
最近在研究把业务数据抽到Hive,原本想使用Sqoop抽取,后来发现Sqoop不够灵活,可能是我了解不深,但目前感觉在增量抽取上有些无奈,对于那些需于其他表关联且增量字段从其他表中取时,我到时没有找到sqoop的实现方式,于是寻找其他工具替代,发现DataX似乎是不错的选择,如果有特殊的地方还能自己开发。
1.下载安装
安装很简单,从github上下载编译好的就能用,下载地址:
https://github.com/alibaba/DataX/blob/master/userGuid.md
放在服务器上:
[hadoop@FineReportAppServer bin]$ pwd
/home/hadoop/datax/datax/bin
2.初步使用
在以往的数仓使用中,由于卸数工具的限制,经常出现回车换行导致的入仓失败,所以如果不能处理回车换行的工具不是好工具。
于是在数据库里插入了两条数据,其中一条是带回车换行的
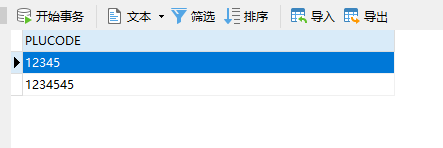
从navicat复制出来可以看到是带回车的
写了个sql生成json文件内容(只是以后拿来改方便,每个插件的json配置与说明在相应的目录里有各自的文件说明和模板):
select '{'
||'"job":{'
|| '"content":['
|| '{'
|| '"reader":{'
|| '"name":'||'"oraclereader"'||','
|| '"parameter":{'
|| '"column":['
|| wm_concat('"'||column_name||'"')
|| '],'
|| '"connection":['
|| '{'
|| '"jdbcUrl": ["jdbc:oracle:thin:@192.168.xxxx.xxx:1521:xxx"],'
|| '"table": ["'||table_name||'"]'
|| '}'
|| '],'
|| '"username": "xxx",'
|| '"password": "xxx",'
|| '}'
|| '},'
|| '"writer":{'
|| '"name":'||'"hdfswriter"'||','
|| '"parameter":{'
|| '"defaultFS": "hdfs://192.168.0.143:9000",'
|| '"fileType": "TEXT",'
|| '"path": "/DATA/ODS/'||upper(table_name)||'",'
|| '"fileName": "hdfswriter",'
|| '"column": ['
|| wm_concat('{"name":"'||column_name||'","type":"'|| decode(data_type,'NUMBER', 'double','varchar')||'"}')
|| '],'
|| '"writeMode": "append",'
|| '"fieldDelimiter": ","'
|| '},'
|| '"writeMode": "append",'
|| '}'
|| '}'
|| '],'
|| '"setting":{'
|| '"speed": {'
|| '"channel": "2"'
|| '}'
|| '}'
|| '}'
|| '}'
from dba_tab_columns where owner ='xxx' and table_name ='AAA' group by table_name
放到服务器上运行:
python datax.py ~/DataXJsonConfig/DRP/aaa.json
运行后把文件get一下打开
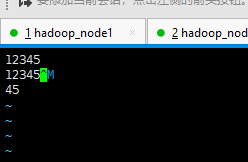
可以看到里面有个^M,这个东西就是回车换行,如果用notepad++打开(设置为view->show symbol->show all characters)会发现有个黑色的crlf,cr是\r,lf是\n,那么\r\n就是windows的回车换行了,很显然读到hdfs里DataX并没有把它去掉。
3.修改插件
首先git clone下代码,找到hdfswriter插件修改
public static MutablePair<List<Object>, Boolean> transportOneRecord(
Record record,List<Configuration> columnsConfiguration,
TaskPluginCollector taskPluginCollector){
MutablePair<List<Object>, Boolean> transportResult = new MutablePair<List<Object>, Boolean>();
transportResult.setRight(false);
List<Object> recordList = Lists.newArrayList();
int recordLength = record.getColumnNumber();
if (0 != recordLength) {
Column column;
for (int i = 0; i < recordLength; i++) {
column = record.getColumn(i);
//todo as method
if (null != column.getRawData()) {
String rowData = column.getRawData().toString();
//增加回车换行处理
rowData = rowData.replaceAll("\\\r\n|\\\r|\\\n","");
SupportHiveDataType columnType = SupportHiveDataType.valueOf(
columnsConfiguration.get(i).getString(Key.TYPE).toUpperCase());
//根据writer端类型配置做类型转换
try {
switch (columnType) {
case TINYINT:
recordList.add(Byte.valueOf(rowData));
break;
case SMALLINT:
recordList.add(Short.valueOf(rowData));
break;
case INT:
recordList.add(Integer.valueOf(rowData));
break;
case BIGINT:
recordList.add(Long.valueOf(rowData));
break;
case FLOAT:
recordList.add(Float.valueOf(rowData));
break;
case DOUBLE:
recordList.add(Double.valueOf(rowData));
break;
case STRING:
case VARCHAR:
case CHAR:
recordList.add(rowData);
break;
case BOOLEAN:
recordList.add(Boolean.valueOf(rowData));
break;
case DATE:
recordList.add(new java.sql.Date(column.asDate().getTime()));
break;
case TIMESTAMP:
recordList.add(new java.sql.Timestamp(column.asDate().getTime()));
break;
default:
throw DataXException
.asDataXException(
HdfsWriterErrorCode.ILLEGAL_VALUE,
String.format(
"您的配置文件中的列配置信息有误. 因为DataX 不支持数据库写入这种字段类型. 字段名:[%s], 字段类型:[%d]. 请修改表中该字段的类型或者不同步该字段.",
columnsConfiguration.get(i).getString(Key.NAME),
columnsConfiguration.get(i).getString(Key.TYPE)));
}
} catch (Exception e) {
// warn: 此处认为脏数据
String message = String.format(
"字段类型转换错误:你目标字段为[%s]类型,实际字段值为[%s].",
columnsConfiguration.get(i).getString(Key.TYPE), column.getRawData().toString());
taskPluginCollector.collectDirtyRecord(record, message);
transportResult.setRight(true);
break;
}
}else {
// warn: it's all ok if nullFormat is null
recordList.add(null);
}
}
}
transportResult.setLeft(recordList);
return transportResult;
}
修改DataX目录下的pom.xml文件,将不需要编译的插件模块去掉,最后剩余的模块如下:
<modules>
<module>common</module>
<module>core</module>
<module>transformer</module>
<!-- writer -->
<module>hdfswriter</module>
<!-- common support module -->
<module>plugin-rdbms-util</module>
<module>plugin-unstructured-storage-util</module>
<module>hbase20xsqlreader</module>
<module>hbase20xsqlwriter</module>
<module>kuduwriter</module>
</modules>
编译肯定会包jar包缺少的,但是也没有想象中的那么难,缺少哪个jar包就从网上下载下来丢到本地的mvn仓库里,jar可以从这里下载:https://public.nexus.pentaho.org/
编译成功:
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary for datax-all 0.0.1-SNAPSHOT:
[INFO]
[INFO] datax-all .......................................... SUCCESS [ 38.236 s]
[INFO] datax-common ....................................... SUCCESS [ 4.546 s]
[INFO] datax-transformer .................................. SUCCESS [ 2.832 s]
[INFO] datax-core ......................................... SUCCESS [ 6.477 s]
[INFO] plugin-unstructured-storage-util ................... SUCCESS [ 2.426 s]
[INFO] hdfswriter ......................................... SUCCESS [ 22.557 s]
[INFO] plugin-rdbms-util .................................. SUCCESS [ 2.616 s]
[INFO] hbase20xsqlreader .................................. SUCCESS [ 2.667 s]
[INFO] hbase20xsqlwriter .................................. SUCCESS [ 2.050 s]
[INFO] kuduwriter ......................................... SUCCESS [ 2.231 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:27 min
[INFO] Finished at: 2021-04-13T20:35:42+08:00
[INFO] ------------------------------------------------------------------------
替换掉服务器上的插件文件
4.重新调用
[hadoop@FineReportAppServer bin]$ python datax.py ~/DataXJsonConfig/DRP/aaa.json
'''
'''省略
'''
2021-04-13 20:36:58.575 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2021-04-13 20:36:58.682 [job-0] INFO JobContainer -
[total cpu info] =>
averageCpu | maxDeltaCpu | minDeltaCpu
-1.00% | -1.00% | -1.00%
[total gc info] =>
NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime
PS MarkSweep | 1 | 1 | 1 | 0.043s | 0.043s | 0.043s
PS Scavenge | 1 | 1 | 1 | 0.018s | 0.018s | 0.018s
2021-04-13 20:36:58.683 [job-0] INFO JobContainer - PerfTrace not enable!
2021-04-13 20:36:58.684 [job-0] INFO StandAloneJobContainerCommunicator - Total 2 records, 14 bytes | Speed 1B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2021-04-13 20:36:58.687 [job-0] INFO JobContainer -
任务启动时刻 : 2021-04-13 20:36:46
任务结束时刻 : 2021-04-13 20:36:58
任务总计耗时 : 12s
任务平均流量 : 1B/s
记录写入速度 : 0rec/s
读出记录总数 : 2
读写失败总数 : 0
读取hive:
hive (ods)> select * from aaa;
OK
aaa.plucode
12345
1234545
Time taken: 0.077 seconds, Fetched: 2 row(s)
参考:https://blog.csdn.net/weixin_43320617/article/details/109387903
https://blog.csdn.net/u013868665/article/details/79971419?utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-1.control&dist_request_id=1331647.793.16183179675246397&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromMachineLearnPai2~default-1.control

 浙公网安备 33010602011771号
浙公网安备 33010602011771号