然f[i][0]更新不到其他的状态,这一层是保证右边的中括号里的值在范围内 for(int i=1;i+(1<<j)-1<=n;i++) //注意减一,左闭右开!这一层是保证左边的中括号里的值在范围内 f[i][j]=min(f[i][j-1],f[i+1<<(j-1)][j-1]); //状态转移方程

解释一下为什么:
既然我们要查询[l,r]这个区间的最小值那么我们选的两个小区间取并集一定要覆盖整个[l,r]。
设len=r-l+1;t=log (len);
2^t=2^(log(len))=len>len/2;
也就是说:2^t超过了区间[l,r]的一半!
所以我们每次找[l,l+2^t]和[r-2^t+1,r]这个区间的最小值再去个min就好啦!
for(int i=1;i<=m;i++) { cin>>l>>r; int len=r-l+1; //求区间长度 int t=(int)(double)log(len)/log(2.0); //要以2为底就要加上后面的log(2.0) f[l][r]=min(f[l][t],f[r-(1<<t)+1][t]);//这是上面推出来的公式 }
这样的话,单次询问的时间复杂度就是O(1)!!!






我们就用线段树!


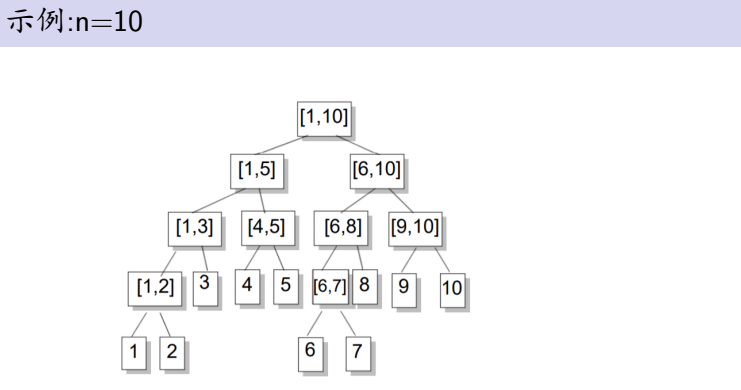
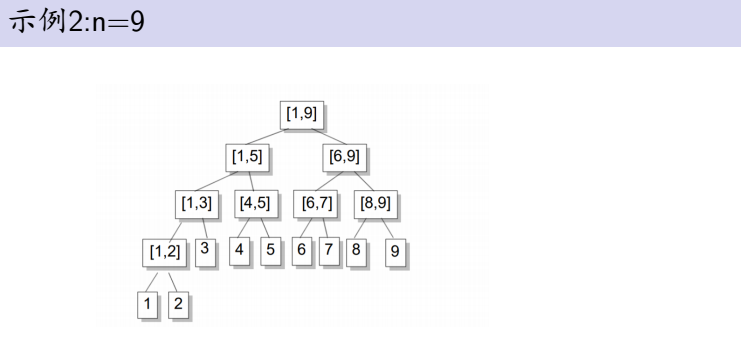
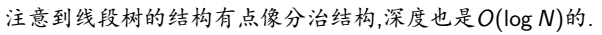


并且我们拆到了终止节点就不用继续往下拆了,因为无论再怎么往下拆还是在[l,r]里,这符合线段树的性质。
我们以n=9,求区间[2,8]里的元素为例(标红的就是答案):
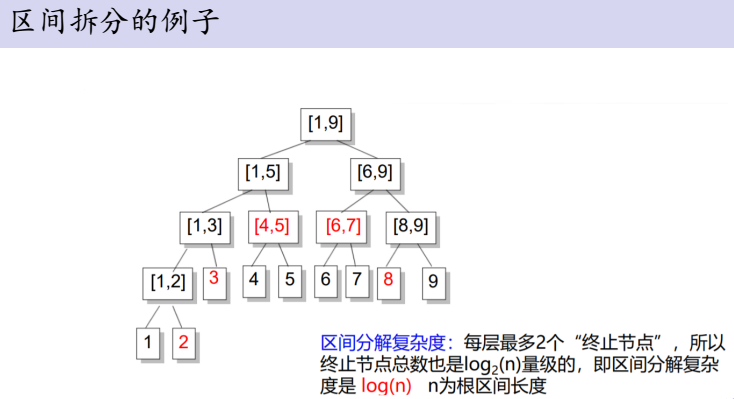

上一个单点修改的代码:
const int N=100001; int tree[N*4]; //tree数组记录区间和 void modify(int q,int c,int l,int r,int t) //这个点的权值为q,也可以看作是区间[q,q],我们要将它修改成c,当前正分解的区间是[l,r],这个点的编号为t { if(q==l&&q==r) //如果当前分解的区间正好在这个点以内(说白了就是这个点),就将这个点的权值进行修改 { tree[t]=c; //将这个点的权值修改为c return ; } int mid=(l+r)/2; //找区间中点 if(q<=mid) modify(q,c,l,mid,t*2); //如果这个点小于中点,说明在这个区间的左区间里 else modify(q,c,mid+1,r,t*2+1); //否则就在这个区间的右区间里 tree[t]=tree[t*2]+tree[t*2+1]; //将最底层的q修改后别忘了修改它的祖宗的值 }



这个题只要让每个节点记录当前区间的最大最小值就好啦!



延迟更新(懒标记)

为什么要用到这个,直接暴力递归不好吗?
问得好!
假设我们每进行一次加法或减法操作我们就要从根节点一直递归到它儿子再递归回来,这样做好像没什么问题,但是,太耗时!
我们不如将这个区间内的所有元素做上一个懒标记!(顾名思义,懒标记很懒嘛,查到它它才改,不查就不改!真是壮士!)
这个懒标记是干嘛滴呢?假设我们对一个区间进行了n次操作,每次操作都给这个区间加上Ai(i从1~n),不做懒标记的话我们就要递归n次,树一大节点一多直接T得飞起!
所以我们就给这个区间的元素做上懒标记,每次懒标记加上要加上的Ai的值,但是不往下递归,所以到n次操作后这个区间的元素的懒标记就是:A1+A2+A3……+An,这样我们一次递归加上懒标记就好啦。
举个例子:

sum是这个区间内的总和相对于初始化增加了多少,inc是这个区间的每个元素相对于初始化增加了多少。
然后我们可以进行第一步操作:让[2,7]的每个元素增加2
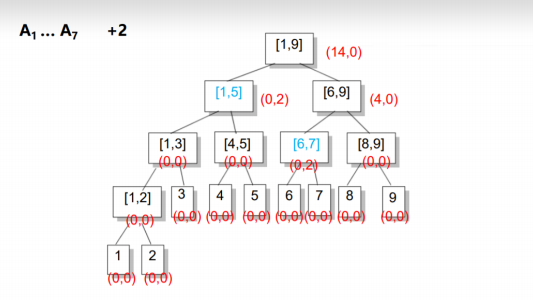
在全部的大区间[1,9]内,由于1~7都在这个区间内,所以总和相对于一开始的是增加了2*7=14,所以sum的值为14;但是[1,9]又不完全被包含在[1,7]内,所以我们不能更新inc值(看inc的定义,8和9不能+2)
因为区间[1,9]内还有元素不用+2,所以我们要继续往下找:
我们找到了区间[1,5]和区间[6,9],我们发现:区间[1,5]全部都在[1,7]内,所以区间[1,5]的inc值就可以更新为2了,sum值就是5*2=10;但是区间[6,9]还有元素不在区间[1,7]的范围内所以我们将这个区间继续往下找,同时将这个区间的sum值更新为4;
[6,9]可以分成[6,7]和[8,9],我们发现:区间[6,7]全部都在[1,7]以内,所以将区间[6,7]的inc值更新为2,sum值为2*2=4。到这步我们就发现[1,7]以内已经全部被找过了,所以我们就找完了!
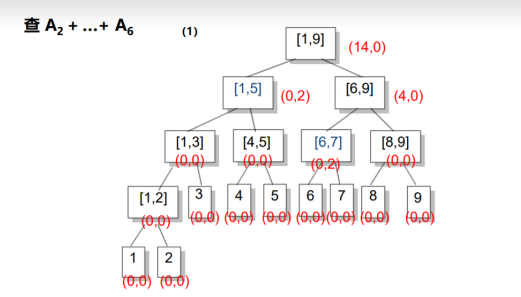
接下来我们查询[1,6]的和:
还是按照原来的思路:从根节点开始找,发现[1,9]并不完全被包含在所查区间内,所以我们就去找它的儿子;
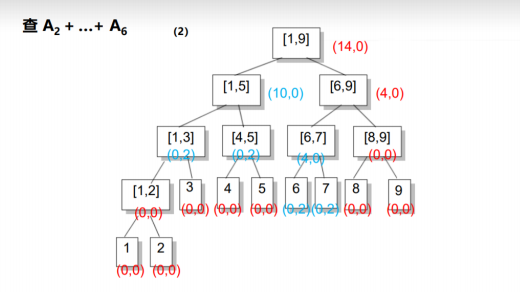
我们找到了[1,5],发现并不完全被包含在[2,6]内,所以我们继续往下找,并将inc值传给它的两个儿子;找到了[1,3]和[4,5],我们发现区间[4,5]全部被包含在内了,所以我们直接返回sum值+原区间和就好啦,sum=inc*len(区间长度)=2*2=4,但是[1,3]并不完全被包含在内,所以我们将[1,3]的inc值传给它的儿子,并继续往下找:
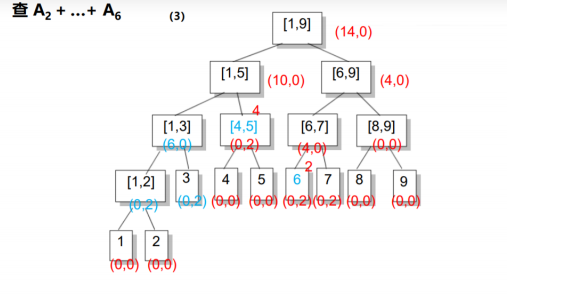
我们找到了[1,2]和区间[3,3](就是3),我们发现3完全被包含在所查区间内了,所以我们直接返回sum值+原区间和就好啦,sum=inc*len(区间长度)=2*1=2;但是区间[1,2]并不完全被包含在内,所以继续从它的儿子里面找,并将inc值传给儿子:
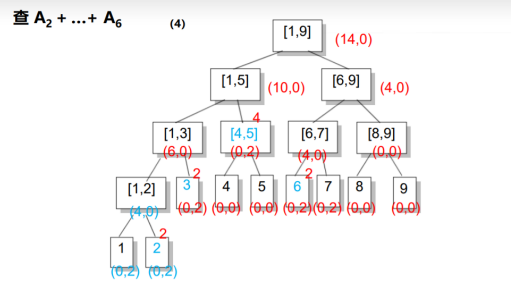
我们找到了1和2,1不在所查区间内就不管它了(不清楚懒标记inc值),我们发现2在所查区间内,所以直接返回sum值+原区间和就好啦,sum的公式就不用说了...
到这里,我们就做完了,下面附上代码:
原题请看洛谷P3372
#include<cstdio> #include<algorithm> #include<cstring> #include<iostream> #include<cstring> #include<string> #include<cmath> #include<ctime> #include<set> #include<vector> #include<map> #include<queue> #define N 1000005 #define M 1000005 #define ls (t*2) #define rs (t*2+1) #define mid ((l+r)/2) using namespace std; long long i,j,m,n,p,k,lazy[N*4],a[N],x,c,l,r; //lazy数组存每个结点的懒标记,sum数组存每个结点的区间和,注意四倍空间 long long ans,sum[N*4]; void build(int l,int r,int t) //初始化sum的值,为原先的区间和 { if (l==r) sum[t]=a[l]; //只有一个结点 else { build(l,mid,ls); //找它的左儿子 build(mid+1,r,rs); //找它的右儿子 sum[t]=sum[ls]+sum[rs]; //该结点的区间和等于它的左儿子加上它的右儿子的区间和 } } void down(int t,int len) //对lazy标记进行下传 { if (!lazy[t]) return; //如果没有lazy标记,那么直接返回 sum[ls]+=lazy[t]*(len-len/2); //求左儿子的新区间和,len-len/2是左儿子的长度 sum[rs]+=lazy[t]*(len/2); //求右儿子的新区间和,len/2是右儿子的长度 lazy[ls]+=lazy[t]; //传给左右儿子,累积lazy标记 lazy[rs]+=lazy[t]; lazy[t]=0; //父亲结点的lazy标记已经传下去了,所以要清空 } void modify(int ll,int rr,long long c,int l,int r,int t) //[ll,rr]整体加上c,当前节点代表的区间位[l,r] { if (ll<=l&&r<=rr) //如果当前分解的区间在所给的区间内 { sum[t]+=(r-l+1)*c; //对[l,r]区间的影响就是加上了(r-l+1)*c lazy[t]+=c; //加上lazy标记 } else //如果当前分解的区间未完全被包含在内的话 { down(t,r-l+1); //要往下细分就要下传lazy标记 if (ll<=mid) modify(ll,rr,c,l,mid,ls); //如果与左区间有交集,那么我们就去细分左区间 if (rr>mid) modify(ll,rr,c,mid+1,r,rs); //如果与右区间有交集,那么我们就去细分右区间 sum[t]=sum[ls]+sum[rs];//更新一下区间和 } } void ask(long long ll,long long rr,long long l,long long r,long long t) //[ll,rr]是要查询的区间,[l,r]是当前分解的区间 { if (ll<=l&&r<=rr) ans+=sum[t]; //代表着找到了完全被包含在内的一个区间,所以直接返回这个区间的区间和 else //如果有未完全被包含在内的 { down(t,r-l+1); //将lazy标记下传并继续细分它的儿子 if (ll<=mid) ask(ll,rr,l,mid,ls); //如果与左区间有交集就细分左区间 if (rr>mid) ask(ll,rr,mid+1,r,rs);//如果与右区间有交集就细分右区间 } } int main() { scanf("%d%d",&n,&m); for (i=1;i<=n;++i) scanf("%d",&a[i]); build(1,n,1); //初始化 for(long long i=1;i<=m;i++) { long long p; scanf("%lld",&p); if(p==1) //如果是1则在区间[l,r]上加上k { long long l,r,k; scanf("%lld%lld%lld",&l,&r,&k); modify(l,r,k,1,n,1); } if(p==2) //如果是2则输出区间[l,r]的和 { long long l,r; scanf("%lld%lld",&l,&r); ans=0; ask(l,r,1,n,1); printf("%lld\n",ans); } } return 0; }
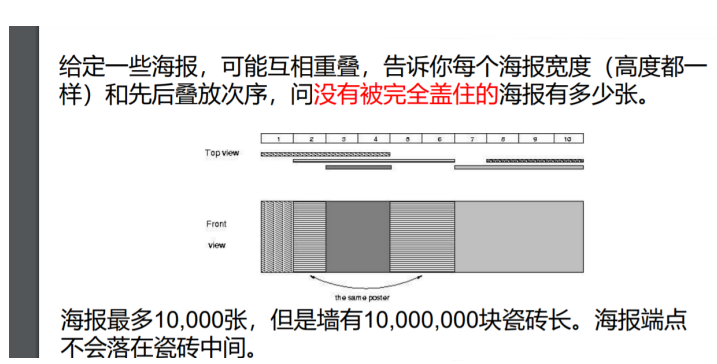
我们看有这么多砖就瞬间不想做了!

不,其实只有4w块砖。因为一共1w张海报,所以最多有2w个不同位置的端点,相邻的端点两两间可看作是一块砖。
那么我们从最底层的海报开始,一层一层往上贴。
对于一个区间[L,R],我们记录的是它被第几张海报覆盖了,一开始没有海报覆盖它,所以我们初始化它为-1;
接下来,每放上一张海报i,我们就将海报覆盖的区间[左端点横坐标xi,右端点横坐标yi]覆盖成i;
要用上延迟更新和区间分解的方法!
本题中是否会有标记时间冲突的问题?——不会,因为只有后来的海报覆盖前面的,前面的海报是不会覆盖后面的海报的。
ZYB 画画

题解

树状数组

如何求lowbit?

树状数组的定义:

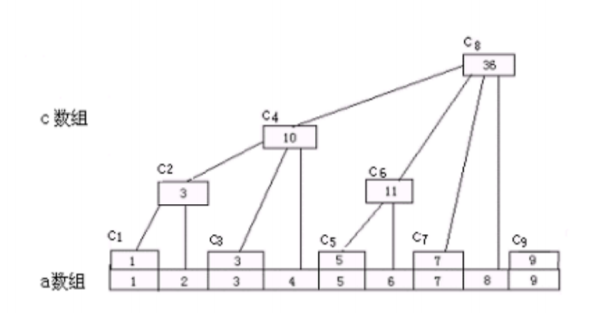
不难发现:
C[1]=A[1];
C[2]=A[1]+A[2];
C[3]=A[3];
C[4]=A[1]+A[2]+A[3]+A[4];
C[5]=A[5];
C[6]=A[5]+A[6];
C[7]=A[7];
C[8]=A[1]+A[2]+A[3]+A[4]+A[5]+A[6]+A[7]+A[8];
换成二进制:
C[1] = C[0001] = A[1];
C[2] = C[0010] = A[1]+A[2];
C[3] = C[0011] = A[3];
C[4] = C[0100] = A[1]+A[2]+A[3]+A[4];
C[5] = C[0101] = A[5];
C[6] = C[0110] = A[5]+A[6];
C[7] = C[0111] = A[7];
C[8] = C[1000] = A[1]+A[2]+A[3]+A[4]+A[5]+A[6]+A[7]+A[8];
这个结构有啥用?
树状数组用于解决单个元素经常修改,而且还反复求不同的区间和的情况。
单点更新:
继续看开始给出的图
此时如果我们要更改A[1]
则有以下需要进行同步更新
1(001) C[1]+=A[1]
lowbit(1)=001 1+lowbit(1)=2(010) C[2]+=A[1]
lowbit(2)=010 2+lowbit(2)=4(100) C[4]+=A[1]
lowbit(4)=100 4+lowbit(4)=8(1000) C[8]+=A[1]

代码如下:
1 int change(int x,int y,int n) //x是要改的那个数的位置,a[x]+=y,n是最大范围 2 { 3 for(int i=x;i<=n;i+=lowbit(i)) //根据上面的推理,每次i要加上lowbit(i) 4 c[i]+=y; 5 }
区间求和:
举个例子:i=5
C[4]=A[1]+A[2]+A[3]+A[4];
C[5]=A[5];
所以sum[5]=C[4]+C[5];
换成二进制:sum[101]=C[100]+C[101];
第一次101,减去最低位的1就是100;

代码如下:
1 int change(int x,int n) 2 { 3 for(int i=x;i;i-=lowbit(i)) //根据上面的公式,要一直用i减去它的lowbit直至为0 4 sum+=c[i]; 5 return sum; 6 }
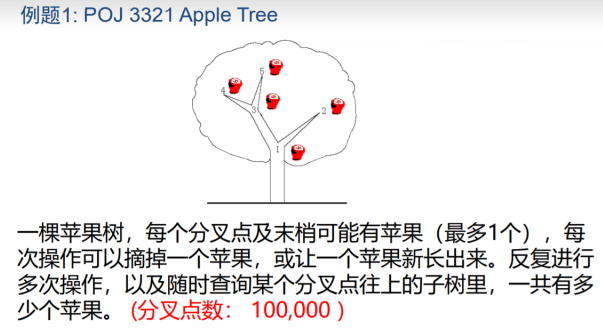


求一个数组A1, A2, ..., An的逆序对数n ≤ 100000, |Ai| ≤ 10^9
题解
我们将A1, ..., An按照大小关系变成1...n.这样数字的大小范围在[1, n]中。维护一个数组Bi,表示现在有多少个数的大小正好是i。从左往右扫描每个数,对于Ai,累加BAi+1...Bn的和,同时将BAi加1。时间复杂度为O(N log N)
4.并查集
简单的例题
有N个人,有m次操作,操作分为以下两种:
1.声明x和y是同一性别.
2.询问是否能够确定x和y是同一性别.
N, M ≤ 1000000.
题解
如果事先声明了所有的关系,然后再询问.
那我们只需要把每个联通块预处理出来就行了.
但是这道题里涉及动态的维护.

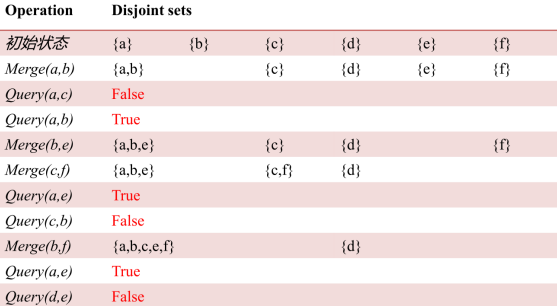
操作示例:
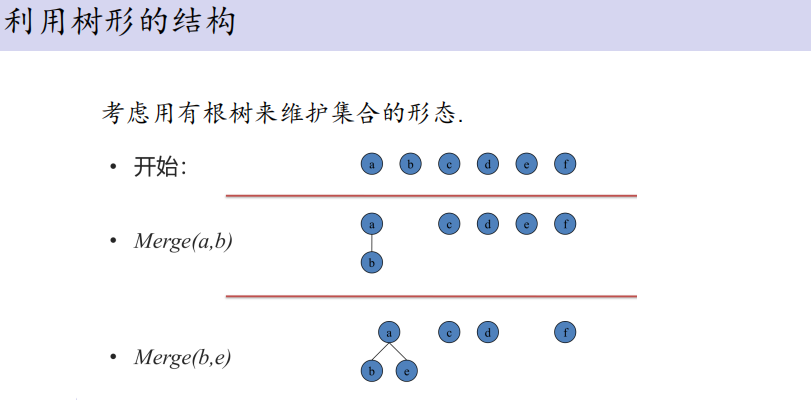
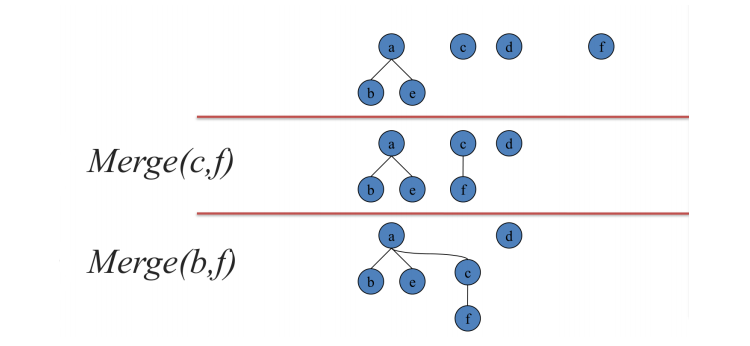
算法基础:



暴力求树根的代码:
int getroot(int x) { if(fa[x]==x) return x; //如果fa[x]==x说明x就是树根,直接返回树根 else return getroot(fa[x]); //否则就往上找,直至找到树根 }

因为下次访问的话,如果找到了a会找到b,然后再找到b的根,所以说我们直接将a接到b的根下不就能找到a后一下就找到了b的根。


int getroot(int x) { if(fa[x]!=x) fa[x]=getroot(fa[x]); //如果x有父亲就一直往上找直至找到祖宗 return fa[x]; //返回祖宗结点 }

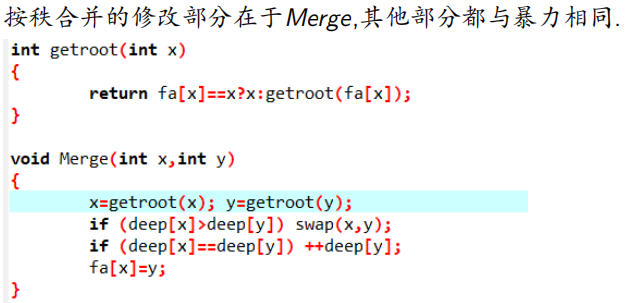
比较
无论是时间,空间,还是代码复杂度,路径压缩都比按秩合并优秀.值得注意的是,路径压缩中,复杂度只是N次操作的总复杂度为O(N log N)。按秩合并每一次的复杂度都是严格O(log N)的.两种方式可以一起用,复杂度会降的。


So1:

So2:

解题关键
在Getroot和Merge时维护关键的信息。
另外一些题需要比较巧妙的建图方法。






但是这样好像很慢,尤其是len层数特别大的时候,那怎么呢?我们在用倍增法:


这个实际上是用了二分的思想吧,说下思路:
第一步和之前一样,也是将x和y跳到同一层上;
然后我们用一个grand[x][i]数组来表示编号为x的结点向上跳了2^i层后的结点编号,那么grand[x][0]就是x的父亲结点对吧(因为2^0是1,那么意思就是x向上跳了一层)
那么对于一般的结点,都有grand[x][i]=grand[grand[x][i-1]][i-1]
正常学生:这……跨度有点大吧!
没错,这确实跨度有点大,老师刚开始就这么讲还不仔细解释一番,听不懂怪我喽!
但是,既然你都已经看过来了,我肯定会仔细滴讲给你听啦:
先考虑一下这个问题:2^i=2^(i-1+1)=2^[(i-1)+1]=2^(i-1)*2=2^(i-1)+2^(i-1) 别说你看不懂这个,这不是初中学的嘛?
换句话说,你直接往上跳2^i层和先跳2^(i-1)层再跳2^(i-1)层是一样的
那么我们分别将两种方式表达出来,它们是相等的:
直接跳2^i层: grand[x][i]
分两步跳: 跳完一次后,此时所在的结点是grand[x][i-1],没错吧;接下来把那一坨式子看做一个整体,如果整体感差的话你可以换元换成a
那么第二次跳后所在的结点就是:grand[a][i-1],把a换过去就是grand[ grand[x][i-1] ][i-1](换个颜色更直观)
两个式子做等号,就是上面的式子:grand[x][i]=grand[grand[x][i-1]][i-1]
有木有感觉突然明白啦?什么,没有。。。。好吧我收回刚才的话qwq
水一发洛谷LCA模板题解:
#include<iostream> #include<cstdio> #include<cstring> using namespace std; const int maxn=500001; int head[2*maxn],to[2*maxn],next[2*maxn],grand[2*maxn][21],dep[maxn]; //注意开两倍大小的数组,因为这个图是无向图 //head[i]是存以i结点为起点的最后一条出边的编号 //to[i]数组是存第i条边的终点 //next[i]是存以i结点为起点的所有出边中的倒数第二条出边的编号,其实也就是head[i]的上一条边 int n,m,s,edge_sum=0; //edge_sum记录边数 void add(int x,int y) //用链式前向星(链表)建图 { next[++edge_sum]=head[x]; //根据我们定义的head与next的含义得出 head[x]=edge_sum; //有新的边加入,则将head[x]内的值更新 to[edge_sum]=y; //当前边的终点是y } void dfs(int v,int deep) { dep[v]=deep; //记录v结点的深度 for(int i=head[v];i>0;i=next[i]) //后序访问v的所有出边 { int u=to[i]; //u记录当前边的终点,也就是说u是v的儿子 if(!dep[u]) dfs(u,deep+1),grand[u][0]=v; //如果该儿子u的深度没被更新,则更新它,并记录u的父亲是v } } int lca(int x,int y) { if(dep[x]<dep[y]) swap(x,y); //我们让x是深度最大的那个 for(int i=20;i>=0;i--) if(dep[y]<=dep[x]-(1<<i)) x=grand[x][i]; //让x和y跳到同一层上 if(x==y) return y; //如果跳到同一点上了,说明这个点就是最近公共祖先 for(int i=20;i>=0;i--) //倍增找最近公共祖先 { if(grand[x][i]!=grand[y][i]) //如果跳不到公共祖先,那就往上跳 { x=grand[x][i]; //将x和y往上跳 y=grand[y][i]; } } return grand[x][0]; //因为我们只要求跳不到同一点就往上跳,所以这样操作之后它们再往上跳一层也就是它们的最近公共祖先了 } int read() //快读 { char ch=getchar(); int a=0; while(ch<'0'||ch>'9') ch=getchar(); while(ch>='0'&&ch<='9') { a=a*10+(ch-'0'); ch=getchar(); } return a; } int main() { memset(head,0,sizeof(head)); //head数组初始化,好像可以去掉 n=read(),m=read(),s=read(); //这个题数据那么大,快读优化下 for(int i=1;i<n;i++) //n-1条边 { int x=read(),y=read(); add(x,y); //题目中给的是无向图,所以也要反过来建一次 add(y,x); } grand[s][0]=s; //设起点s的父亲就是自己 dfs(s,1); //从深度为1的起点开始深搜 for(int i=1;(1<<i)<=n;i++) //利用状态转移方程计算出每个点的grand值 for(int j=1;j<=n;j++) grand[j][i]=grand[grand[j][i-1]][i-1]; for(int i=1;i<=m;i++) //m次询问 { int x=read(),y=read(); printf("%d\n",lca(x,y)); } return 0; }

总结

完结撒花,终于补完了qwq!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号