
Trie树
参考:https://blog.csdn.net/johnny901114/article/details/80711441
1.什么是Trie?
Trie又称字典树,单词查找树。它的查找速度主要和字符串长度有关。
Trie字典树主要用于存储字符串,Trie 的每个 Node 保存一个字符。用链表来描述的话,就是一个字符串就是一个链表。每个Node都保存了它的所有子节点。
例如我们往字典树中插入see、pain、paint三个单词,Trie字典树如下所示:
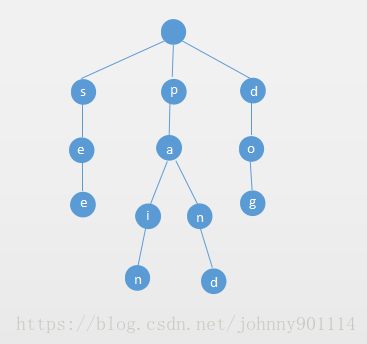
2.特点:
1>共享字符串的公共前缀来节省空间。
2>根节点root不存数据,每一整个分支代表一个字符串。
3>每个分支的内部可能也含有完整的字符串,所以我们可以对于那些是某个字符串结尾的节点做一个标记(isWord=true/false)。
3.实现:
1 /** 2 * 3 */ 4 package trie; 5 6 import java.util.HashMap; 7 import java.util.Map; 8 9 /** 10 * @author Administrator 11 * 12 */ 13 public class Trie { 14 private Node root; 15 private int size;//单词的个数 16 17 private class Node{ 18 public boolean isWord; 19 public Map<Character,Node> next; 20 21 public Node(){ 22 next=new HashMap<>(); 23 } 24 25 public Node(boolean isWord){ 26 this(); 27 this.isWord=isWord; 28 } 29 } 30 31 public Trie(){ 32 root = new Node(); 33 } 34 public int getSize(){//获取 35 return size; 36 } 37 public boolean isEmpty(){ 38 return size==0; 39 } 40 /** 41 * 往Trie添加一个单词 42 * @param word 单词 43 */ 44 public void add(String word){ 45 Node current=root; 46 char[] charArray = word.toCharArray(); 47 for (char c : charArray) { 48 Node next = current.next.get(c); 49 if(next==null){ 50 current.next.put(c, next); 51 } 52 current=next; 53 } 54 if(!current.isWord){//如果当前node已经是一个word,则跳过 55 size++; 56 current.isWord=true; 57 } 58 } 59 /** 60 * 判断Trie中是否包含单词 61 * @param word 62 * @return true/false 63 */ 64 public boolean contains(String word){ 65 Node current = root; 66 char[] charArray = word.toCharArray(); 67 for (char c : charArray) { 68 Node next = current.next.get(c); 69 if(next==null){ 70 return false; 71 } 72 current=next; 73 } 74 return current.isWord; 75 } 76 /** 77 * 判断Trie中是否包含前缀 78 * @param prefix 79 * @return true/false 80 */ 81 public boolean containsPrefix(String prefix){ 82 Node current = root; 83 char[] charArray = prefix.toCharArray(); 84 for (char c : charArray) { 85 Node next = current.next.get(c); 86 if(next==null){ 87 return false; 88 } 89 current=next; 90 } 91 return true; 92 } 93 /** 94 * 删除一个单词 95 * 1:如果单词的所有字母的都没有多个分支,删除整个单词 96 * 2:如果单词是另一个单词的前缀,只需要把该word的最后一个节点的isWord的改成false 97 * 3:如果单词的除了最后一个字母,其他的字母有多个分支 98 * @param word 99 * @return true/false 100 */ 101 public boolean remove(String word){ 102 Node current = root; 103 Node multiChildNode = null; 104 int multiChildNodeIndex = -1; 105 char[] charArray = word.toCharArray(); 106 for (int i=0; i<charArray.length; i++) { 107 Node child = current.next.get(charArray[i]); 108 //如果Trie中不存在该单词 109 if(child==null){ 110 return false; 111 } 112 //如果当前节点的子节点个数大于1个 113 if(child.next.size() >1 ){ 114 multiChildNode=child; 115 multiChildNodeIndex=i; 116 } 117 current=child; 118 } 119 //情况1:单词的所有字母都没有多余分支(分支都只有1个),则删除整个单词 120 if(multiChildNodeIndex == -1){ 121 root.next.remove(charArray[0]); 122 size--; 123 return true; 124 } 125 //情况2:如果单词后面还有子节点 126 if(current.next.size() > 0){ 127 //如果当前节点的isWord为true 128 if(current.isWord){ 129 current.isWord=false; 130 size--; 131 return true; 132 } 133 //否则,不存在该单词,该单词只是前缀 134 return false; 135 } 136 //情况3:如果单词的字母除了最后一个没有分支,其他字母存在分支 137 if(multiChildNodeIndex != charArray.length-1){//multiChildNodeIndex == -1 已经做过判断,这里 multiChildNodeIndex!=-1 138 multiChildNode.next .remove(charArray[multiChildNodeIndex+1]); 139 size--; 140 return true; 141 } 142 return false; 143 } 144 }
4.应用:
1>Trie 最大的特点就是利用了字符串的公共前缀,像我们有时候在百度、谷歌输入某个关键字的时候,它会给我们列举出很多相关的信息
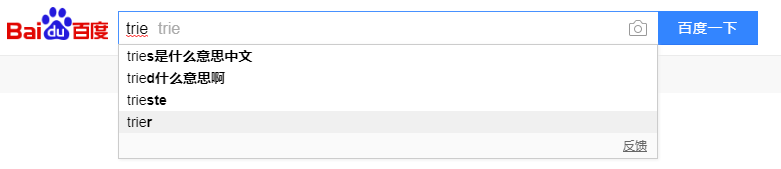
这种就是通过Trie实现的。
2>Trie 树来实现敏感词过滤
5.时间复杂度:
如果敏感词的长度为 m,则每个敏感词的查找时间复杂度是 O(m),字符串的长度为 n,我们需要遍历 n 遍,所以敏感词查找这个过程的时间复杂度是 O(n * m)。
如果有 t 个敏感词的话,构建 trie 树的时间复杂度是 O(t * m)。

