结对第二次--文献摘要热词统计及进阶需求
-
课程名称:软件工程1916|W(福州大学)
-
作业要求:结对第二次-文章摘要热词统计
-
结对学号221600225|221600435
-
作业目标:实现一个能够对文本文件中的单词的词频进行统计的控制台程序,并在基本需求实现的基础上编码实现热顶会热词统计器
-
Github项目地址:Github项目地址
-
代码签入记录:
基本需求实现:
进阶需求实现:
-
具体分工:
- 221600225林鹏飞负责基础需求和进阶需求的设计与实现。
- 221600435徐炳南负责博客部分的编写,Github上传。
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 610 | 630 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 70 | 90 |
| • Design Spec | • 生成设计文档 | 60 | 50 |
| • Design Review | • 设计复审 | 30 | 50 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| • Design | • 具体设计 | 70 | 80 |
| • Coding | • 具体编码 | 320 | 300 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 60 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 60 | 90 |
| • Size Measurement | • 计算工作量 | 30 | 40 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 40 | 55 |
| 合计 | 740 | 820 | |
二、解题思路描述
针对基本需求:
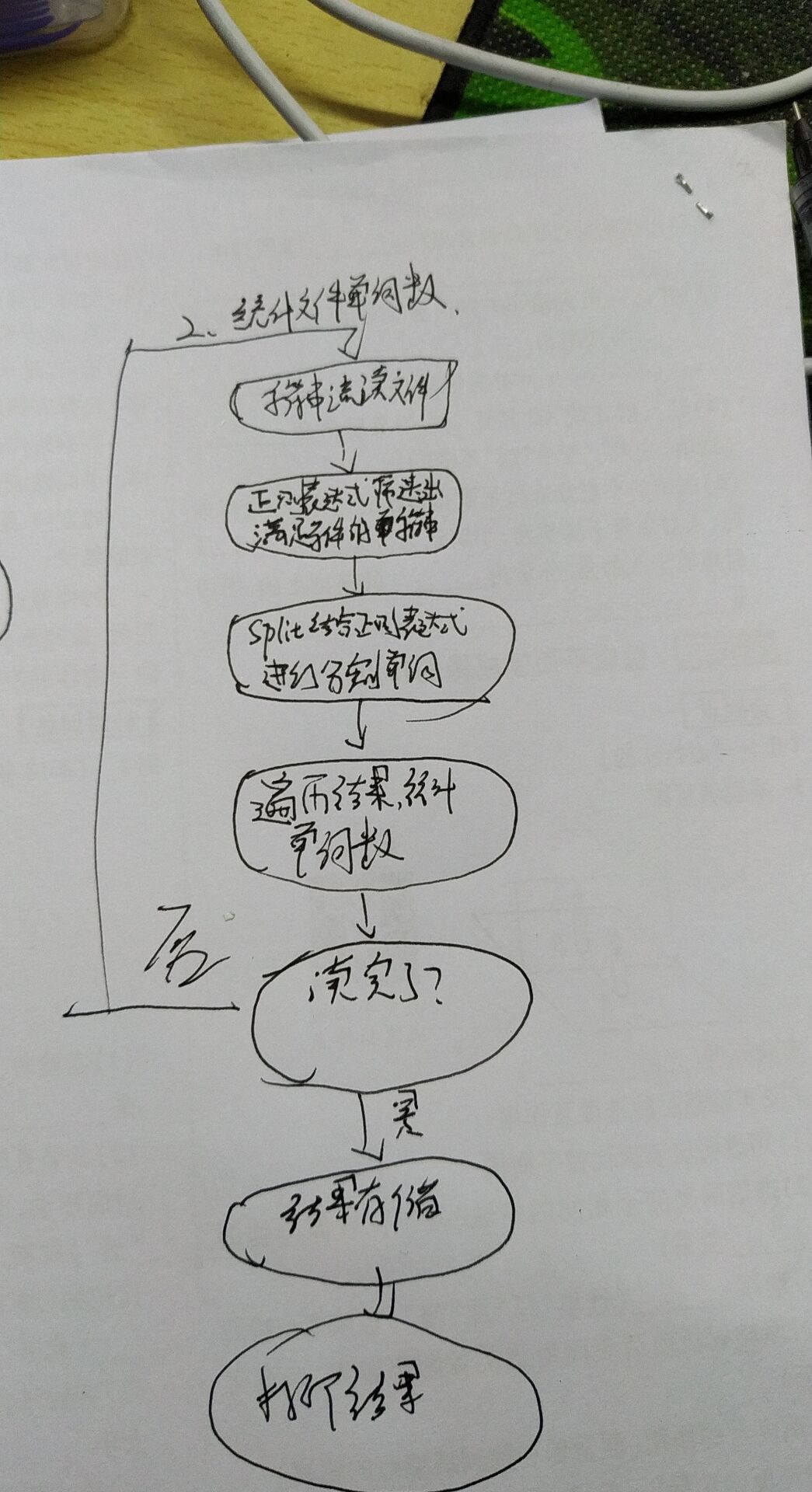
- 在考虑统计文件的字符数时,我们采用的是直接用字节流读入文件,然后判断读入字节的ascii码进而统计字符数。在考虑统计文件的单词数时,我们采用本次改用字符串流读入文件。每次读入一整行的字符串。然后用正则表达式筛选出满足条件的单词,再用split函数和正则表达式进行分割,然后统计单词数量。而每次读一整行字符串,对该字符串的每个字节进行逐个判断,如果找到满足条件的字符,则该行是有效的,否则无效。接着将单词和频数存入,HasmMap集合中,然后写一个判断函数,对HashMap集合中的单词按要求进行排序。最后直接用字符流将结果存入result.txt文件中。
- 在接口封装上,我们已经尽量将每个功能单独包装成一个函数,但是由于编程能力不足,并没对这些东西进行完全封装,望谅解。
针对进阶需求:
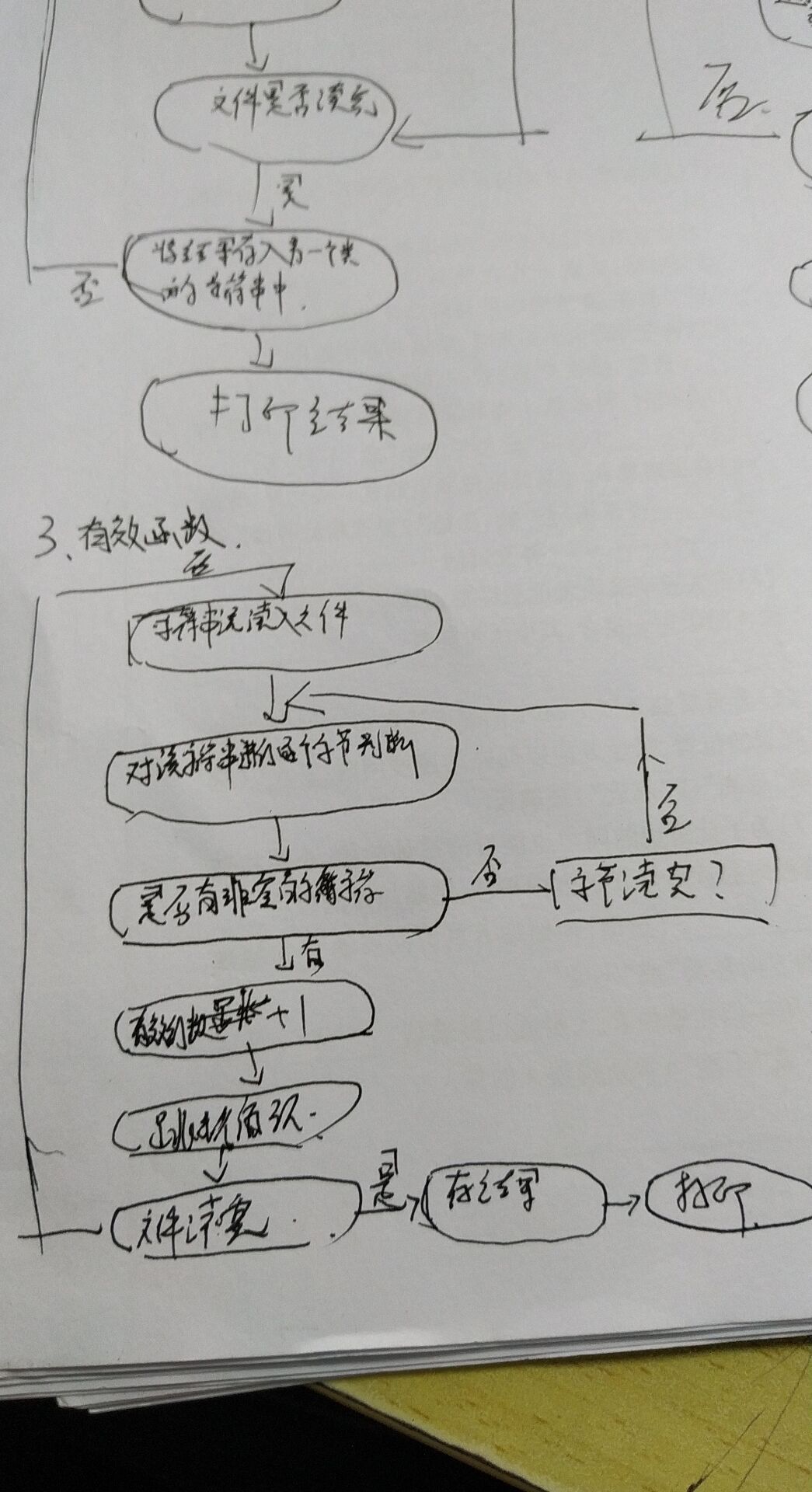
- 爬虫部分由于时间紧迫,且我对这方面没有任何经验,所以并没有写爬虫,所用的测试文件,是从其他同学那里借过来的。自定义输入输出: 从args[]中读入命令行参数中输入路径和输出路径即可。检测args中是否有字符串”-w”如果有,则进行单词权重计算,否则不进行。检测到字符串”-w”,再进行”Title:”和”Abstact:”的判断,然后将HashMap集合中的词频进行更改即可。该问题我认为应该用正则表达式进行匹配,但是我没有写出满足条件的正则表达式,所以这没有解决。判断args[]是否有字符串”-n”若有,则在进行HashMap集合的迭代是,加入迭代次数的统计和判断即可。但是没能完成该功能。还有就是对于附加题没能解决。
三、设计实现过程
这次设计实现过程使用功能流程图的方式进行实现:

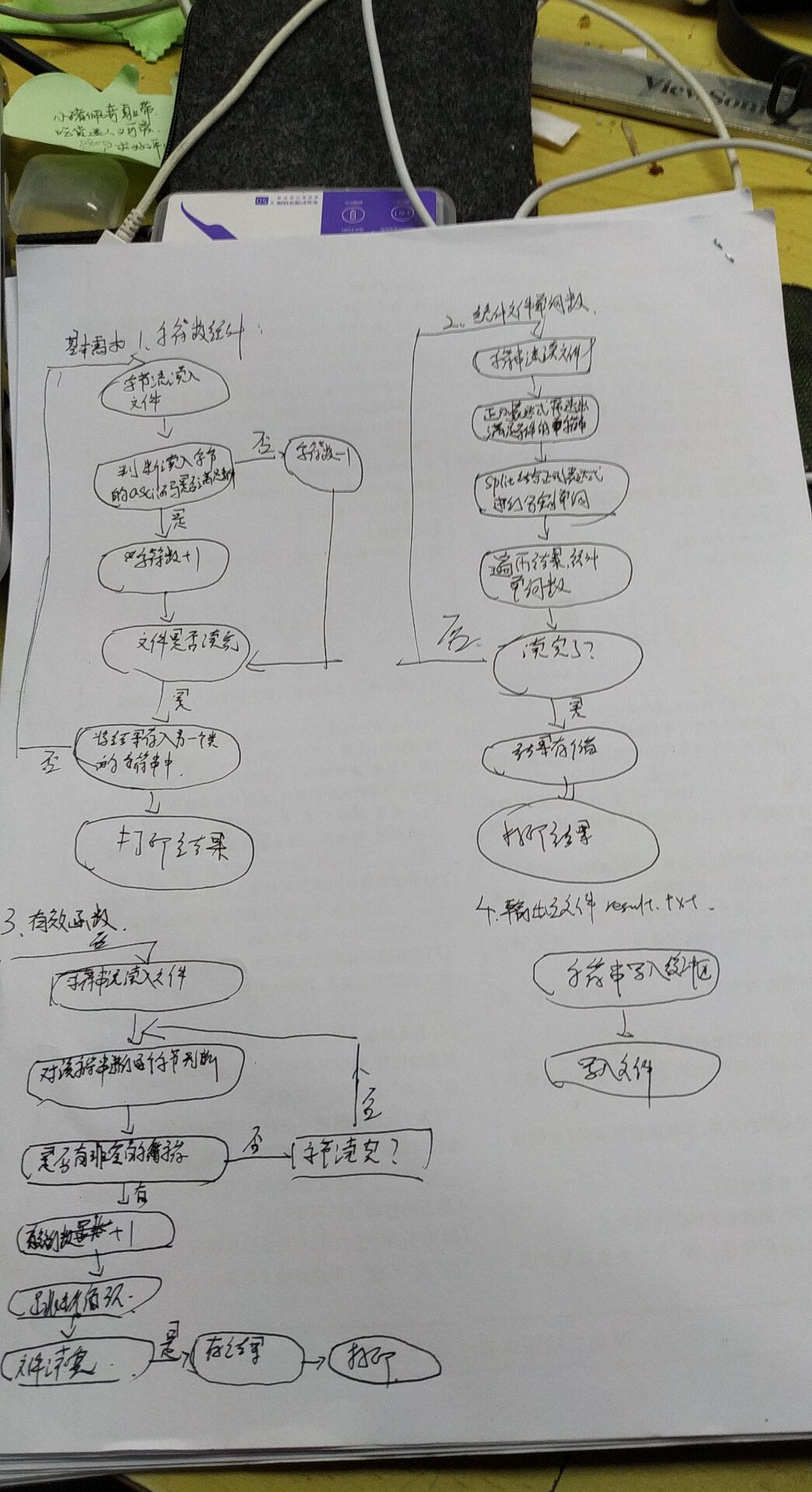
四、改进程序上花费的时间及改进思路
- 实际上,在写程序的时候,我们是边推进,变修改的。当每一个功能实现之后我们都会进行测试,但是当在写一个功能之后,总是会发现上一个功能好像需要传一些参数或者返回个什么到下一个功能上,所以改进程序花费上的时间应该是非常多的。差不多和编写新功能的时间是一样。在这次作业中,遇到的最大的一个坑,就是字符串流和字节串流的不同。字符串流遇到\n会自动省略并,而字节串流则会将其读入。
五、代码说明
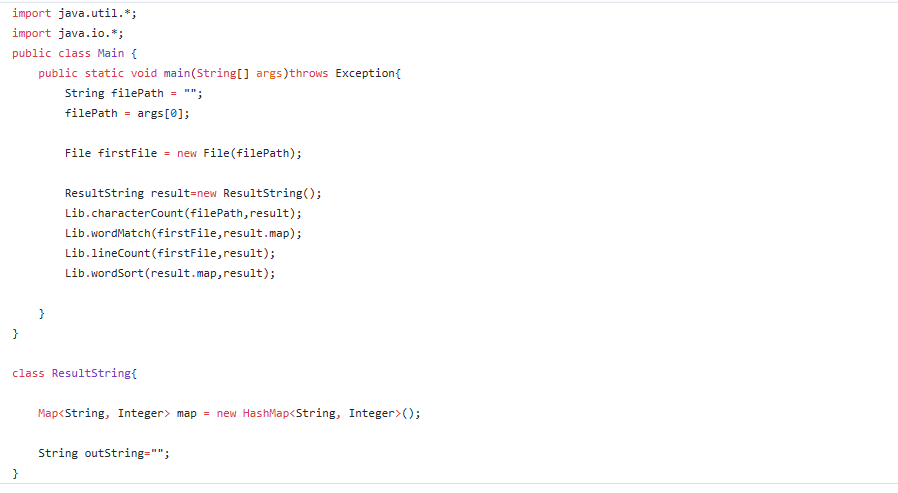


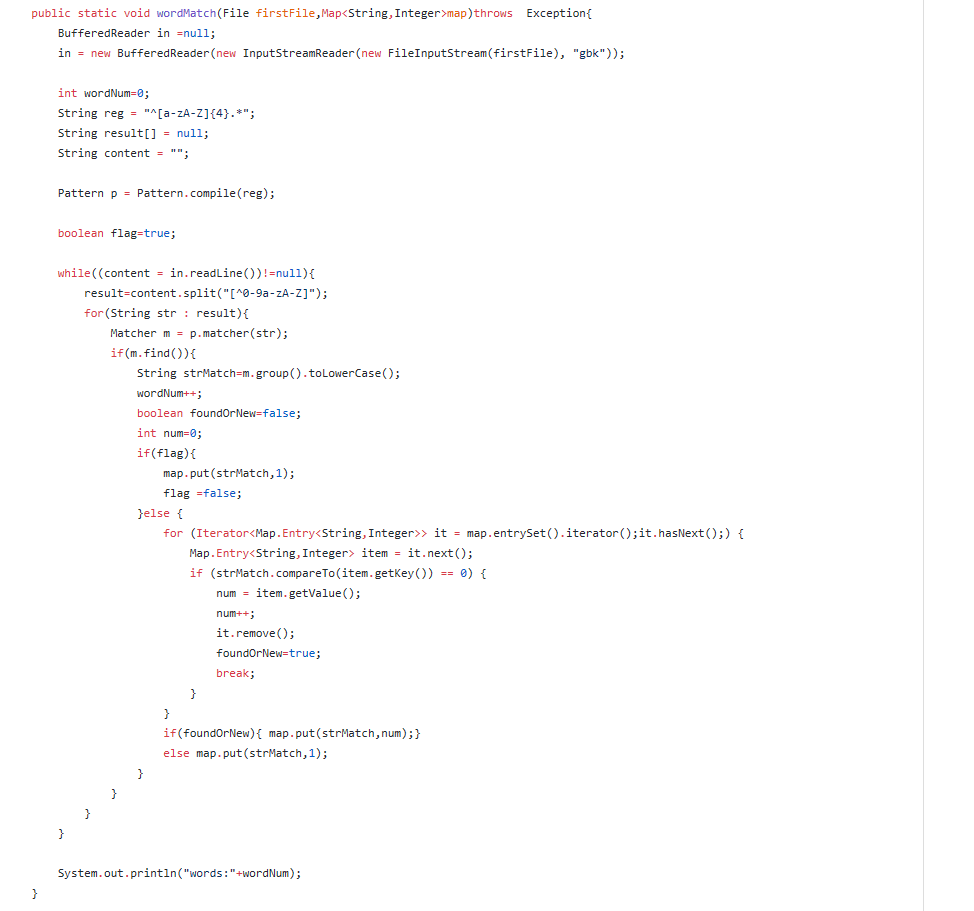
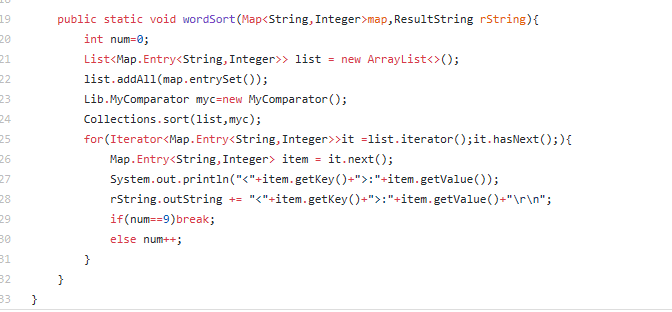
六、单元测试代码(部分)
七、遇到的困难以及解决办法
对于输入流和输出流不够熟悉,最后通过对输入流输出流知识重新学习才对输入流输出流熟练起来。对于单词个数的统计,使用正则表达式是最快的。但是一开始不是很了解,最后通过百度以及同学的交流讨论才懂得正则表达式。然后在字符串流读取不到\n,最后通过改用字节流读取解决。而爬虫的问题不会编写。没能解决进阶需求中,多个单词组成词组的匹配。有想过用正则表达式解决,但是没能写出满足条件的正则表达式。
八、评价队友
林鹏飞:
对于林鹏飞同学,代码的部分基本上都是由他负责,对于整个项目的分工和每个部分的安排他都做的非常好,我要向他学习这种全局的规划以及对整个项目的安排能力。他对于问题的解决能力很强。
徐炳南:
对于徐炳南同学,他经常会和鹏飞一起讨论一些问题,且会通过各种办法去解决。但是代码能力还需要提高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号