爬虫综合大作业
一.把爬取的内容保存取MySQL数据库
代码如下:
漫威电影里面我最喜欢的就是毒液了,所以这次我选择了爬取毒液的评论。猫眼这里有用户评论的相关数据,我们选取了地理位置、评论内容、用户名,通过python的requests模块开始爬取。导入本次爬取需要的包,开始抓取数据。
def get_data(url): headers = { 'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'} html = requests.get(url, headers=headers) if html.status_code ==200: return html.content else: return none
其次是解析Json数据,将评论数据中用户名、城市名、评论内容、评分依次解析出来。代码如下:
def parse_data(html): json_data = json.loads(html)['cmts'] comments = [] try: for item in json_data: comment = { 'nickName': item['nickName'], 'cityName': item['cityName'] if 'cityName' in item else '', 'content': item['content'].strip().replace('\n', ''), 'score': item['score'] } comments.append(comment) return comments except Exception as e: print(e)
接着我们将获取到的数据保存到本地,并转化为Excel,方便到时候生成云词。
def save(): start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S') while start_time > end_time: url = 'http://m.maoyan.com/mmdb/comments/movie/42964.json?_v_=yes&offset=15&startTime=' + start_time.replace( ' ', '%20') html = None try: html = get_data(url) except Exception as e: time.sleep(0.5) html = get_data(url) else: time.sleep(0.1) comments =parse_data(html) start_time = comments[14]['startTime'] print(start_time) start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1) start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S') for item in comments: print(item) with open('files/comments.txt', 'a', encoding='utf-8')as f: f.write(item['nickName']+','+item['cityName'] +','+item['content']+','+str(item['score'])+ item['startTime'] + '\n') if __name__ == '__main__': url = 'http://m.maoyan.com/mmdb/comments/movie/42964.json?_v_=yes&offset=15&startTime=2018-11-19%2019%3A36%3A43' html = get_data(url) reusults = parse_data(html) save()
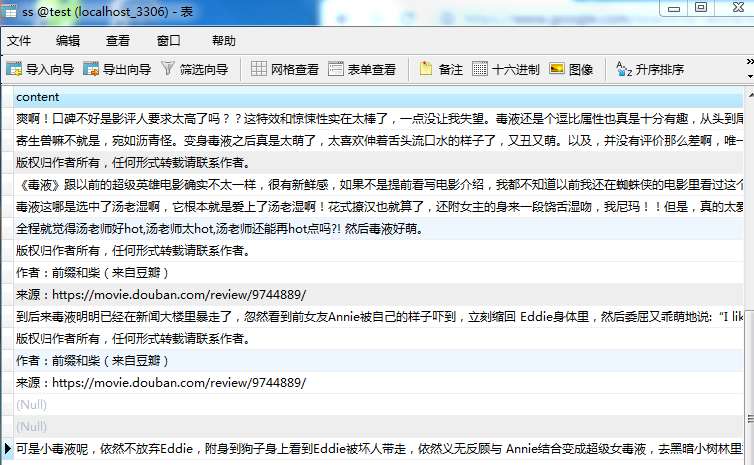
以下是爬取爬取猫眼电影网站上的评论保存到Excel文件里,如下图:
将采集到的数据可视化,采用pyecharts,按照地理位置制作了毒液观众群的分布图。代码如下:
geo = Geo('《毒液》观众位置分布', '数据来源:猫眼-Ryan采集', **style.init_style) attr, value = geo.cast(data) geo.add('', attr, value, visual_range=[0, 1000], visual_text_color='#fff', symbol_size=15, is_visualmap=True, is_piecewise=False, visual_split_number=10) geo.render('观众位置分布-地理坐标图.html') data_top20 = Counter(cities).most_common(20) bar = Bar('《毒液》观众来源排行TOP20', '数据来源:猫眼', title_pos='center', width=1200, height=600) attr, value = bar.cast(data_top20) bar.add('', attr, value, is_visualmap=True, visual_range=[0, 3500], visual_text_color='#fff', is_more_utils=True, is_label_show=True) bar.render('观众来源排行-柱状图.html')
从可视化结果来看,“毒液”观影人群以东部城市为主,观影的top5城市为深圳、北京、上海、广州、成都。
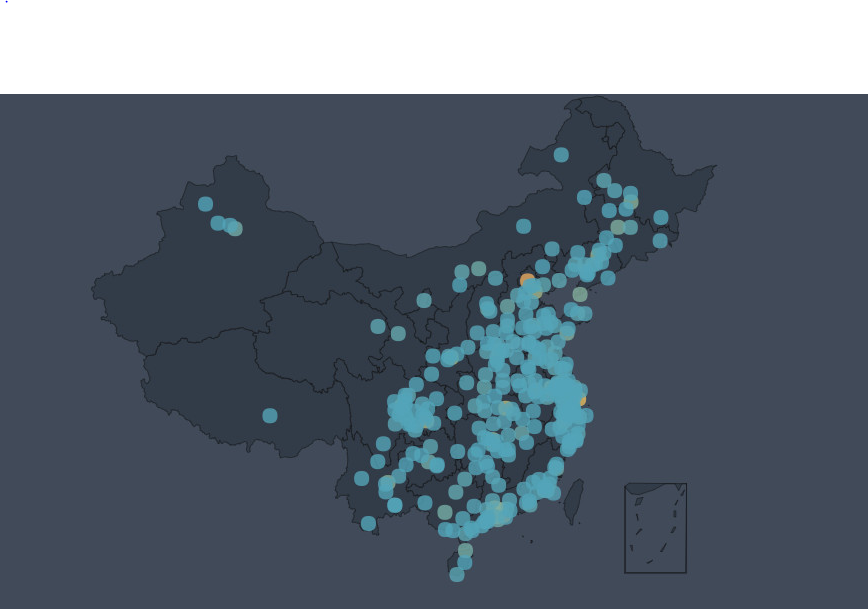
观众地理位置分布图
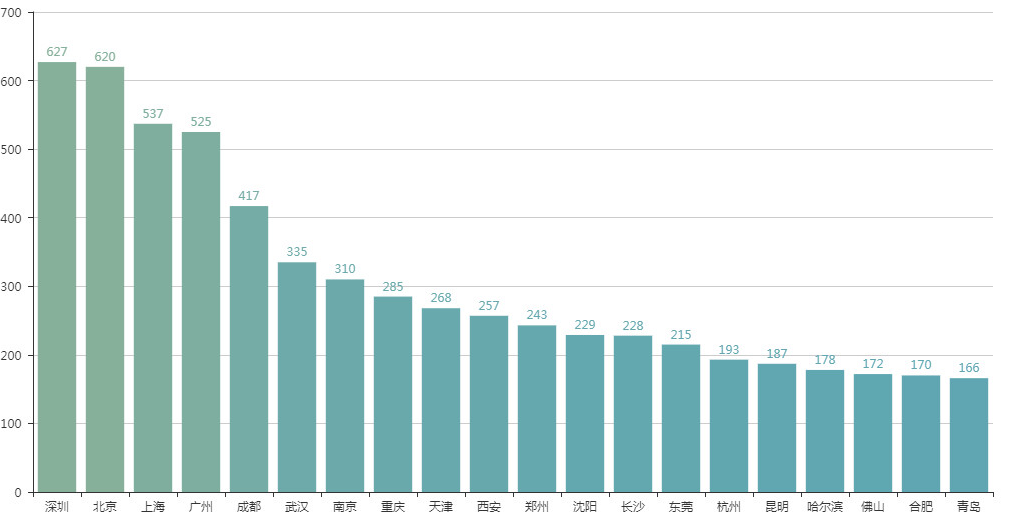
观众来源排行TOP20
我把通过jieba把评论分词,最后通过wordcloud制作词云,作为大众对该电影的综合评价。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号