分布式并行计算MapReduce
HDFS在Hadoop上的作用、工作原理和工作过程:
作用:HDFS 天生是为大规模数据存储与计算服务的,而对大规模数据的处理目前还有没比较稳妥的解决方案。 HDFS 将将要存储的大文件进行分割,分割到既定的存储块(Block)中进行了存储,并通过本地设定的任务节点进行预处理,从而解决对大文件存储与计算的需求。
原理:NameNode具有RackAware机架感知功能,这个可以配置。
若client为DataNode节点,那存储block时,规则为:副本1,同client的节点上;副本2,不同机架节点上;副本3,同第二个副本机架的另一个节点上;其他副本随机挑选。
若client不为DataNode节点,那存储block时,规则为:副本1,随机选择一个节点上;副本2,不同副本1,机架上;副本3,同副本2相同的另一个节点上;其他副本随机挑选。
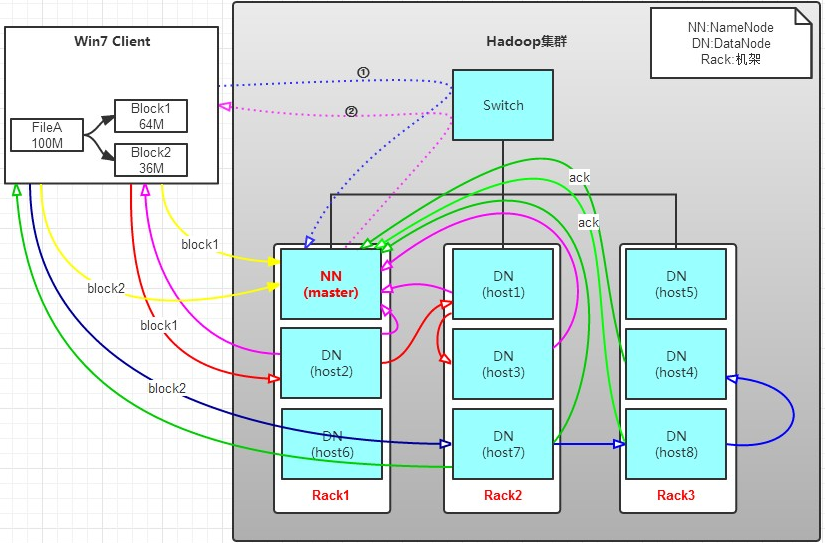
过程: 1、将64M的block1按64k的package划分;
2、然后将第一个package发送给host2;
3、host2接收完后,将第一个package发送给host1,同时client想host2发送第二个package;
4、host1接收完第一个package后,发送给host3,同时接收host2发来的第二个package。
5、以此类推,如图红线实线所示,直到将block1发送完毕。
6、host2,host1,host3向NameNode,host2向Client发送通知,说“消息发送完了”。如图粉红颜色实线所示。
7、client收到host2发来的消息后,向namenode发送消息,说我写完了。这样就真完成了。如图黄色粗实线
8、发送完block1后,再向host7,host8,host4发送block2,如图蓝色实线所示。
9、发送完block2后,host7,host8,host4向NameNode,host7向Client发送通知,如图浅绿色实线所示。
10、client向NameNode发送消息
MapReduce的功能、工作原理和工作过程:MapReduce是hadoop的核心组件之一,hadoop要分布式包括两部分,一是分布式文件系统hdfs,一部是分布式计算框,就是mapreduce,缺一不可,也就是说,可以通过mapreduce很容易在hadoop平台上进行分布式的计算编程。
MapReduce程序运行过程:
1. 作业运行过程:首先向JobTracker请求一个新的作业ID;然后检查输出说明(如输出目录已存在)、输出划分(如输入路径不存在);JobTracker配置好所有需要的资源,然后把作业放入到一个内部的队列中,并对其进行初始化,初始化包括创建一个代表该正在运行的作业对象(封装任务和记录信息),以便跟踪任务的状态和进程;作业调度器获取分片信息,每个分片创建一个map任务。TaskTracker会执行一个简单的循环定期发送heartbeat给JobTracker,心跳间隔可自由设置,通过心跳JobTracker可以监控TaskTracker是否存活,同时也能获得TaskTracker处理的状态和问题,同时也能计算出整个Job的状态和进度。当JobTracker获得了最后一个完成指定任务的TaskTracker操作成功的通知时候,JobTracker会把整个Job状态置为成功,然后当客户端查询Job运行状态时候(注意:这个是异步操作),客户端会查到Job完成的通知的。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
2)编写map函数和reduce函数,在本地运行测试通过
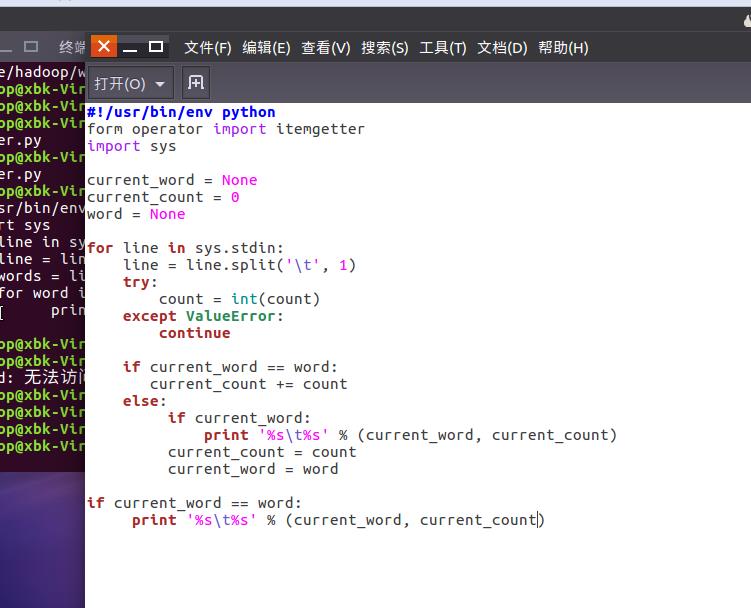
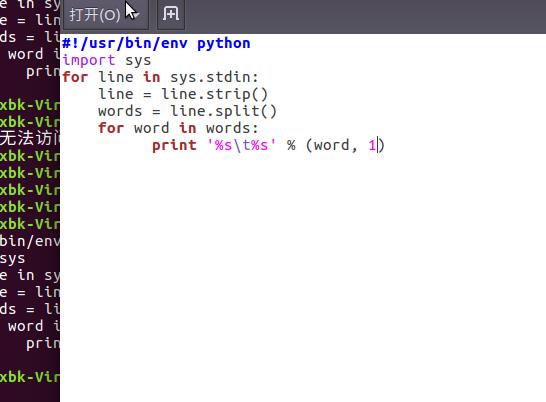
准备文本文件,放在本地/home/hadoop/wc
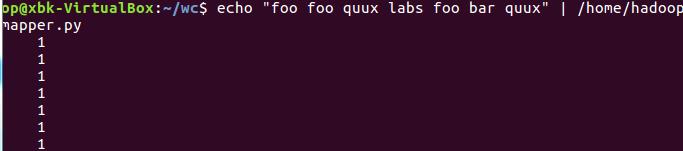
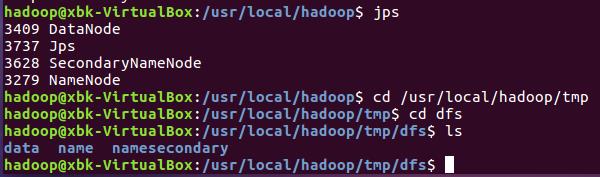
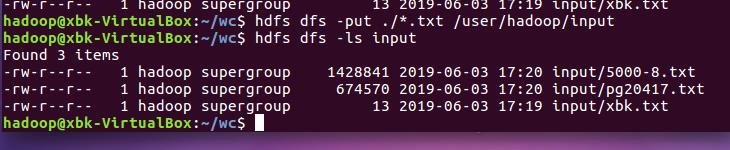
source run.sh来执行mapreduce
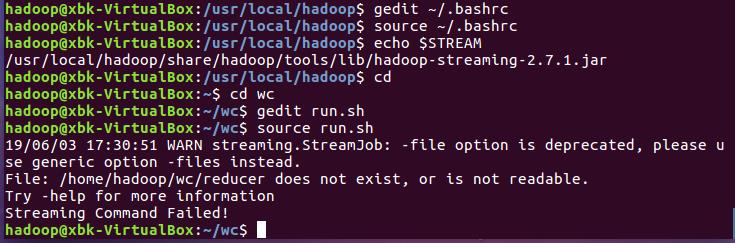
运行结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号