【APUE】Chapter14 Advanced I/O
14.1 Introduction
这一章介绍的内容主要有nonblocking I/O, record locking, I/O multiplexing, asynchronous I/O, the readv and writev, memory-mapped I/O
这一章是后面章节的基础,也就是说先当成基础记着,在后面的实操应用章节再去体会。
14.2 Nonblocking I/O
"blocking"主要针对slow system call,含义是“the slow system calls are those that can block forever”。
1. 什么情况能出现slow system calls:像read write open ioctl IPC(interprocess communication functions)都可能酝酿出slow system call
2. 书上马上又提了“system calls related to disk I/O are not considered slow”,只要跟I/O相关的,都不算slow。这个slow是跟分配系统CPU资源的速度比起来。
3. 如果nonblocking I/O操作没有成功,则直接返回,并且errno中保存着错误的值。
4. 可以人工把read write这样的操作改成nonblocking的,方法是通过设置file descriptor的flag达成目标
基于上述1、2、3、4,书上给出了下面的例子(我稍加改造):
1 #include "apue.h" 2 #include <errno.h> 3 #include <fcntl.h> 4 5 char buf[500000]; 6 7 int main() 8 { 9 int ntowrite, nwrite; 10 char *ptr; 11 12 ntowrite = read(STDIN_FILENO, buf, sizeof(buf)); 13 fprintf(stderr, "read %d bytes\n", ntowrite); 14 15 set_fl(STDOUT_FILENO, O_NONBLOCK); //set nonblocking 16 17 ptr = buf; 18 while (ntowrite>0) 19 { 20 errno = 0; 21 nwrite = write(STDOUT_FILENO, ptr, ntowrite); 22 fprintf(stderr, "nwrite = %d, errno = %d means %s\n", nwrite, errno, strerror(errno)); 23 24 if (nwrite>0) { 25 ptr += nwrite; 26 ntowrite -= nwrite; 27 } 28 } 29 clr_fl(STDOUT_FILENO, O_NONBLOCK); //clear nonblocking 30 exit(0); 31 }
代码执行结果如下:
1. 输入输出都是regular file

2. 输入是regular file, 输出是terminal(stderr重定向到err文件)

上面这段代码做的事情就是先从stdin读一个500000byte的字符,然后以nonblocking的方式不断写入stdout中。
(1)对于1的情况,输入输出都是regular file的,记得书中说过“disk I/O都算不上slow system call”因此,nonblocking不会有啥影响
(2)对于2的情况,输入虽然是regular file,但是输出变成了terminal;而且在write之前还人为设定成nonblocking的了(即不等着执行完就返回),就造成影响了。可以看到,errno=11,意思是资源暂时不沟通,不能满足你的nonblocking I/O的请求,只能写入一部分数据。
如果不要nonblocking这个flag(屏蔽掉line15和line29),还是执行如下命令:

查看err文件的结果如下:

可以看到,不人为设定nonblocking,则不会出现这种问题。从这个小节可以看出来,书写的还是非常有逻辑的,每个example与之前提到的一些内容都是有关联的。
14.3 Record Locking
这种record locking目的是针对多个process访问同一个文件时候的同步问题。实现record locking有多重方式,书上介绍的是通过fcntl函数来实现的方式。
1. 回顾fcntl函数:
int fcntl(int fd, int cmd, ... /* struct flock *flockptr */)
在record locking这个背景下:
参数fd代表file descriptor,具体关联到这个process打开的某个file
参数cmd决定了操作的模式:
F_GETLK : 判断fd关联的file是否被上锁,如果上锁了flockptr中就存放住锁的信息
F_SETLK : 将flockptr定制的锁,加到fd所关联的file上
F_SETLKW: 与F_SETLK类似,多的一个'W'代表wait,即这是一个blocking函数。如果暂时不能上锁,就sleep等着,直到可以加锁或者这个process收到某个signal
参数flockptr指向一个结构体:
struct flock { short l_type; /*F_RDLCK, F_WRLCK, or F_UNLCK*/ short l_whence; /*SEEK_SET, SEEK_CUR, or SEEK_END*/ off_t l_start; /*offset in bytes, relative to l_whence*/ off_t l_len; /*length, in bytes; 0 means lock to EOF*/ pid_t l_pid; /*returned with F_GETLK*/ }
l_type :代表锁的方式,是读锁,写锁,还是解锁
l_whence:锁作用范围的设定模式,SET,CUR,或END
l_len:锁作用范围的长度
l_start: 锁作用范围的起始位置
l_pid: 如果F_GETLK模式下,没有加锁成功,l_pid返回当前占用这个file的process的id号
这些不同的锁之间互相遵循规则如下:

这些rule作用的条件是:不同的process争夺相同的file的lock权。如果同一个process对lock多次请求,后一次的lock就会顶掉前一次的lock。
并且,要想获得read lock,fd参数必须是以read的模式打开;如果要想获得write lock,fd参数必须是以write的模式打开
2. 一个deadlock的例子
书上给了一段代码,大意是有个file一共2byte。parent process对0 byte加锁,child process对1 byte加锁;等待对方都执行完之后,parent再请求对1 byte的锁,child再请求对0 byte的锁。这样就互相锁住了。代码如下:
1 #include "apue.h" 2 #include <fcntl.h> 3 4 static void lockabyte(const char *name, int fd, off_t offset) 5 { 6 if (writew_lock(fd, offset, SEEK_SET,1)<0) { 7 err_sys("%s: writew_lock error", name); 8 } 9 printf("%s: got the lock, byte %lld\n", name, (long long)offset); 10 } 11 12 int main() 13 { 14 int fd; 15 pid_t pid; 16 17 /*create a file and write two bytes to it*/ 18 fd = creat("tmplock", FILE_MODE); 19 write(fd, "ab",2); 20 21 TELL_WAIT(); 22 if ((pid = fork())<0) { 23 err_sys("fork error"); 24 } 25 else if (pid==0) { 26 lockabyte("child", fd, 0); 27 TELL_PARENT(getppid()); 28 WAIT_PARENT(); 29 lockabyte("parent", fd, 1); 30 } 31 else { 32 lockabyte("parent",fd,1); 33 TELL_CHILD(pid); 34 WAIT_CHILD(); 35 lockabyte("parent", fd, 0); 36 } 37 exit(0); 38 }
代码执行结果如下:

按理说应该出现死锁的,但是系统自动识别了这样可能的死锁情况,并避免了死锁的出现。是哪里避免了死锁的出现呢?
是fcntl函数,它再执行的期间,会检查是否出现死锁的情况。具体man中的解释如下:

函数中writew_lock中调用了fcntl,并且传入的参数正式F_SETLKW(具体可以参考书上P489)
因此,fcntl这个函数在这样的背景下开始检查是否出现deadlock情况。并且,最终选择让其中一个process获得锁的控制权(但是具体让哪个process获得控制权,得看系统实现)
3. lock的在process之间的继承
(1)lock的一侧是process,另一侧是file。当process结束时候,这个process所有加在这个file上的lock都被release了。另一点,当fd关闭了,该process所有加在fd上的lock都关闭了。
见如下两个情况:
情况a.
fd1 = open(pathname,...); read_lock(fd1,..._; fd2 = dup(fd1); close(fd2);
情况b.
fd1 = open(pathname,...); read_lock(fd1, ...); fd2 = open(pathname, ...); close(fd2);
情况a、b的最终结果都是加在pathanme上的lock都随着fd2的close动作而被release了。
(2)lock永远不会跟着fork这样的操作继承到child process中。原因也比较直观,比如parent process对file有个write lock,如果child process也继承了这个wirte lock,逻辑就说不清混乱了。
(3)lock可以随着exec这样的操作继承下来(但是,如果fd的close-on-exec的flag被打开了,lock也不能传下去)。原因也比较直观,因为exec完全取代了当前正在执行的program,但是还沿用之前的pid,因此还要保存调用exec时候的context,这样逻辑上也说的通。
(4)总之,lock是不能在不同的process之间继承,可选择性的在exec这样的场景下执行。
为了更形象的说明问题,书上给了一段代码并配上了一张图:
代码:
fd1 = open(pathname,...); write_lock(fd1, 0, SEEK_SET, 1); /*parent write lock byte 0*/ if ((pid=fork())>0) { fd2 = dup(fd1); fd3 = open(pathname,...); } else if (pid==0) { read_lock(fd1, 1, SEEK_SET, 1); /*child read locks byte 1*/ } pause();
图:

(1)如果parent process中把fd1 fd2 fd3任意关一个,则parent给file加上的wirte lock就被release了。
(2)此时child process中的fd1已经是独立的fd1了,因此加在file上的锁不会随着parent process中fd1 fd2 fd3的关闭而被release。
4. Locks at End of File
在file尾巴上加锁是一个稍微特殊一些的情况
书上给了个例子:
1 writew_lock(fd, 0, SEEK_END, 0); 2 write(fd, buf, 1); 3 un_lock(fd, 0, SEEK_END); 4 write(fd, buf, 1);
1. 把fd关联的file在尾部加锁,意思是从尾巴开始,onwards方向锁上
2. 往file末尾写一个byte
3. 把加在文件尾部的锁解开
4. 再写一个byte
上述操作造成的结果就是,文件倒数第二个byte还是处于被lock的状态,具体如下图:

在自己使用时,一定要注意加锁解锁作用范围的控制,避免这种漏掉一个情况。到时候真是哭都不知道找谁去。
5. Advisory versus Mandatory Locking
这一节与系统file system的具体implementation关系比较紧密,不同系统实现差别还是比较大的。
一开始看的也是云里雾里,直到看到了这篇blog(http://www.thegeekstuff.com/2012/04/linux-file-locking-types/),解答了我很多的疑惑。
下面说一下我个人的理解。
首选需要再思考一个问题:两个不同的process如果都想操作同一个文件(比如,write操作),凭什么保证某一个时刻只有一个process在真正write这个file?
(1)方式一:凭自觉,大家都守一样的规矩(Advisory Locking)
借用“4.lock在process之间集成”中的那张图来说明,最关键的一点,就是凭的就是某个process(假设这个process具有写权限)在真的执行write之前,要先去访问file的v-node中的lockf pointer,看是否有其他的lock正在占用这个file。简单说,就是所有访问某个file的process都守一样的规矩:write之前必须先获得该文件的write lock占有权;而能不能获得占有权,还得去访问lockf pointer指向的lock list,去挨个查看。
上面说的这种方式一中的所有process,对于某个file来说,叫cooperating processes:即,大家都遵守一样的规矩,“虽说都有钥匙(写权限),但是也先排队(请求写锁),再开门(占有写锁)”。
(2)方式二:强制让大家都守规矩 (Mandatory Locking)
方式一只能针对都守规矩的process;如果其他类型的process,有写权限,但是不知道要守这个规矩,直接就执行write操作了,怎么办?那就强制让大家都守规矩,不论哪个process来访问这个file,都得强制去先去访问v-node中的lockf pointer,即“先敲门排队,再开门”。
这种强制守规矩措施分为两个层次:
层次一:在system级别,必须开启这样mandatory locking的功能(让file system这个大管家具备这样的技能)
层次二:在file级别,让system对哪个file采用mandatory locking策略了,需要对这个file特殊处理(即把这个file在system管家那里挂号)
通过这样的方式,就保证了不管是哪个process来访问该file,system都会强迫这个process守规矩,获得相应的锁权才能执行执行相应操作。
个人觉得上面的原理理解是最关键的。再给出一个实操的例子:
(1)我使用的系统信息如下:

(2)首先需要用mount命令(这个命令与挂载文件系统有关,需要root权限),实现层次一system级别的设置:

(3)编辑书上figure14.12的代码如下:
1 #include "apue.h" 2 #include <errno.h> 3 #include <fcntl.h> 4 #include <sys/wait.h> 5 6 int main(int argc, char *argv[]) 7 { 8 int fd; 9 pid_t pid; 10 char buf[5]; 11 struct stat statbuf; 12 13 /*创建一个文件, 往里写几个字符*/ 14 fd = open(argv[1], O_RDWR | O_CREAT | O_TRUNC, FILE_MODE); 15 write(fd, "abcdef", 6); 16 17 /*设置set-group-id的bit位, 关闭group-execute的bit位*/ 18 fstat(fd, &statbuf); 19 fchmod(fd, (statbuf.st_mode & ~S_IXGRP) | S_ISGID); 20 21 /*apue的自定义函数*/ 22 TELL_WAIT(); 23 24 if ((pid = fork())<0) { 25 err_sys("fork error"); 26 } 27 else if (pid>0) { /*父进程 加一个write锁 从头开始加到尾*/ 28 if (write_lock(fd, 0, SEEK_SET, 0)<0) { 29 err_sys("write_lock error"); 30 } 31 TELL_CHILD(pid); /*告知child process执行到这里了*/ 32 if (waitpid(pid, NULL, 0)<0) { 33 err_sys("waipid error"); 34 } 35 } 36 else { 37 WAIT_PARENT(); /*子进程 等着父进程中TELL_CHILD函数发信号 此时父进程已经给这个文件上了一个write lock了*/ 38 set_fl(fd, O_NONBLOCK); /*将fd设为非阻塞的*/ 39 40 if (read_lock(fd, 0, SEEK_SET, 0) != -1) { /*子进程中加read锁 从头加到尾*/ 41 err_sys("child: read_lock succeeded"); 42 } 43 printf("read_lock of already-locked region returns %d means %s\n",errno,strerror(errno)); /*通过errno验证子进程加read锁是否成功*/ 44 if (lseek(fd, 0, SEEK_SET)==-1) { /*将fd移动到beginning的位置*/ 45 err_sys("lseek error"); 46 } 47 if (read(fd, buf, 2)<0) { /*从文件中尝试读俩byte 如果能读成功就证明mandatory locking没用 反之则证明起作用了*/ 48 err_ret("read failed (mandatory locking works)"); 49 } 50 else { 51 printf("read OK (no mandatory locking), buf = %2.2s\n", buf); 52 } 53 } 54 exit(0); 55 }
执行结果如下:
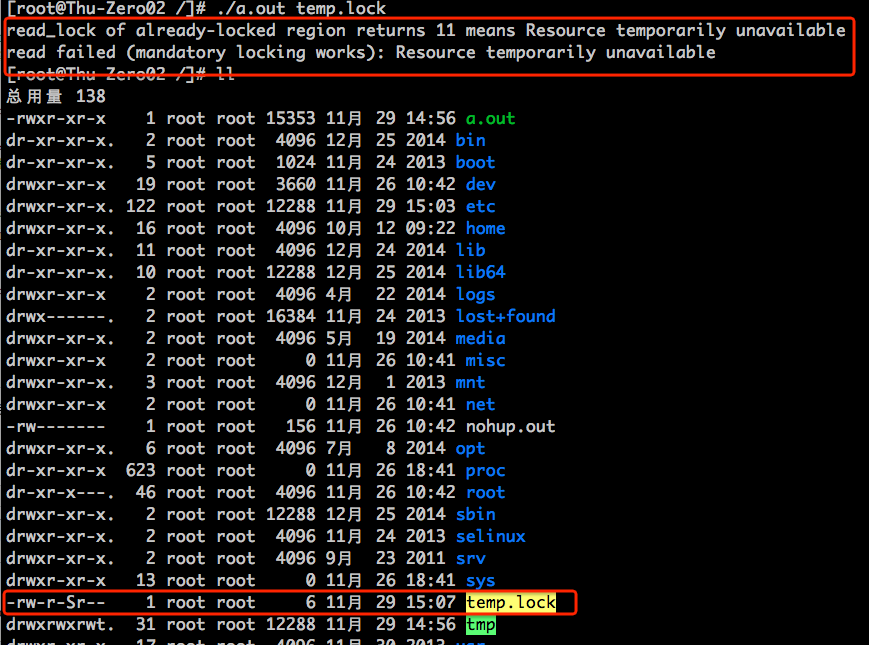
上述带代码是为了检验mandatory locking是否起作用的:
(1)创建一个file, 设置set-group-id bit,关闭group-executable bit,实现层次二file级别的设置
(2)fork
(3)parent process给file加一个写锁,并等着child process执行完的状态;child process一定等着parent process给file加完锁了才往下进行
(4)child process首先将从parent process继承来的file descriptor改成nonblock的,随后尝试给fd加read lock。此时parent process的write lock正占着这个file, child process的read lock是加不上去的。这个属于验证了advisory locking功能的范畴。由于之前fd设定为nonbocking的,因此child process不会一直等着可以获得read lock,而是返回-1(证明没锁成功),并将errno设为11(资源被别人占着呢,得不到锁)
(5)接着child process执行read操作(这属于典型的不守规矩的,没成功获得read lock的权限,还要硬read),结果就是mandatory locking起作用了,没让child process去完成read的操作。
这样,通过上面的例子,就完整理解了了advisory locking和mandatory locking的关系。
如果在系统层面没有mandatory locking的功能,结果是怎样呢?
我回到原先的文件夹下,再执行操作:
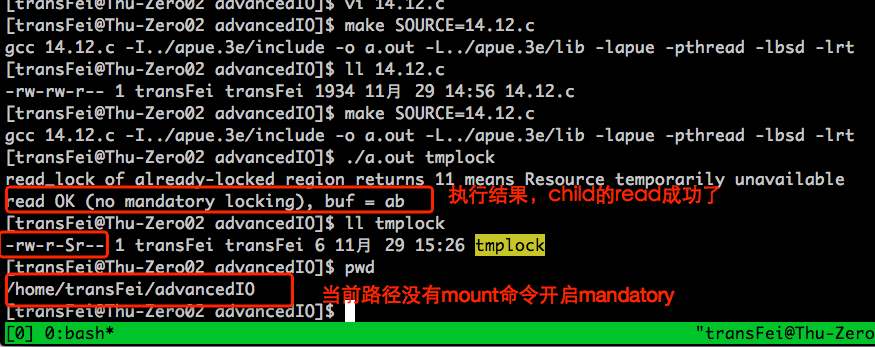
可以发现虽然child process的read lock还是加不上(advisory locking有效),但是却可以不守规矩地越过parent的write lock,直接从tmplock文件中读(mandatory locking失效)。
14.4 I/O Multiplexing
这里主要说,如果一个process中涉及到多个input和多个output,该如何处理。
以telnet command为例说明(P500)
telnet command是user terminal和telnetd daemon的连接节点:即从user terminal读数据,写到telnetd daemon中;又从telnetd daemon读数据,写到user terminal中。因此,telnet command相当于有两个input和两个output。
其实,好几次实际编程中,都遇到过这样的问题,这个I/O Multiplexing说的就是这个问题。
作者的思路非常明确,先列举了几种可能的替代的方案来解决telnet command这个问题。
其他方案一:fork分出parent process和child process;但是parent和child谁先结束谁后结束的问题需要考虑,麻烦。
其他方案二:multi threads多线程,要考虑同步的问题,麻烦。
其他方案三:polling轮询方式,大量的CPU时间浪费了,低效。
其他方案四:asynchoronous I/O异步I/O,可移植性差,signal作用有限
所以,引出来了I/O Multiplexing这个比较好的解决方法。用一个函数来批量的搞定需要处理的各种file descriptors。
1. select函数
int select(int maxfdp1, fd_set *restrict readfds, fd_set *restrict writefds, fd_set *restrict expectfds, struct timeval *restrict tvptr)
按照颜色区分select的三类参数:
(1)tvptr:“specifies how long we want to wait in terms of seconds and microseconds” 具体分为,不等,无限等,有限等三种情况,可以精确到微秒。这里有个情况需要说明,一种是select中管理的fd有ready的了,另一种是等待的tvptr到点儿了,这两种情况select都会返回。
(2)readfds, writefds, exceptfds:这三参数都是指向file description set的指针,有个专门的数据结构就是fd_set。这三参数形式上类似,以readfds为例,指向的fd_set中“one bit per possible descriptor”,一个bit与一个file descriptor相对应。调用select的时候,这三个参数里面各个bits对应的fd正是select函数管理的对象。具体看下图:

既然这三个参数中每个bit关联上一个fd,那么这种关联是咋建立起来的呢?
书上的思路非常连贯,马上给出了如下的函数:
int FD_ISSET(int fd, fd_set *fdset)
int FD_CLR(int fd, fd_set *fdset)
int FD_SET(int fd, fd_set *fdset)
int FD_ZERO(fd_set *fdset)
上面几个函数,望文生义即可。参照下面的用法:
fd_set rset; int fd; FD_ZERO(&rset); FD_SET(STDIN_FILENO, &rset); if (FD_ISSET(fd, &rset)) { ... }
来来来,分析下上面的代码:
(a)清零那个就是清零,类似初始化字符串;虽说把这块内存划给你了,让你随便用,但是之前这上面有什么可不一定,所以要清零
(b)FD_SET(STDIN_FILENO, &rset)这句话有点儿说道。之前不是说一个bit跟fd关联么。这个得回顾一下之前学到的file descriptor的知识,STDIN_FILENO就是0。即,fd_set中监控数值为0的file descriptor,即标准输入。
这里还得多说一句,0、1、2在file descriptor的背景下已经被定死了,就是代表标准输入,标准输出,标准出错输出。也就是说,rset中0、1、2三个位置早就是给stdin stdout stderr留好的了。如果这个时候process中开启了一个新的fd,那么这个fd按照一般的最小递增原则,会被分配成3(详情得回顾FILE IO这章内容);如果想让select管理值为3的fd,就调用FD_SET就OK了。这样就理解了,其实是fd_set的bit与fd的“值”是一一对应的。
这样就带来一个问题了:select通过fd_set来获得需要他去管理的fd的时候,应该是通过遍历bit的方式来查看哪些bit对应的fd需要去管理。从0开始往后遍历,“后”到哪里是头?于是,这就引出了第三个参数。
(3)maxfdp1:“maximum file descriptor plus 1”,其实看完上面的分析,也就知道这个函数的意义了:
类似 for (int bit=0; bit<maxfdp1; bit++),这个maxfdp1就起到这个作用。
只不过,有三个fd_set,maxfdp1的取值要取三个fd_set里面相关的最大的fd值+1。
下面分析select函数的返回值:
(1)-1:出错了
(2)0:表示no descriptors are ready。所有fd_set都清零。
(3)positive value :返回已经ready的fd总数;同一个fd,既有read的ready,又有write的ready,在返回值的时候算两个。并且,这种情况下所有fd_set中只留下ready的bit。
通过上面的分析,可以得出结论,调用一次select只能管一次的fd_set管理。
最后再说,说等着fd_set中的fd状态是ready,这个ready到底是啥意思呢?
(1)对于fd的read和write来说,各自的操作都不被block就算ready了
(2)对于fd的except来说,真的出现异常就算是ready了
2. poll Function
int poll(struct pollfd fdarray[], nfds_t nfds, int timeout)
分析三个参数:
fdarray:
struct pollfd{ int fd; /*file descriptor to check, or < 0 to ignore*/ short events; /*events of interest on fd*/ short revents; /*events that occurred on fd*/ }
fd表示fd;events表示监听fd哪些相关的事件;revents表示fd哪些事件发生了。就OK。
这时候,如果既想监听一个fd的read又想监听该fd的write,就该在fdarray中用两个elements来表示。通过这个体会一下select和poll的参数设计思路,类比数据库设计思路,select更像是列表,而poll更像是用行表。
nfds:类比select的maxfdp1参数
timeout : 类比select的tvptr参数
14.5 Asynchronous I/O
异步IO比较复杂,也有可能各种问题,但是现实中还是有大量其应用的场景。
POSIX标准给了一套异步I/O的使用套路。
1. 介绍了AIO control blocks这样的数据结构,来设定异步I/O的各种属性
struct aiocb{ int aio_fildes; /*file descriptor*/ off_t aio_offest; /*file offset for I/O*/ volatile void *aio_buf; /*buffer for I/O*/ size_t aio_nbytes; /*number of bytes to transfer*/ int aio_reqprio; /*priority*/ struct sigevent aio_sigevent; /*signal information*/ int aio_lio_opcode; /*operation for list I/O*/ };
各种含义都在里面了,有几点书上提醒要注意的:
(1)aio_reqprio这种优先级只是建议性的,并不是强制性的;最终谁排前面后面,主要由系统算法决定
(2)sigevent是一个结构体,负责处理异步I/O执行完后做哪些动作,其具体定义如下:
struct sigevent{ int sigev_notify; /*notify type*/ int sigev_signo; /*signal number*/ union sigval sigev_value; /*notify argument*/ void (*sigev_notify_function) (union signal); /* notify funciton*/ ptrhead_attr_t *sigev_notify_attributes; /* notify attrs*/ };
主要根据sigev_notify,分为三种处理方式:
a. SIGEV_NONE : 啥都不干
b. SIGEV_SIGNAL :产生sigev_signo信号,并且把sigev_value传给设定的signal handler函数
c. SIGEV_THREAD:用detached thread的方式去处理signal
2. aio_read aio_write 异步读写函数
int aio_read(struct aiocb *aiocb);
int aio_write(struct aiocb *aiocb);
就是异步读写,提交上去就OK了,不用阻塞等着。
注意,参数传入的是指向aiocb的一个结构体指针。在异步IO操作的过程中,要保证传入的aiocb的结构体不能被改动了,因为异步IO操作会一直用到这个结构体的内容;直到异步IO执行完成了,才允许修改。异步IO如何判断执行完成了,下面会说。
3. aio_error 和 aio_return 函数
int aio_error(const struct aiocb *aiocb);
int aio_return(const struct aiocb *aiocb);
这俩函数搭伙使用 判断异步IO执行到啥状态了。
(1)aio_error函数的四个返回值 {0, -1, EINPROGRESS, else}表示不同的状态(P513有具体的解释)
(2)aio_return函数根据aiocb对应的write read fsync不同操作,返回相应的结果(比如write,就返回写入了多少个byte)
关于aio_return有两点要注意:
a. 慎用这个函数,一旦用了这个函数,传入的aiocb参数占用的memory就可以被操作系统拿去干其他的事情了
b. aio_return返回成功了,也不意味着内容持久化到磁盘上了,只能说明任务都成功提交到queue中了
这俩函数针对一个异步IO的状态的。实际中很可能一堆aio等着去判断状态,就可以用下面的函数。
4. aig_suspend函数
int aio_suspend(const struct aiocb *const list[], int nent, const struct timespec *timeout)
这个函数应用的场景就是:有一堆异步IO都在执行中,如果有其中有一个异步IO完成了,就需要进行响应处理。
这是一个阻塞函数,三种情况可以让这个函数解除阻塞:
(1)调用这个函数所在的process被signal打断了
(2)超时了,此时errno被设置为EAGAIN
(3)any of aio完成了
5. aio_fsync函数
int aio_fsync(int op, struct aiocb *aiocb)
这是一个全局催促函数,也是个阻塞函数:
(1)op标示催促行为类型:可以设为{O_DSYNC, O_SYNC},含义分别是{催数据部分完成,催全部完成}
(2)aiocb标示催哪个aio
下面还有两个函数(书上给的代码例子中没有涉及,但是还是记一下看过的内容)
6. aio_cancel函数
int aio_cancel(int fd, struct aiocb *aiocb)
作用是取消对fd的异步操作aiocb。这个函数也不是强制性的,只能是尝试取消,最后能不能取消成功,结果不一定。
7. lio_listio函数
int lio_listio(int mode, struct aiocb *restrict const list[restrict], int nent, struct sigevent *restrict sigev)
函数的作用是提交多个异步io请求。
(1)mode : 是否需要异步,取值{LIO_WAIT, LIO_NOWAIT}。这里我的理解是,这个lio_listio本身可以是通过mode来设定是需要阻塞,等着里面的aio有结果了,还是不需要等着,提交上去就完事儿了。但是list参数中的io必须是aio。
(2)lsit : 需要提交的aio集合,这时候每个aio中的aio_lio_opcode属性就起作用了,意思是告诉list,我这个aio个体是读、写还是其他的。为什么在list中要告诉,而在单独使用时候,这个属性就没用了呢?因为在单独使用的时候,是通过aio_read aio_write aio_fsync这样具体的函数执行的,意义自然就明确了
(3)sigev:当list中所有的aio都完成了,就会发出一个sigev信号
这一部分给出了一个比较综合的例子:用同步IO和异步IO分别实现文件copy的功能,并在copy的同时把每个字符做一个变换
代码1:
1 #include "apue.h" 2 #include <ctype.h> 3 #include <fcntl.h> 4 5 #define BSZ 4096 6 7 unsigned char buf[BSZ]; 8 9 unsigned char translate(unsigned char c) 10 { 11 if (isalpha(c)) { 12 if (c>='n') { 13 c -= 13; 14 } 15 else if (c>='a') { 16 c += 13; 17 } 18 else if (c>='w') { 19 c -= 13; 20 } 21 else { 22 c += 13; 23 } 24 } 25 return(c); 26 } 27 28 int main(int argc, char *argv[]) 29 { 30 int ifd, ofd, i, n, nw; 31 if (argc != 3) { 32 err_quit("usage: rot13 infile outfile"); 33 } 34 if ((ifd = open(argv[1], O_RDONLY))<0) { 35 err_sys("can't open %s", argv[1]); 36 } 37 if ((ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE))<0) { 38 err_sys("can't create %s", argv[2]); 39 } 40 while ((n = read(ifd, buf, BSZ))>0) { 41 for ( i=0; i<n; i++) 42 buf[i] = translate(buf[i]); 43 if ((nw = write(ofd, buf, n))!=n) { 44 if (nw <0) { 45 err_sys("write failed"); 46 } 47 else { 48 err_quit("short write (%d/%d)", nw ,n); 49 } 50 } 51 } 52 fsync(ofd); 53 exit(0); 54 }
代码2:
1 #include "apue.h" 2 #include <ctype.h> 3 #include <fcntl.h> 4 #include <aio.h> 5 #include <errno.h> 6 7 #define BSZ 32768 8 #define NBUF 8 9 10 enum rwop{ 11 UNUSED = 0, 12 READ_PENDING = 1, 13 WRITE_PENDING = 2 14 }; 15 16 struct buf{ 17 enum rwop op; 18 int last; 19 struct aiocb aiocb; 20 unsigned char data[BSZ]; 21 }; 22 23 struct buf bufs[BSZ]; 24 25 26 unsigned char translate(unsigned char c) 27 { 28 if (isalpha(c)) { 29 if (c>='n') { 30 c -= 13; 31 } 32 else if (c>='a') { 33 c += 13; 34 } 35 else if (c>='w') { 36 c -= 13; 37 } 38 else { 39 c += 13; 40 } 41 } 42 return(c); 43 } 44 45 int main(int argc, char *argv[]) 46 { 47 int ifd, ofd, i, j, n, err, numop; 48 struct stat sbuf; 49 const struct aiocb *aiolist[NBUF]; 50 off_t off = 0; /*用于标示input文件读到哪里了*/ 51 52 ifd = open(argv[1], O_RDONLY); 53 ofd = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE); 54 fstat(ifd, &sbuf); /*获得要读取文件的信息*/ 55 56 /*初始化buffers*/ 57 for ( i=0; i<NBUF; i++) 58 { 59 bufs[i].op = UNUSED; /*标志该buf是否被用上了*/ 60 bufs[i].aiocb.aio_buf = bufs[i].data; /*给aio指定一个buf空间*/ 61 bufs[i].aiocb.aio_sigevent.sigev_notify = SIGEV_NONE; /*不响应signal*/ 62 aiolist[i] = NULL; /*aiolist清空*/ 63 } 64 65 numop = 0; 66 while (1) 67 { 68 for (i=0; i<NBUF; i++) /*遍历各个bufs*/ 69 { 70 switch(bufs[i].op) 71 { 72 case UNUSED: /*这个buf目前没被使用*/ 73 if (off<sbuf.st_size) { /*文件还有内容没有读完*/ 74 bufs[i].op = READ_PENDING; /*进行状态转换*/ 75 bufs[i].aiocb.aio_fildes = ifd; /*将第i个buf的file descriptor与ifd关联上*/ 76 bufs[i].aiocb.aio_offset = off; /*将第i个buf的偏移量设置为off*/ 77 off += BSZ; /*由于buf一次读BSZ这么多byte, 所以在这里将off向后移动BSZ个位置*/ 78 if (off >= sbuf.st_size) { /*如果读完了这次之后 已经读完了*/ 79 bufs[i].last = 1; /*猜测这个last就是标示执行完最后一次read的动作*/ 80 } 81 bufs[i].aiocb.aio_nbytes = BSZ; /*告诉aiocb就是读了BSZ这么多字符*/ 82 if (aio_read(&bufs[i].aiocb)<0) { /**这一步真正执行了异步的read操作**/ 83 err_sys("aio_read faile"); 84 } 85 aiolist[i] = &bufs[i].aiocb; /*告诉第i个buf用上了, 并且是什么也告诉了*/ 86 numop++; /*正在执行任务的op数量加1*/ 87 } 88 break; 89 case READ_PENDING: /*这个buf正读着呢*/ 90 if ((err = aio_error(&bufs[i].aiocb))==EINPROGRESS) { /*获取异步read的执行状态 如果正读一半呢, 则继续往下读*/ 91 continue; 92 } 93 if (err!=0) { /*异步read没执行成功的情况*/ 94 if (err==-1) { /*aio_error执行失败了*/ 95 err_sys("aio_error failed"); 96 } 97 else { /*异步read操作失败了*/ 98 err_exit(err, "read failed"); 99 } 100 } 101 if ((n=aio_return(&bufs[i].aiocb))<0) { /*能执行到这 说明异步read可能执行成功了 最起码执行完了 所以在这里用aio_return函数来看一下读进来多少个字符*/ 102 err_sys("aio_return failed"); 103 } 104 if (n!=BSZ && !bufs[i].last ) { /*没读满BSZ 还不是最后一个 必然是读的过程中读少了 出问题了*/ 105 err_quit("short read (%d/%d)", n ,BSZ); /*没读全 到底读了多少*/ 106 } 107 /*能执行到这里 证明已经顺利读进来了 而且读全了*/ 108 for (j=0; j<n; j++) /*执行字符转换*/ 109 bufs[i].data[j] = translate(bufs[i].data[j]); 110 bufs[i].op = WRITE_PENDING; /*进行角色转换 读 和 转换 都已经完成了 该写了*/ 111 bufs[i].aiocb.aio_fildes = ofd; /*fd换成输出文件的*/ 112 bufs[i].aiocb.aio_nbytes = n; 113 if (aio_write(&bufs[i].aiocb)<0) { /**执行异步write操作**/ 114 err_sys("aio_write failed"); 115 } 116 break; 117 case WRITE_PENDING: /*如果buf正在写状态*/ 118 if ((err = aio_error(&bufs[i].aiocb)) == EINPROGRESS) { /*没写完呢 等着*/ 119 continue; 120 } 121 if (err!=0) { 122 if (err == -1) { /*aio_return本身执行失败*/ 123 err_sys("aio_error failed"); 124 } 125 else { /*aio_return本身执行成功 但aio_write执行失败*/ 126 err_exit(err, "write failed"); 127 } 128 } 129 if ((n=aio_return(&bufs[i].aiocb))<0) { /*异步write可能执行成功 查看写入了多少byte*/ 130 err_sys("aio_return failed"); 131 } 132 if (n!=bufs[i].aiocb.aio_nbytes) { /*如果写入byte不等于原来读进来的bytes数*/ 133 err_quit("short write (%d/%d)", n, BSZ); /*看到底写了百分之多少*/ 134 } 135 aiolist[i] = NULL; /*现在aiolist[i]这个buf已经完成了他的一次读写操作 被制空*/ 136 bufs[i].op = UNUSED; /*执行状态转换 完成读和写的操作之后 又可以让这个bufs变成可用的*/ 137 numop--; /*少了一个正在执行任务的op*/ 138 break; 139 } 140 } 141 if (numop == 0) { /*没有正在执行读写任务的op了*/ 142 if (off >= sbuf.st_size) { /*已经完成全部读的任务了 可以退出while循环了*/ 143 break; 144 } 145 } 146 else { /*等着至少一个op执行完再往下进行 s这样做的策略是: suspend是不耗费cpu的 一旦suspend有结果了 就可以保证上面的for循环至少能命中一个改变状态的op 减少了无谓的占用cpu的轮询次数*/ 147 if (aio_suspend(aiolist, NBUF, NULL)<0) { 148 err_sys("aio_suspend failed"); 149 } 150 } 151 } 152 bufs[0].aiocb.aio_fildes = ofd; /*这个时候所有的bufs都是可用的 只不过挑第0个buf用一下*/ 153 if (aio_fsync(O_SYNC, &bufs[0].aiocb)<0) { /*催促一下所有正在往ofd中异步write操作字符都写进去*/ 154 err_sys("aio_fsync failed"); 155 } 156 exit(0); 157 }
两份代码的执行结果如下(首先执行代码1 再执行代码2)

上述的同步IO代码思路比较简单;异步IO的代码用了“有限状态机”的设计思路(以后再体会)。
同步IO是一个buffer,一套read和write;异步IO用了8个buffer,八套read和write。
我测试用的文件是500M的文件,上面代码的意义在于体会异步IO的设计思路:复杂但是一些情况可能会好用,先学着。
14.6 readv & writev函数
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
ssize_t writev(int fd, const struct iovec *iov, int iovcnt);
集成化的read和write。
书上给了这样的例子:一堆文件,一堆buffer,往一个地方写,怎么写?
主要考虑两种情况:
(1)把数据都copy到一个buffer里面,尽量少的调用write
这种情况主要耗时的地方是copy数据,好处是少调用system call(write)
(2)把各个buffer的信息都推到writev里面,一起提交
这种情况的主要耗时的地方是要多一些system call(write),好处是少一些copy
copy 和 system call 这二者之间的tradeoff决定哪种方式的效率高。
14.7 readn & writen 函数
这俩函数是apue自定义的函数,主要功能是:读一次不行就自动多读几次,直到读完为止。后面chapter 20.8会用到。
14.8 Memory-Mapped I/O
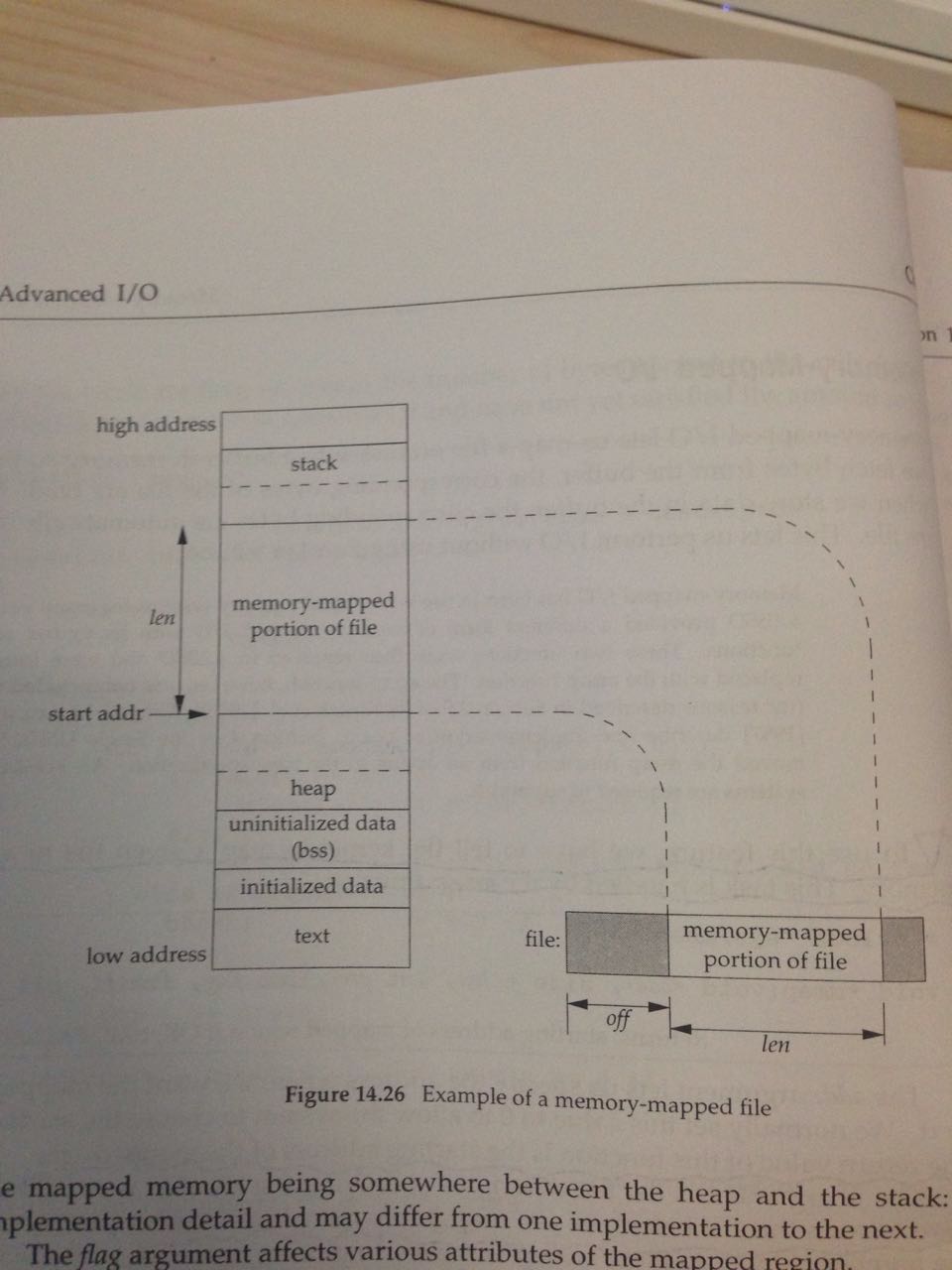
void *mmap(void *addr, size_t len, int prot, int flag, int fd, off_t off)
把磁盘文件与一段内存buffer关联起来,目的是可以让系统把对buffer的操作转换为对磁盘文件的操作。
参数的含义:
addr:内存中的地址,用于map的起点。如果设成0,则由系统来分配;如果不是0,好像不太好办。
len :划出来多长的byte用于memory-mapped IO
fd:跟哪个磁盘文件关联(这个fd对应的磁盘文件必须是open的)
prot:能对内存中留出来map的那块区域的操作权限{PROT_READ, PROT_WRITE, PROT_EXEC, PROT_NONE}
off:需要映射的磁盘文件的offset位置,即从哪开始的
flag:设定memory与磁盘文件的关联模式 {MAP_FIXED, MAX_SHARED, MAX_PRIVATE},即对memory的操作怎么作用于磁盘文件上
这里还有一个地方需要注意的,addr和off一般都是system's virtual memory page size的整数倍。这个不太好理解,书上给了一个例子:比如disk file的大小是12bytes,而system's page size是512bytes;则一般来说,系统会给分配一个512bytes的mapped region,只不过后500bytes都是0;一旦我们作死去修改后面500bytes的内容,无论怎么作死,mapped region的改变都不会关联到disk file上。
再看一张整体的示意图,加深印象:
另外,有两个signal与mmap关系比较紧密:
SIGSEGV 和 SIGBUS
先单独说一下这两个signal的含义:
(1)SIGSEGV:指针对应的地址无效,即没有物理内存对应,也无法访问,触发signal
(2)SIGBUS:指针对应的地址有效,即物理内存存在,但是由于数据格式没有对齐,触发signal
书上只说了SIGBUS什么情况会出现:
比如,我们之前map了一个disk file,结果这个disk file的内容被其他process给truncate了;这个时候,我们再去访问memory-mapped region中被truncate掉的那个部分,就会触发SIGBUS信号。后面的示例代码中,我自己增加了这个部分。
还有一个函数:
int munmap(void *addr, size_t len)
作用就是解除memory-mapped region与disk file的关系。第一个参数addr就是mmap函数返回的;第二个就是要接触关联的长度。
下面看一个综合例子,这个例子功能就是把利用memory-mapped I/O技术实现了文件拷贝。
1 #include "apue.h" 2 #include <fcntl.h> 3 #include <sys/mman.h> 4 #include <signal.h> 5 6 #define COPYINCR (1024*1024*1024) /*1 GB*/ 7 8 void sig_bus(int signo) 9 { 10 printf("catch SIGBUS signal\n"); 11 fflush(stdin); 12 return; 13 } 14 15 int main(int argc, char *argv[]) 16 { 17 int fdin, fdout; 18 void *src, *dst; 19 size_t copysz; 20 struct stat sbuf; 21 off_t fsz = 0; 22 signal(SIGBUS, sig_bus); 23 //signal(SIGSEGV, sig_segv); 24 25 fdin = open(argv[1], O_RDONLY); 26 fdout = open(argv[2], O_RDWR|O_CREAT|O_TRUNC, FILE_MODE); 27 fstat(fdin, &sbuf); 28 //ftruncate(fdout, sbuf.st_size); /*设定output file 与input file长度一样*/ 29 30 /*通过内存映射的方法 来完成两个大文件的copy*/ 31 while (fsz<sbuf.st_size) { 32 if ((sbuf.st_size - fsz)>COPYINCR) { /*最多控制在1GB*/ 33 copysz = COPYINCR; 34 } else { 35 copysz = sbuf.st_size - fsz; /*不足1GB 就把input文件剩下的都囊括进来*/ 36 } 37 if ((src = mmap(0, copysz, PROT_READ, MAP_SHARED, fdin, fsz))==MAP_FAILED) { /*把input文件给映射进去*/ 38 err_sys("mmap error for input"); 39 } 40 if ((dst = mmap(0, copysz, PROT_READ|PROT_WRITE, MAP_SHARED, fdout, fsz)) == MAP_FAILED) { /*把output文件给映射出去*/ 41 err_sys("mmap error for output"); 42 } 43 memcpy(dst, src, copysz); /*内存拷贝*/ 44 munmap(src, copysz); /*解除input文件与内存的关联*/ 45 munmap(dst, copysz); /*解除output文件与内存的关联*/ 46 fsz += copysz; 47 } 48 exit(0); 49 }
代码执行结果如下:
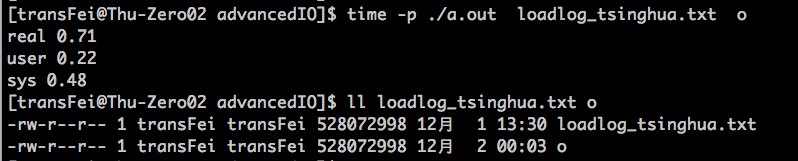
我们再用系统cp命令执行一遍:

之前还提到过,某种情况下SIGBUS信号可能被出发。现在人为屏蔽掉line28的truncate语句,执行结果如下:

由于o是个新文件长度是0,如果不用truncate命令让o与loadlog_tsinghua.txt的文件长度一样,则执行line40的时候就符合出发SIGBUS的条件了。
至于实现disk file copy的方式,比较如下两种情况:
(1)read & write:主要耗时在copy & system call上面
(2)mmap & memcpy:主要耗时在page fault handling上面
哪种方法比较好,需要在两种耗时操作上tradeoff,获得合适的结果。
另,(2)还两个不足:不能处理network和terminal的情况;不能在执行过程中改变文件大小,要不然就SIGBUS或者SIGSEGV信号触发了。
这个memory-mapped I/O在15.9中会继续提到。
14.9 Summary
这章的内容主要是为后续章节做铺垫了:Nonblocking I/O, Record locking, I/O Multiplexing,Asynchronous I/O, readv & writev, Memory-mapped I/O
这章的内容中有阻塞与非阻塞、同步与异步,总结一下:
Nonblocking I/O是说再执行read和write的时候,通过在flag中设置O_NONBLOCKING,不等着真的read或write结束,就直接返回了。(书上P483的figure14.1就是例子)
Asynchronous I/O是说每个同一个process可以异步执行多个I/O,多input多output(书上P500的figure14.13就是例子)。
二者总结起来,就是“能说阻塞和非阻塞的,都是同步IO;只有特殊的IO,比如aio才是异步IO”
哪天糊涂了再去直呼上这个帖子上看看:http://www.zhihu.com/question/19732473


 浙公网安备 33010602011771号
浙公网安备 33010602011771号