摘要:近日,同一个实验室的博士mm何占盈的的论文《Document Summarization Based on Data Reconstruction》荣获第26届AAAI人工智能国际会议最佳论文奖(Outstanding Paper Award),这是中国大陆首次获此殊荣。简介:论文提出了一种全新的从...
阅读全文
摘要:自己的一个Recommender System的工作在WWW2012会议上发表:An Exploration of Improving Collaborative Recommender Systems via User-Item Subgroups.四月份打算去参加在法国里昂举行的WWW2012会议,如果国内也有要去参加的朋友可以联系一下,可以在那边交流一下。我的个人信息可以在我的主页找到:http://eagle.zju.edu.cn/~binxu/
阅读全文
摘要:今天把自己前面的工作介绍下,SIGIR 2011 Full paper:
Efficient Manifold Ranking for Image Retrieval
虽然这个工作在算法上并不算有突破性的创新,但是因为是我自己的第一个工作,很多地方都在学习,所以也算马马虎虎了。
文章的目标是去加速经典的流行排序算法(Ranking on Data Manifold, or Manifold Ranking, MR),最后取得的结果是在损失有限精度的情况下,有效提高了算法运行速度。特别的,对于新的样本点(out-of-sample),算法也可以处理。
阅读全文
摘要:计算机科学的论文最大特点在于:
极度重视会议,而期刊则通常只用来做re-publication,也就是说很多期刊文章是会议论文的扩展版,而不是首发的工作。并且期刊的录用到发表中间的等待时间极长,有的甚至需要等上1-2年,因此即使投稿时是最新的工作,等发表的时候也不一定是最新了!也正因为如此,很多计算机期刊的影响因子都低的惊人,很多顶级刊物也只有1到2的印象因子!
因此,要讨论计算机科学的publication,那么请忽视影响因子。
阅读全文
摘要:坐标图上有各种数字和文字,因为图的大小关系,经常会需要去调节字体的大小,这里简单列举一下,以后想到了再补充~
阅读全文
摘要:matlab绘图的时候只用plot函数出来的图不一定符合自己最想要的格式, 经常要对坐标的数字、范围、间隔做处理。
虽然不是什么很难的操作,但是确实常用,也容易忘记,所以就放在这里说明一下:
阅读全文
摘要:
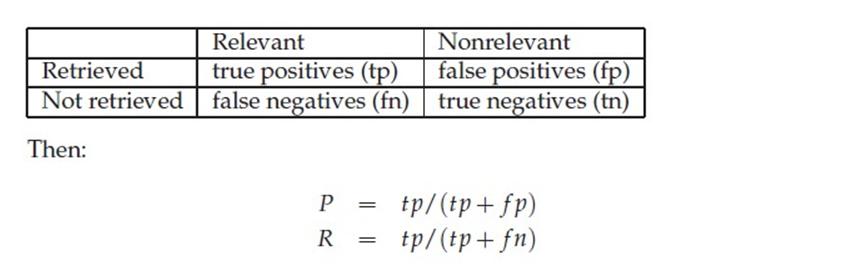
通俗的讲,Precision 就是检索出来的条目中(比如网页)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
下面这张图介绍True Positive,False Negative等常见的概念,P和R也往往和它们联系起来。
阅读全文
摘要:Linear Discriminant Analysis (也有叫做Fisher Linear Discriminant)是一种有监督的(supervised)线性降维算法。与PCA保持数据信息不同,LDA是为了使得降维后的数据点尽可能地容易被区分!
假设原始数据表示为X,(m*n矩阵,m是维度,n是sample的数量)
既然是线性的,那么就是希望找到映射向量a, 使得 a‘X后的数据点能够保持以下两种性质:
1、同类的数据点尽可能的接近(within class)
2、不同类的数据点尽可能的分开(between class)
来看一个例子:两堆点会这样被降维
阅读全文
摘要:机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。
Principal Component Analysis(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
阅读全文

