

网络评论方面级观点挖掘方法研究综述(软件学报)
网络评论方面级观点挖掘方法研究综述(软件学报)
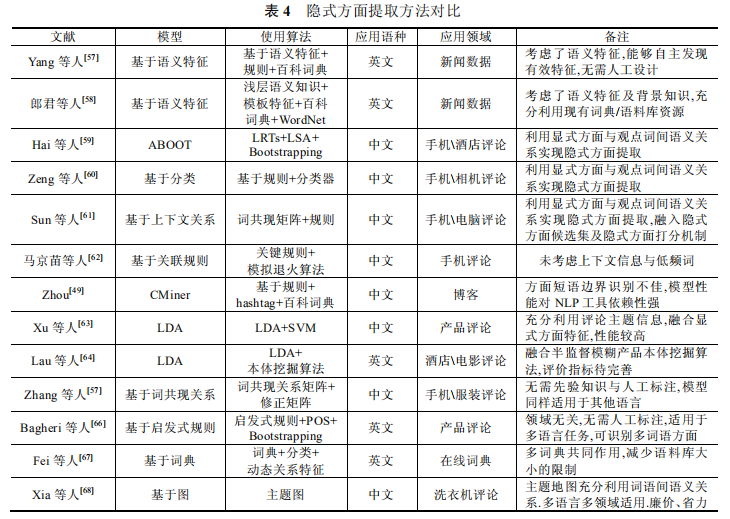
2、方面提取
- 隐式方面提取
3、基于方面的观点内容提取
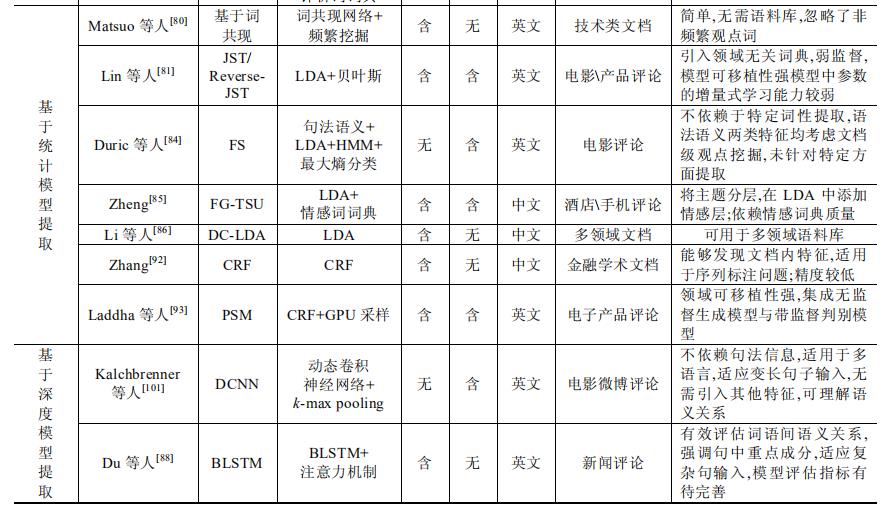
观点内容提取方法主要可分为 3 类:基于规则提取、基于统计模型提取和基于深度模型提取。
- 3.1 基于规则提取
基本思想是:对大量评论语料进行预处理并进行词频统计,然后对统计结果挖掘出一定的频繁特征与规则,利用该规则对大量评论文本进行观点词语提取。随后,基于词典的方法也相继被开发使用,以 WordNet 与 HowNet(www.keenage.com)为代表的观点词典已被众多研究者们广泛使用。
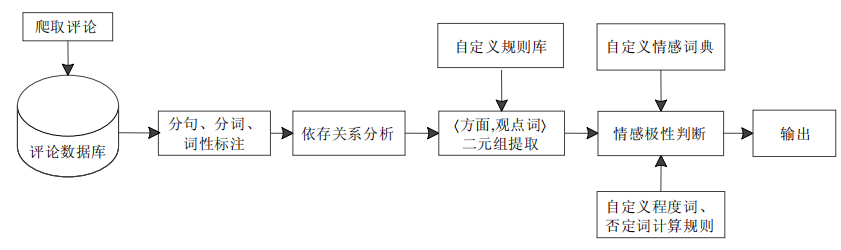
为了免去大量人工标注工作,不少学者利用句法依存关系来对观点内容进行提取,基于句法依存关系的观点提取基本流程如图所示:首先,从网络获取评论数据,对其进行分句、分词及词性标注等预处理工作;然后进行依存分析,利用人工定义的规则库对分析结果进行〈方面,观点词〉二元组提取;最后,利用情感词典、程度副词词典及否定词规则对二元组中的观点词进行情感倾向性判别.
- 3.2 基于统计模型提取
在大多数统计模型框架中,基于方面的观点内容提取被认作是序列标记问题:传统的序列标记方法为 B-I-O 标记,B 代表目标片段的开端,I 代表目标片段中剩下的部分,O 则表示原句中不在目标片段中的词。目前,基于统计模型的关键片段提取技术比较成功的模型依然是基于CRF 的模型或加入马尔可夫假设的条件随机场变体。
- 3.3 基于深度模型提取
近几年来,深度学习对自然语言处理领域的技术发展无疑起到了强有力的推进作用.深度学习模型的关键优势在于:其能够对大量原始数据中的潜在特征进行自动学习,同时用分布式向量加以表示,而不是人工手动设计特征,这在自然语言处理的众多任务中都远强过基于 CRF 的模型.在众多深度学习方法中,递归神经网络(recursive neural network,简称 RNN)与卷积神经网络(convolutional neutral network,简称 CNN)脱颖而出。
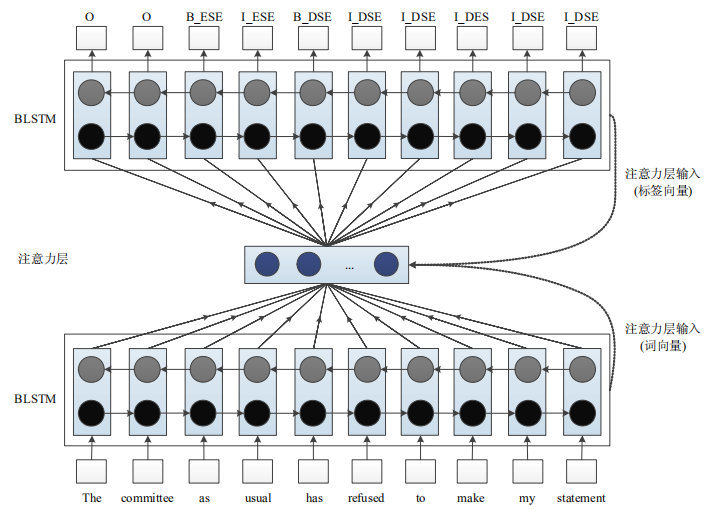
基于 LSTM 框架,Du等人探索出一种基于注意力机制的 RNN 模型来进行观点片段提取任务.模型由两层 BLSTM 网络组合而成.该模型能够分析文本中的关键片段,同时能够用标签“DSE”“BSE”标注过的文本进行句中词语关联性评估.在数据集 MPQA[104]上的实验结果表明:这种模型能够在复杂句上实现关键片段提取任务,召回率可达 74.89%,远高于对比模型——条件随机场模型,网络结构如图所示。
基于注意力机制的两层双向 LSTM 网络结构
总体而言,基于规则的提取方法相对简单易行,但大多数基于规则的提取方法结果仅为情感词,而不是观点内容,这样不利于对相对复杂的句子进行观点挖掘;基于统计模型的观点内容提取方法最终精确度较高,但需人工筛选特征集,且模型对人工选择的细致性有较强的依赖性;由于深度模型的端到端架构,基于深度网络提取的方法体现出自动学习特征的特性,减少大量的人工干预,且精度较高,但美中不足的是,深度模型的性能对网络参数较为敏感,如何快速、有效地调节参数仍是一个令研究者头疼的问题。
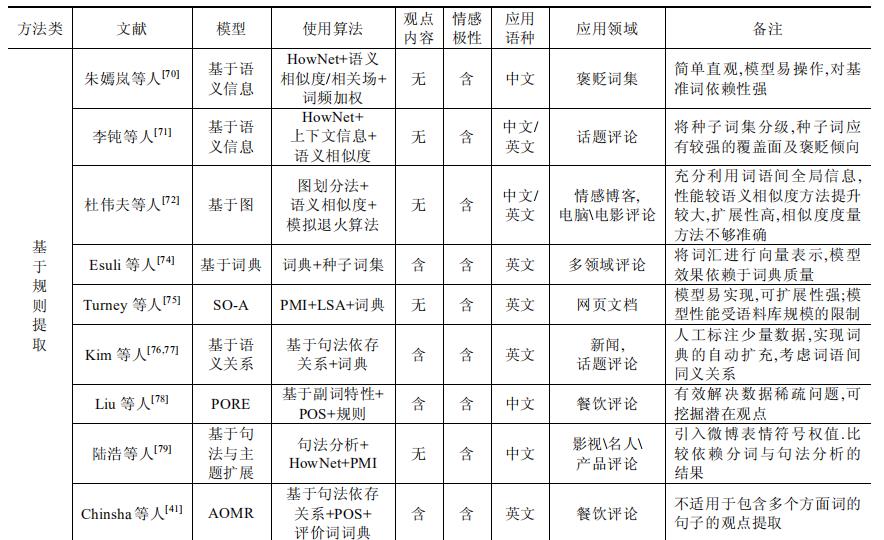
3 类方法各有利弊,详细说明可见表:
4 方面级观点挖掘的评价与应用
- 4.1 评价方法
-
4.1.1 方面提取评价方法
观点句中的方面通常为单个词的形式,因此,通常选用直接与标注对比计数的方式;同时,选取精确率(precision)、召回率(recall)和 F1 度量值来评价模型整体性能。
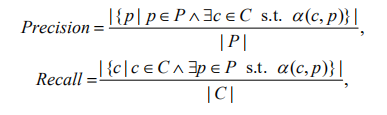
令 C 与 P 分别表示人工标注的真正短语集合与模型输出短语集合,c 与 p 分别表示每个标注短语与模型相应输出短语。在此处的方面提取中,由于目标短语与输出短语通常为单个词,因此,C 与 P 可分别看作方面单词的集合。
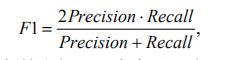
其中,s.t. α(c,p)表示约束条件:标签短语 c 与输出短语 p 完全匹配(短语间的完全匹配意为两个短语中的单词逐个对应相同,此处可看作是两个单词相同),“|⋅|”表示计算符合要求的短语数量。 -
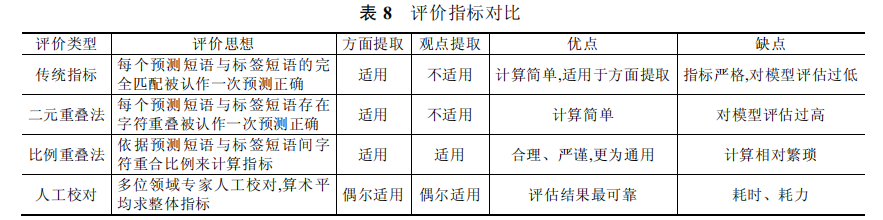
4.1.2 观点内容提取评价方法
5 面临的挑战与研究方向


