打造自己的ChatGPT:OpenAI的API接入技巧
打造自己的ChatGPT:OpenAI 的API接入技巧
2023年3月更新
OpenAI 在3月1日的时候放出了ChatGPT的接口,新的接口可以使用 GPT-3.5 模型,同时接口参数更新为了 messages 的结构,更符合对话场景的消息格式,而且价格也更加便宜。
由于其他的接口参数变化不大,同时返回的消息格式没有发生变化,所以只需要对请求格式,直接按照messages的格式进行整理之后,变更接口和模型,就可以方便的替换之前接入的completions的接口。
值得推荐 👍👍👍
简介
🤖:OpenAI 的API提供了一系列的人工智能模型,包括 GPT-3、GPT-2 和 GPT-1,可以帮助开发者利用机器学习和深度学习的技术快速实现文本理解和生成。OpenAI API 拥有强大的自然语言处理功能,可以帮助开发者实现各种自然语言处理任务,包括语义理解、文本生成、文本分类等.
对于每个想尝试使用OpenAI API 开发自己的ChatGPT的开发者来说,可能对会面临一个问题,都是对接的同一套的API,为什么我得到的输出和想象的完全不一样呢。
这其中最主要的问题就在于对于接口的理解。
理解接口
OpenAI API的核心在于 completions 接口,用户提供 prompt,API返回文本completion,这一来一回就构成的对于用户需求的应答。
所以作为开发者,在尝试的接入该接口的时候,就会默认认为和ChatGPT的效果一样,直接将聊天的内容作为prompt,但是没过多久就会发现的,返回的内容的越发感觉到奇怪,有时会不知所云,有时候会出现格式错乱。
这是因为 OpenAI API 的 completions 接口本身是为了支持多种类型的prompt,而不仅仅是聊天文本。为了获得更好的效果,开发者需要根据自己的需求,设置合适的prompt格式,以便获得更准确的结果。
聊天效果
在OpenAI的Example 和 Playground里面提供了 Chat 情景的Prompt。
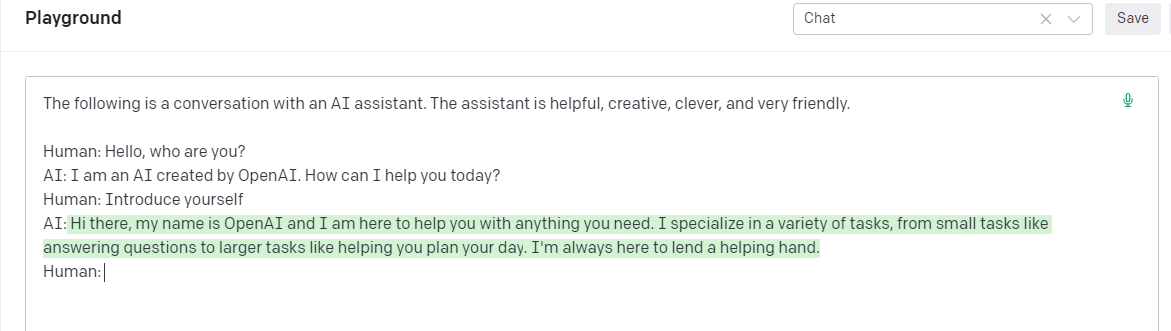
Open AI playground
其中核心点就在于三点:
- 使用一段简短的描述说明当前的场景,并对AI assistant 赋予一定的人格特性说明
- 使用了聊天对话的格式作为prompt,API作为文本生成的工具,会进行后续文本的生成,当prompt刚好结束到AI:(playground使用 Inject start text ,在提交prompt之前自动补充了 /n AI:)的时候,API自然会以当前的场景进行后续内容的补充
- 使用stop避免生成内容超出范围。在聊天的场景中,如果不加stop的话,可能除了生成AI的回答以外,还有继续生成Human的内容,这些就不是在预期范围之内的了。
由此,开发者在自行接入OpenAI API的打造聊天机器人时候,就需要注意将用户的聊天内容包装入 prompt中,构建出完整的意图描述,并设置好对应的stop,才能得到更加有效的回答。
上下文连续
另外一个比较常见的问题就是,为什么接入的API并不像ChatGPT一样具有上下文的连续性的。
这个关键点还是在于当前的API是无状态的,尤其是Web应用的开发者对于无状态应该是再熟悉不过的了。无状态的接口自然是无法有前后的关联了,每一次的调用都是独立的。
所以想要实现上下文的关联,就之内尽可能的给足上文。这个意思就是说,在prompt中,需要把之前的聊天内容的都携带上。带的越多,自然知道的越多,关联性就越强。
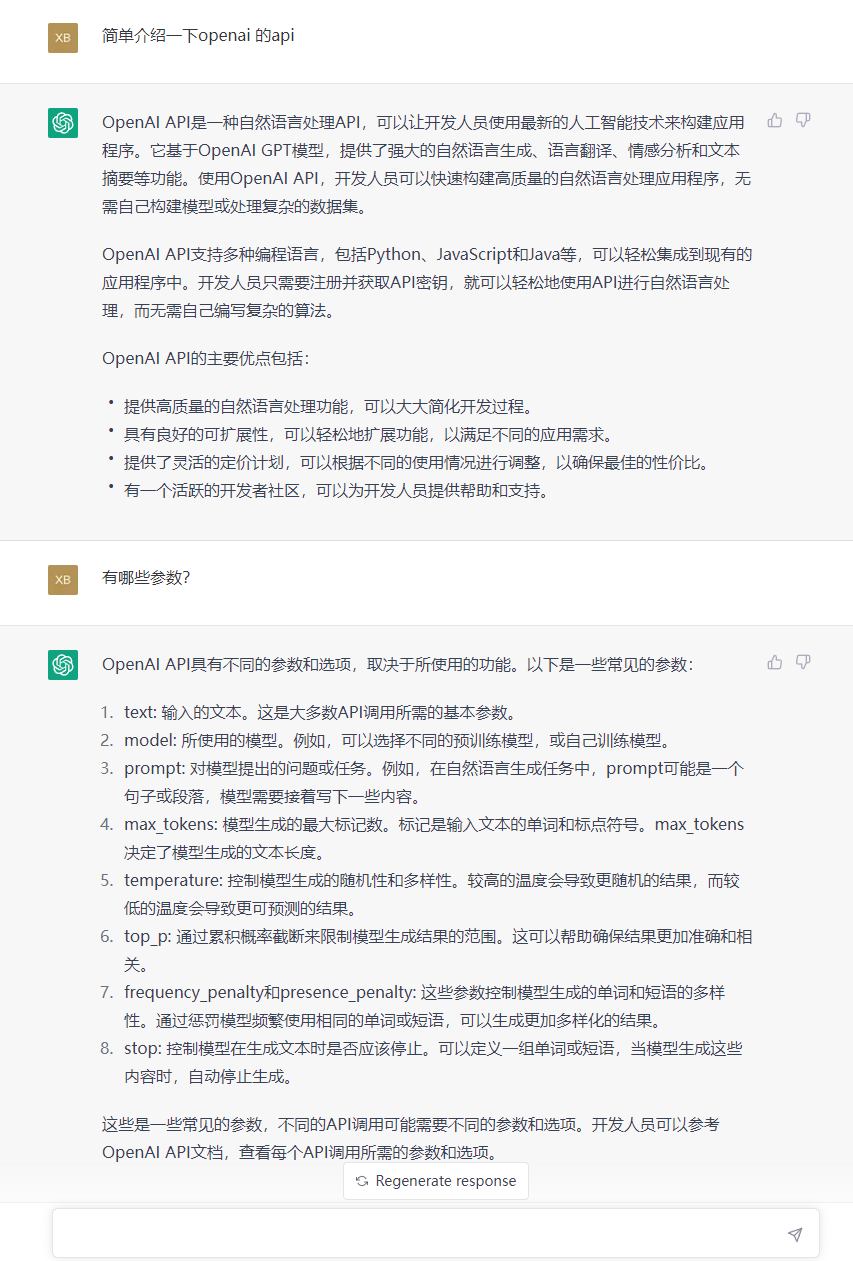
ChatGPT的会话连续性
但是也并不是可以无限制的携带上文。接口中有一个max_tokens的参数,用于控制生成completion的长度,而prompt和completion的总长度,受模型最大长度的限制(最新的text-davinci-003的最大长度是4096token),token的计算可以使用官方的工具进行评估。
其他参数
除了以上参数之外的,另外的像是temperature控制的生成内容的随机性,frequency_penalty和presence_penalty提供生成内容的多样性等等,开发者可以详细参考OpenAI的开发文档,了解参数的详情,根据实际的应用场景进行参数微调,从而打造属于自己的ChatGPT。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号