服务器CPU负载过高,如何定位问题
原文地址:https://www.jianshu.com/p/45c6bcb85934
一、排查 CPU 故障的常用命令
- top:Linux 命令。可以实时查看各个进程的 CPU 使用情况。也可以查看最近一段时间的 CPU 使用情况。默认按 CPU 使用率排序。
- ps:Linux 命令。强大的进程状态监控命令。可以查看进程以及进程中线程的当前 CPU 使用情况。属于当前状态的采样数据。
- jstack:Java 提供的命令。可以查看某个进程的当前线程栈运行情况。根据这个命令的输出可以定位某个进程的所有线程的当前运行状态、运行代码,以及是否死锁等等。
- pstack:Linux 命令。可以查看某个进程的当前线程栈运行情况。
二、应用负载高的时候怎么办?
一个应用占用 CPU 很高,除了确实是计算密集型应用之外,通常原因都是出现了死循环。CPU 负载过高解决问题过程:
-
使用【top】命令定位异常进程,可发现 PID 为 12836 的 CPU 和内存占用率都非常高:
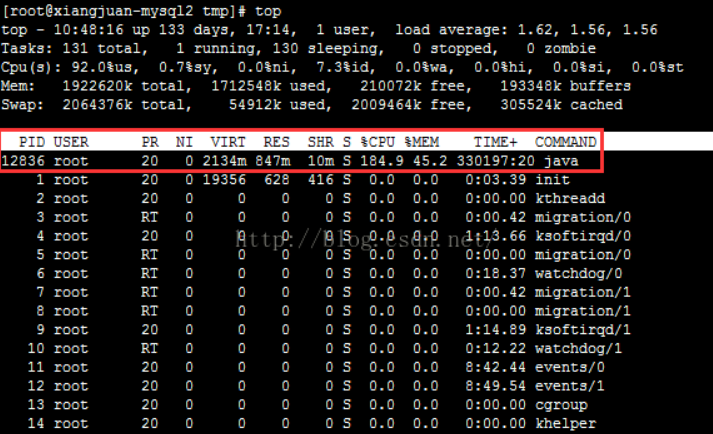
备注: top 命令默认每 3 秒刷新一次。可以通过top -d <刷新时间间隔>来指定刷新频率,如top -d 0.1或top -d 0.01等。top 执行时,也可以按“s”键,修改时间间隔。
- 使用
top -Hp PID查看该 PID 对应进程下各个线程的 CPU 使用情况:
PID(Process Identification)操作系统里指进程识别号,也就是进程标识符。操作系统里每打开一个程序都会创建一个进程 ID,即 PID。PID 是各进程的代号,每个进程有唯一的 PID 编号。它是进程运行时系统分配的,并不代表专门的进程。在运行时 PID 是不会改变标识符的,但是进程终止后 PID 标识符就会被系统回收,就可能会被继续分配给新运行的程序。
- 使用【printf "%x\n" 线程号】将异常线程号转化为 16 进制

-
使用【jstack 进程号|grep 16进制异常线程号 -A90】来定位异常代码的位置(最后的-A90是日志行数,也可以输出为文本文件或使用其他数字)。可以看到异常代码的位置:
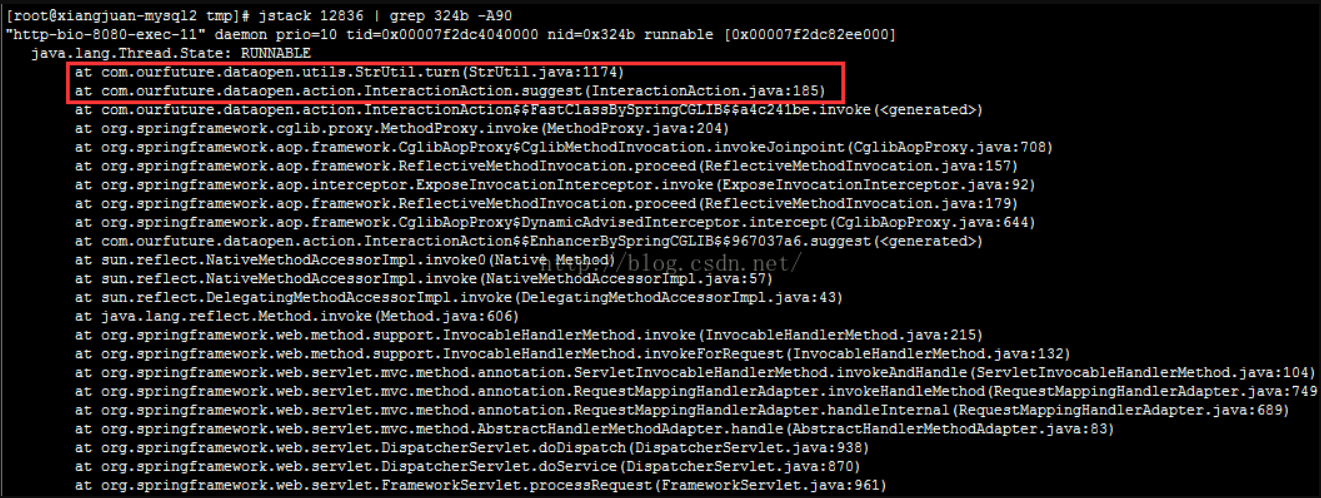


找到相应代码检查,发现确实有死循环存在。
三、什么场景会造成 CPU 低而负载确很高呢?
负载总结为一句话就是:需要运行处理但又必须等待队列前的进程处理完成的进程个数。具体来说,也就是如下两种情况:
等待被授权予 CPU 运行权限的进程、等待磁盘 I/O 完成的进程。
CPU 低而负载高也就是说等待磁盘 I/O 完成的进程过多,就会导致队列长度过大,这样就体现到负载过大了,但实际是此时 CPU 被分配去执行别的任务或空闲,具体场景有如下几种:
①数据库抖动,造成线程队列 hang 住,负载升高
②磁盘读写请求过多就会导致大量 I/O 等待。CPU 的工作效率要高于磁盘,而进程在 CPU 上面运行需要访问磁盘文件,这个时候 CPU 会向内核发起调用文件的请求,让内核去磁盘取文件,这个时候会切换到其他进程或者空闲,这个任务就会转换为不可中断睡眠状态。当这种读写请求过多就会导致不可中断睡眠状态的进程过多,从而导致负载高,CPU 低的情况。
③外接硬盘故障,常见有挂了 NFS,但是 NFS server 故障
比如系统挂载了外接硬盘如 NFS 共享存储,经常会有大量的读写请求去访问 NFS 存储的文件,如果这个时候 NFS Server 故障,那么就会导致进程读写请求一直获取不到资源,从而进程一直是不可中断状态,造成负载很高。
四、监控发现线上机器内存占用率居高不下,如何分析进行优化?
- 使用
top -p pid针对所要查的 pid 查看该进程的 CPU 和内存以及负载情况。 -
jmap -histo:live [pid],然后分析具体的对象数目和占用内存大小,从而定位代码。 -
jmap -dump:live,format=b,file=xxx.xxx [pid],然后利用 MAT 工具分析是否存在内存泄漏等等。

