如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等。对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 ElasticSearch 来完成数据的搜索和分析,有了这个利器,我们可以轻松应对上述场景,实现关键字搜索等功能。
不过,由于增加了 ElasticSearch 作为搜索引擎,随之而来的问题就是,如何将业务中的数据同步到 ElasticSearch 中,主要有两种方式:
- 业务双写(具有侵入性)
- 数据库同步
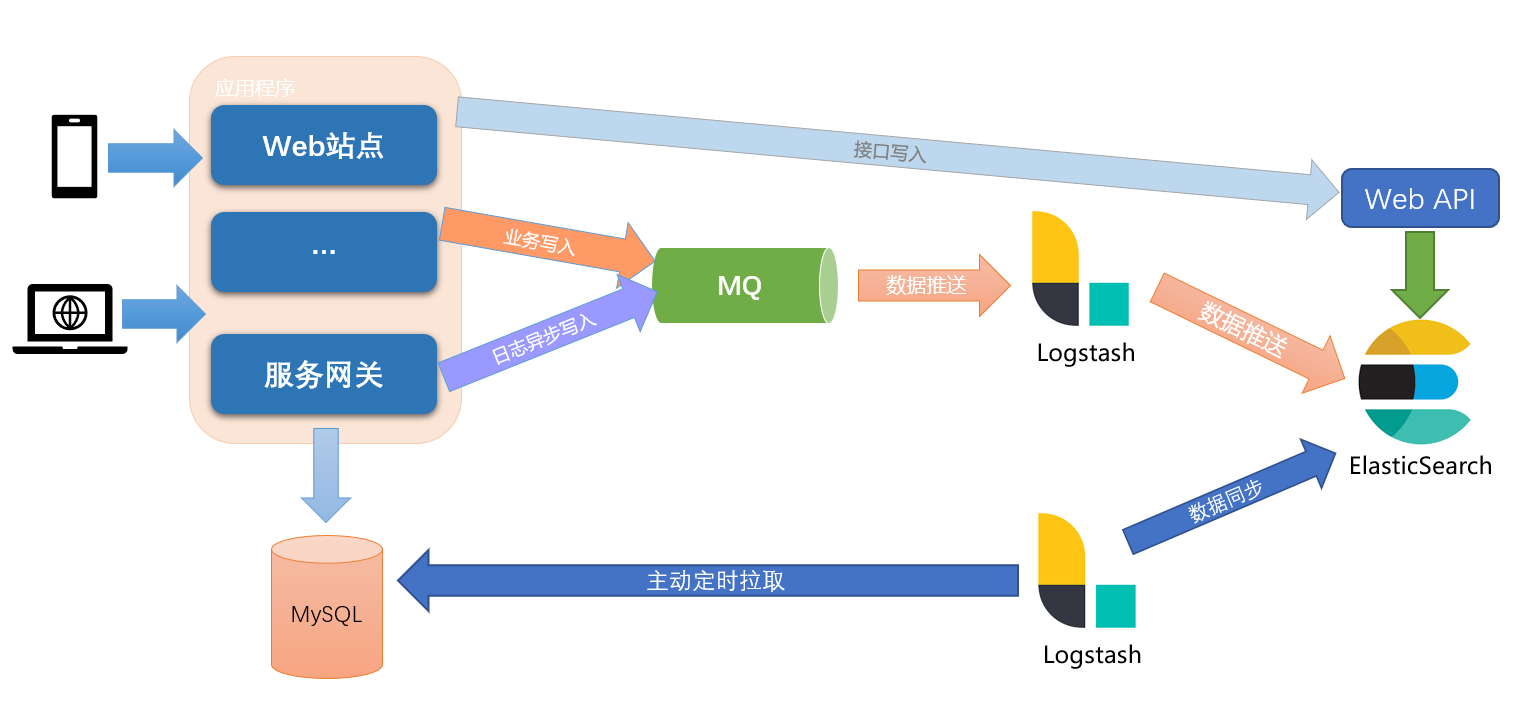
由于业务双写需要更改业务代码,一般不建议采用此种方式,除非有强一致性要求,或者对业务侵入不敏感的系统可以采取此种方式:
- 强一致性:同步通过HTTP请求写入 ElasticSearch
- 最终一致性:
- 可采取业务写入日志,后端通过日志流数据过滤写入 ElasticSearch(ELK标准模式,推荐)
- 另一种方案就是同步写入 MQ,后端通过消费MQ异步写入 ElasticSearch
本文主要讨论非代码侵入的数据库同步方式,主要采用的是通过 LogStash 定时扫描数据库来增量同步数据的方案。
数据库脚本
数据库表结构中,需要有一个时间类型的字段作为增量更新的标识字段(例如 lastupdatetime),当该条数据更新时,必须同时更新该字段。
CREATE TABLE user (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`age` int(11) NOT NULL,
`createtime` datetime(0) NOT NULL,
`lastupdatetime` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
)
INSERT INTO `user` VALUES(1,"jack",18,Now(),Now())
INSERT INTO `user` VALUES(2,"William",18,Now(),Now())
SELECT * from `user`
查询结果:
| id | name | age | createtime | lastupdatetime |
|---|---|---|---|---|
| 1 | jack | 18 | 2019-10-24 10:31:14 | 2019-10-24 10:31:14 |
| 2 | William | 18 | 2019-10-24 10:31:49 | 2019-10-24 10:31:49 |
LogStash 配置信息
logstash docker 安装脚本:
mkdir /opt/logstashsync/
mkdir /opt/logstashsync/pipeline
vi /opt/logstashsync/pipeline/logstash.conf
input {
jdbc {
jdbc_driver_library => "/app/mysql-connector-java-8.0.18.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.10.102:3306/synctest"
jdbc_user => "root"
jdbc_password => "123456"
tracking_column => "unix_ts_in_secs"
use_column_value => true
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > :sql_last_value AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
elasticsearch {
hosts => "192.168.10.102:9200"
index => "syncuser"
timeout => 300
document_id => "%{[@metadata][_id]}"
}
}
上述配置说明:
- jdbc_driver_library:logstash的镜像中并不包含 jdbc connector,需要在官方网站中下载下来之后,在容器启动时映射到容器中,可点此下载。
- tracking_column:用于跟踪 Logstash从MySQL读取的最后最后一条数据的 lastupdatetime 的值,并默认持久化到磁盘文件 .logstash_jdbc_last_run 中。该值用于在下一次循环同步时,同步的起始值,从而达到增量同步的作用,存储在 .logstash_jdbc_last_run 在 SQL 语句中可以以 :sql_last_value 访问。
- schedule:设置多久循环同步一次,以cron语法指定,我们当前设置的是5秒一次循环。
- statement:执行同步的SQL语句。值得注意的是where条件中为什么要这么写,可以参考 https://www.elastic.co/blog/how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash 文章中给定的解释。
- 重要: 关于上述配置中的 [@metadata][_id],在同步过程中,必须使用数据库数据id作为 ElasticSearch 中的文档 _id,这样当数据库中该条数据有修改时,ElasticSearch 中的文档才会相应的同步修改,否则会以一条新的数据插入 ElasticSearch,导致数据同步错误。
有了上述配置,我们把 Logstath 的 docker 容器跑起来:
docker run -d \
-v /opt/logstashsync/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /opt/logstashsync/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /opt/logstashsync/mysql-connector-java-8.0.18.jar:/app/mysql-connector-java-8.0.18.jar \
--name=logstash \
logstash:6.7.1
注意:上述脚本可以看到,我们将本地 /opt/logstashsync/ 目录下的 mysql-connector-java-8.0.18.jar 映射到了容器的 /app 目录下,对应在上述 logstash.conf 中的配置的 jdbc_driver_library 的值
通过查看 Logstash 容器运行日志,我们可以看到如下日志内容,说明该容易已经按照我们预期的每5s同步一次数据库:
[2019-10-25T06:27:59,056][INFO ][logstash.inputs.jdbc ] (0.039651s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 0 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
[2019-10-25T06:28:05,154][INFO ][logstash.inputs.jdbc ] (0.004232s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
[2019-10-25T06:28:10,230][INFO ][logstash.inputs.jdbc ] (0.002832s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
通过Kibana查询同步结果
在 Kibana 中创建 syncuser index,即可以查看到已经同步的数据:

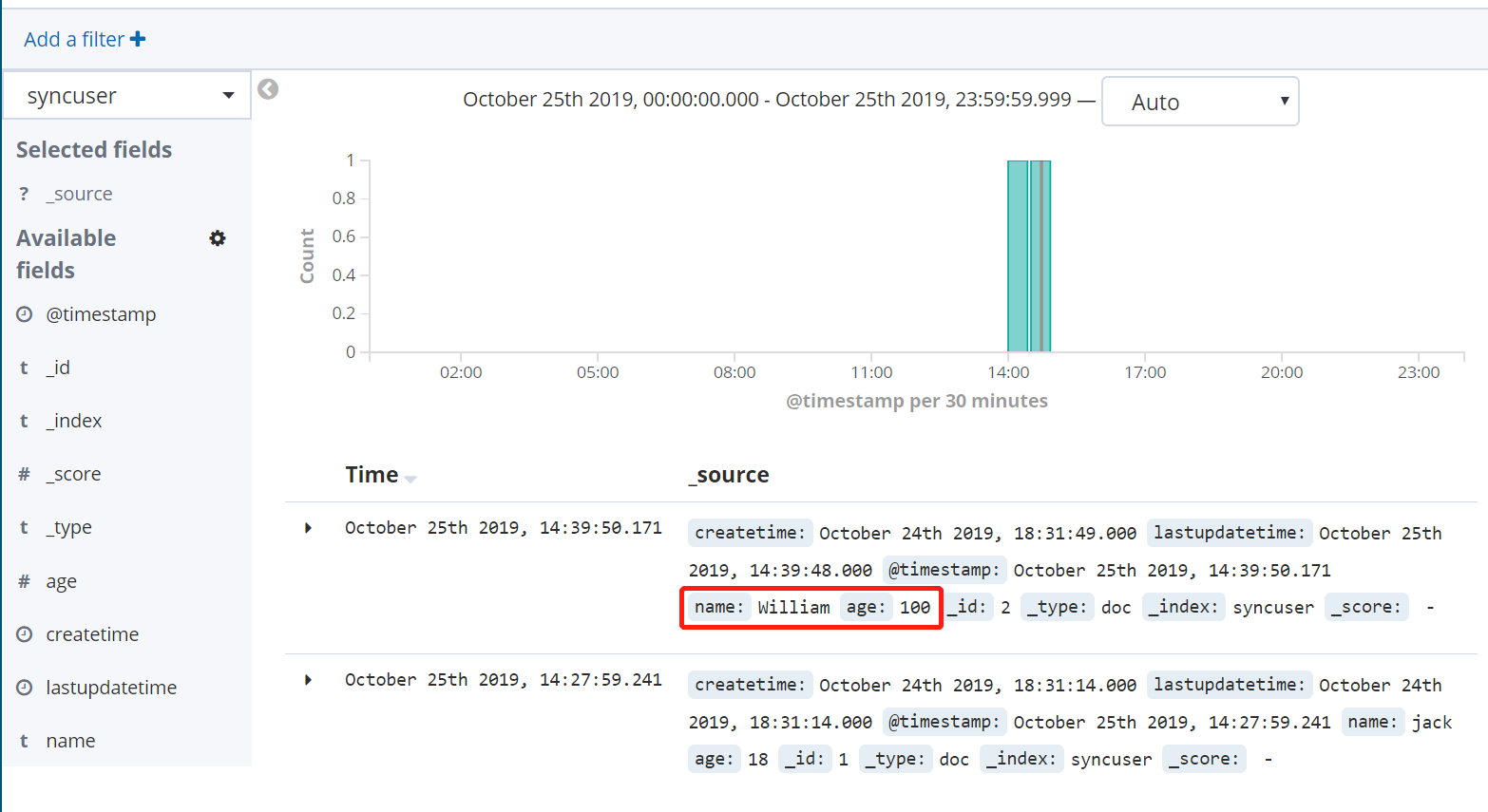
尝试对数据库数据做更新操作,将名为 William 的用户年龄修改为100(记得同时要更新lastupdatetime 字段):
UPDATE `user` SET age=100, lastupdatetime=NOW() WHERE `name`='William';
SELECT * from `user`

再次查看 Kibana 中的数据,可以看到该数据已经成功同步:
结语
根据上述过程,我们完成了简单的单表数据定时同步至 ElasticSearch 过程,但是在实际使用过程中,需要注意以下问题:
- sql语句需要考虑每次同步最大条数。大多数情况下,数据库可能已经存在大量数据,如果不做控制,可能会导致 Logstash 刚启动时一次同步的数据量过大,发生异常,采取的方式可以在 SQL 语句中增加每次获取最大条数限制。
- 增量更新的标识字段,既然是通过>号方式判断,那么如果id是自增主键,也可以采用 int 类型的主键字段,这样可以减少在数据库中创建 lastupdatetime 索引。但如果不是主键,则需要谨慎使用,具体原因请仔细参考上述配置说明中 statement 给出的链接。
- 由于增量同步机制所致,所有数据库中的删除操作应该以软删除的方式进行,即增加 is_delete 字段,否则如果硬删除会导致该条数据状态无法同步至 ElasticSearch,当然在查询 ElasticSearch 时,也应该增加该条件,排除已经删除的数据。
作者:xboo
出处:http://www.cnblogs.com/xboo/
本文版权归作者和博客园共有,欢迎转载,但必须在文章页面显著位置给出原文连接,否则保留追究法律责任的权利。如果觉得对你有帮助,可以点一下右下角的【推荐】,感谢支持!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号