安装关系型数据库MySQL 安装大数据处理框架Hadoop
1、简述Hadoop平台的起源、发展历史与应用现状。列举发展过程中重要的事件、主要版本、主要厂商;国内外Hadoop应用的典型案例。
Hadoop由 Apache Software Foundation 公司于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop 最初只与网页索引有关,迅速发展成为分析大数据的领先平台。目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估。
名字起源。
Facebook使用Hadoop存储内部日志与多维数据,并以此作为报告、分析和机器学习的数据源。目前Hadoop集群的机器节点超过1400台,共计117200个核心CPU,超过15PB原始存储容量,每个商用机器节点配置了8核CPU,12TB数据存储,主要使用StreamingAPI和JavaAPI编程接口。Facebook同时在Hadoop基础上建立了一个名为Hive的高级数据仓库框架,Hive已经正式成为基于Hadoop的Apache一级项目。此外,还开发了HDFS上的FUSE实现。
百度
百度在2006年就开始关注Hadoop并开始调研和使用,在2012年其总的集群规模达到近十个,单集群超过2800台机器节点,Hadoop机器总数有上万台机器,总的存储容量超过100PB,已经使用的超过74PB,每天提交的作业数目有数千个之多,每天的输入数据量已经超过7500TB,输出超过1700TB。
阿里巴巴
阿里巴巴的Hadoop集群截至2012年大约有3200台服务器,大约30?000物理CPU核心,总内存100TB,总的存储容量超过60PB,每天的作业数目超过150?000个,每天hivequery查询大于6000个,每天扫描数据量约为7.5PB,每天扫描文件数约为4亿,存储利用率大约为80%,CPU利用率平均为65%,峰值可以达到80%。阿里巴巴的Hadoop集群拥有150个用户组、4500个集群用户,为淘宝、天猫、一淘、聚划算、CBU、支付宝提供底层的基础计算和存储服务
2、下次上课之前,必须成功完成Hadoop的安装与配置。
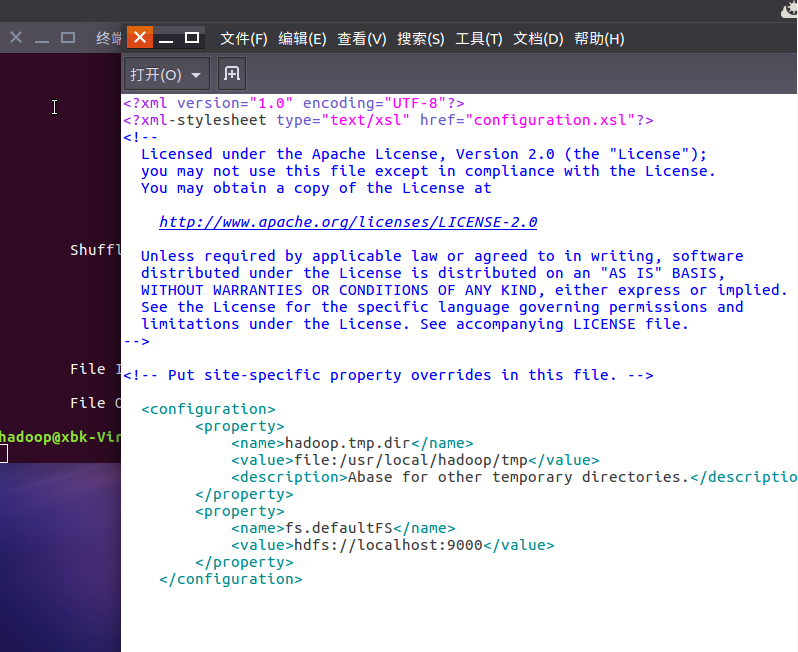
改文件
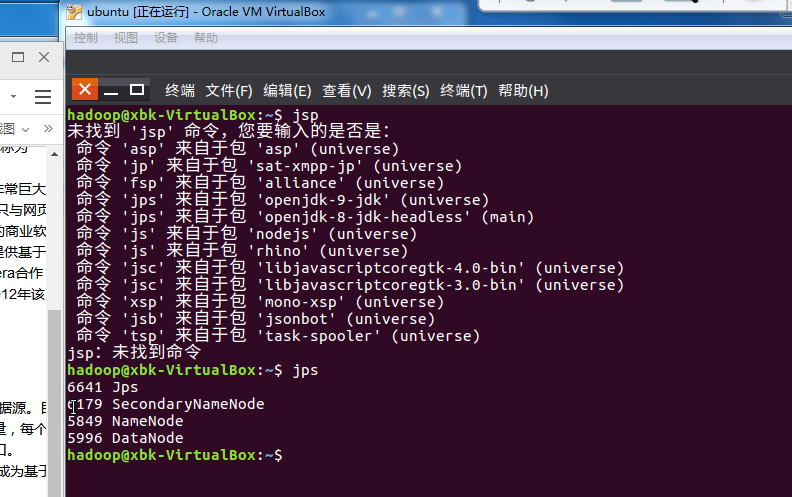
运行hadoop
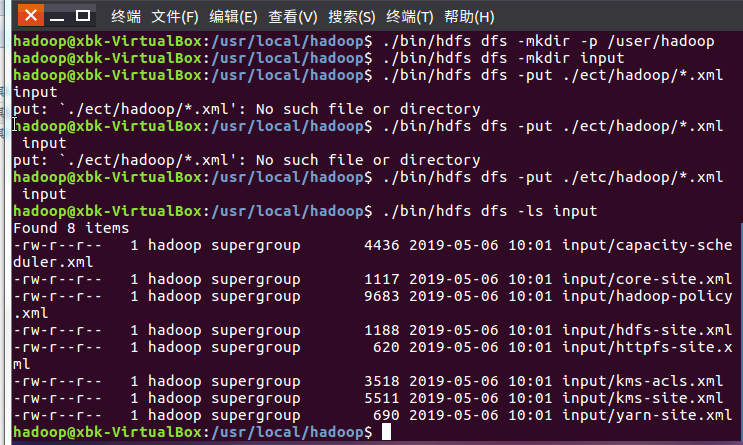
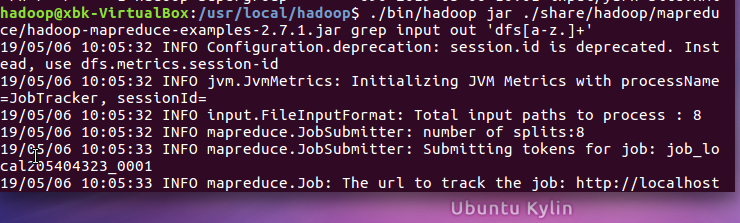
运行Hadoop实例

 浙公网安备 33010602011771号
浙公网安备 33010602011771号